EfficientNet 논문 리뷰입니다.
본 논문은 2019년도에 등장한 논문입니다.

논문 : EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
저자 : Mingxing Tan, Quoc V. Le
[1] Background
전통적으로 CNN 모델의 성능을 높이기 위해서는 모델 규모를 키우는 것이 일반적인 방법입니다.
예를 들어, ResNet은 Layer의 개수를 늘려서 ResNet-18 에서 ResNet-200 까지도 증가시킬 수 있고, GPipe는 기본 모델을 4배 확장하여 ImageNet 데이터셋에서 top1 정확도 84.3%를 달성하기도 했다고 하네요.
이렇게 CNN 모델의 규모를 키우는 방법은 여러 가지가 있지만, 어떤 방식이 가장 효과적인지 정립된 이론은 없습니다.

CNN 모델을 키우는 대표적인 방법은
1) Layer를 더 쌓아서 깊이를 깊게 만들기
2) 채널 수를 증가시켜 너비를 넓게 만들기
3) 입력 이미지 크기를 키우기 (해상도를 키우는 방식)
지금까지의 연구는 이렇게 CNN을 확장할 때 깊이, 너비, 이미지 크기 중 하나만 키우는 방식을 사용했습니다.
깊이, 너비, 이미지 크기의 모든 요소를 한꺼번에 키울 수 있지만 이 경우 튜닝이 어려워지고 최적의 성능과 효율성을 보장하지 못하는 경우가 많습니다.
따라서, 본 논문 EfficientNet에서는 CNN을 효과적으로 키울 수 있는 체계적인 방법이 있는지 연구하고
실험 결과 단순히 CNN의 모든 요소를 일정한 비율로 조정하는 것만으로도 효과적으로 성능을 향상시킬 수 있음을 발견했습니다.
[2] Related Work
1) ImageNet

본 논문에서 ImageNet 을 계속 언급하길래 ImageNet과 관련 모델들 살짝 보고 가겠습니다.
ImageNet 은 대규모 이미지 데이터베이스로, 기본적으로 Classification, 이미지 분류 Task를 다루고 있으며 2010년부터 매년 대회를 개최하고 있다고 합니다.
ImageNet에서 잘 동작하는 모델은 다양한 전이 학습 데이터셋에서도 좋은 성능을 보이며, 객체 탐지 등 다른 CV Task에서도 좋은 성능을 보이는 경향이 있습니다.
2012년에는 AlexNet / 2014년에는 GoogleNet / 2017년에는 SENet이 우승했고
GPipe 모델은 2018년도에 5억 개 이상의 파라미터를 사용해 84.3%까지 달성했다고 합니다. (그러나, GPipe 모델은 너무 무겁고 크기 때문에 파이프라인 병렬 처리라는 특수한 병렬처리 기법 없이는 학습하기 어렵다고는 하네요)
→ 단순히 모델을 키우는 것만으로는 하드웨어 메모리 한계가 있기 때문에 정확도를 더 높이기 위해서는 효율적인 모델이 필요하다고 주장합니다.
2) ConvNet Efficiency
깊은 CNN 모델들은 종종 과도한 파라미터를 가지기 때문에 비효율적인 경우가 많습니다.
그래서 모델 압축 등의 방법을 사용하면 정확도를 조금 낮추는 대신 더 작은 모델로 만들 수 있습니다.
그 예시로 SqueezeNet, MobileNet 등이 있고
이 논문 등장 당시에는 AI가 효율적인 모바일 CNN 모델을 설계하는 NAS 기법이 주목받았다고 합니다.

💡What is NAS(Neural Architecture Search)?
- 의미 : 딥러닝 모델의 최적 네트워크 구조를 자동으로 탐색해주는 방법
- 구성
- 탐색 공간 : conv 개수, 필터 크기, 채널 수 등 네트워크 구조 조합을 정의
- 탐색 전략 : 무작위 탐색, 강화학습 등 네트워크 구조를 탐색하는 방법을 결정
- 성능 평가 : 탐색된 네트워크 구조의 성능을 평가하는 과정
[3] Compound Model Scaling
1) Problem Formulation
그래서 EfficientNet 에서 모델을 어떻게 효율적으로 확장시킬지에 대한 문제를 공식화합니다.

일반적으로 CNN 구조는 위 사진처럼 여러 층으로 구성되며 각 층에서 순차적으로 연산을 수행하는 구조를 가집니다.
그리고 여러 층으로 구성된 Stage로 나뉘며 같은 스테이지에 있는 층들은 같은 연산 구조를 가지는 특징이 있다고 합니다.
CNN의 한 Layer는 입력 $X$ 를 받아서 연산 $F$ 를 수행한 뒤, 출력 $Y$ 를 만듭니다. → $Y = F(X)$
여기서 $X$ 는 입력 텐서이며 텐서 $X$는 $(H, W, C)$ 로 구성됩니다.
따라서 CNN 모델 $N$ 은 다음과 같이 정의할 수 있습니다 :

또한, CNN 모델은 일반적으로 이미지 크기는 줄어들고 채널 수가 증가하는 형태를 가집니다.
예를 들어 224 x 224 x 3 이미지가 입력되었을 때 마지막 층에서는 7 x 7 x 512 Feature Map으로 되는것처럼요.
기존의 CNN 모델들은 최적의 레이어 구조 $F$ 를 찾는 데 집중했다면
EfficientNet에서는 $F$ 를 변경하지 않고 나머지 구조인 깊이($L$), 너비($C$), 해상도($H, W$)를 조절하는 방법을 연구합니다.
2) Scaling Dimensions
최적의 깊이, 너비, 해상도를 찾을 때 이 값들은 서로 영향을 주며, 자원이 제한되어 있기 때문에 단순하게 조절하기 어렵습니다.
그래서 지금까지의 CNN 모델들이 깊이, 너비, 해상도 중 하나씩만 변경하는 방식으로 확장을 해왔던 거구요.

가장 일반적으로 모델을 확장하는 방법은 깊이를 깊게 만드는 방식이라고 합니다.
왜? 모델이 깊어지면 더 많은 패턴을 학습할 수 있고, 일반화 성능도 향상되기 때문에
But, 너무 깊은 모델은 기울기 소실 문제 때문에 학습이 어려워지는 경우도 더러 존재해 적당히 키워야겠죠.

MobileNet, WideResNet 같은 소형 모델들은 너비를 확장하는, 채널 수를 늘리는 방식을 사용했습니다.
왜? 채널을 늘리면 더 미세한 특징을 학습할 수 있으며 풍부한 정보를 학습하기에 학습이 안정적이며 빠르게 수렴합니다.
But, 너비만 늘린다면 저차원 특징만 잘 학습하고 고차원 특징은 학습하기가 어려울 수 있습니다. (네트워크가 얕으면 더 많은 특징을 학습할 뿐이지 전체적인 구조, 복잡한 특징 등 파악하는 능력은 부족해질 수 있)
깊이, 너비와 마찬가지로 이미지 크기(해상도)도 증가시키면 더 많은 정보를 학습할 수 있습니다.
초기 CNN 모델들은 대부분 224 x 224 로 학습시켰지만
229 x 229, 331 x 331, 심지어 객체 탐지 모델에서는 600 x 600 이상 사용하는 경우가 많다고 합니다.
그래서 위의 실험을 통해 첫 번째 중요한 관찰 결과를 도출했습니다.
➡️ CNN 모델의 너비, 깊이, 해상도를 확장하면 정확도가 향상되지만 어느 순간부터 성능 향상이 둔화된다.

3) Compound Scaling
다른 구조는 동일한데 입력되는 이미지만 커지면 receptive field가 작아집니다.
그래서 이미지 크기를 키우면 모델의 깊이도 깊어져야 합니다.
마찬가지로, 입력되는 이미지가 커진다면 더 많은 픽셀을 처리해야 하므로 세밀한 패턴을 학습하려면 너비도 늘려야 합니다.
이러한 가설을 검증하기 위해 깊이, 너비, 해상도를 함께 조절하는 게 효과적인지 실험했습니다.

위처럼 깊이와 해상도가 다른 4개의 모델 구성에서 너비 (채널) 만 변경했을 때 성능 비교를 했다고 합니다.
- 너비만 늘릴 경우(파란 선) : 깊이와 해상도를 1로 고정한 상태에서 너비만 늘리면 정확도 향상이 빠르게 한계에 도달함
- 깊이와 해상도를 늘릴 경우 (빨간 선) : 깊이와 해상도를 증가시키면 너비만 늘리는 것보다 성능이 훨씬 더 좋아짐
위의 실험을 통해 두 번째 중요한 관찰 결과를 도출했습니다.
➡️ CNN 모델을 확장할 때 모든 요소를 균형있게 조절하는 것이 성능과 효율성을 높이는 핵심 요소이다.
그래서 본 논문에서는 $ϕ$ 라는 단일 계수를 사용해 깊이, 너비, 해상도를 자동으로 조절하는 방법을 제안합니다.
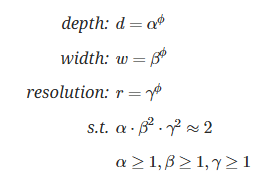
- Depth (깊이) : $d = α^ϕ$
- Width (너비) : $w = β ^ϕ$
- Resolution (해상도) : $r = γ^ϕ$
따라서, 위의 3 요소를 짬뽕시켜서 네트워크를 확장할 때 FLOPS (연산량) 증가량을 $2^ϕ$ 배로 유지하도록 조절한다고 합니다.
[4] Model Architecture
위에서 언급했듯이 EfficientNet 에서는 모델을 확장하는 방법론 자체만 제시하기 때문에
이를 적절하게 활용하려면 처음부터 좋은 Base Model 을 선택하는 것이 중요합니다.

그래서 기존 CNN 모델을 사용해 평가도 하겠지만, 자체적으로 EfficientNet-B0를 개발해 실험했다고 합니다.
개발은 정확도와 연산량을 동시에 최적화하는 NAS를 활용했고
특정 하드웨어에 맞추지 않고 연산량을 기준으로 최적화했다고 합니다.
EfficientNet-B0는 MBConv 블록을 사용하고 SE 기법으로 성능을 더욱 향상시켰습니다.
💡 MBConv란?
MBConv는 기본 Conv와 비교했을 때, 연산량을 줄이면서도 성능을 유지하기 위한 여러 Layer가 추가된 Conv 입니다.
1) 기본 Conv 연산 과정
- Conv Layer : 입력된 Feature Map에서 Conv 연산(일반적으로 3x3, 5x5 Filter)을 통해 중요한 특징을 추출
- 활성화 함수 적용 : 합성곱 연산 후 비선형 활성화 함수 적용
- Pooling 연산 적용
2) MBConv 연산 과정
- Expansion Layer (1x1 convolution) : 확장 계수를 곱해 입력 채널 수를 확장 (이후 Depthwise에서 연산량을 줄이는데 표현력이 감소할 수 있어 필요)
- Depthwise Conv Layer : 일반 Conv에서는 모든 채널을 한번에 처리하지만 Depthwise 에서는 각 채널을 독립적으로 처리 (연산량이 크게 줄어들며, 공간적인 특징을 효율적으로 학습 가능)
- SE Block (선택적) : 각 채널의 평균값을 구한 뒤 FC Layer + Sigmoid를 거쳐 채널별 중요도를 계산 (이 값이 Depthwise 결과값에 곱해져서 중요한 채널을 강조하는 역할을 함)
- Projection Layer (1x1 convolution) : 확장 Layer에서 늘렸던 채널 수를 다시 줄이는 과정 (채널 수를 확장한 채로 유지하면 연산량이 너무 커지므로)
- Skip Connection : 잔차 연결을 사용해 모델 학습을 더욱 안정적으로 수행
→ 이 MBConv는 MobileNet v2, MnasNet을 참고해 NAS가 알아서 작성한 모듈이라고 합니다. (AI 만만세네요)
EfficientNet-B0 기준으로 $ϕ = 1$ 라고 가정하고, 최적의 $ α, β, γ $ 값을 찾기 위해 Grid Search를 수행했습니다.
실험 결과, 최적의 계수는 다음과 같았습니다 :
- 깊이 : $α = 1.2$
- 너비 : $β = 1.1$
- 해상도 : $γ = 1.15$
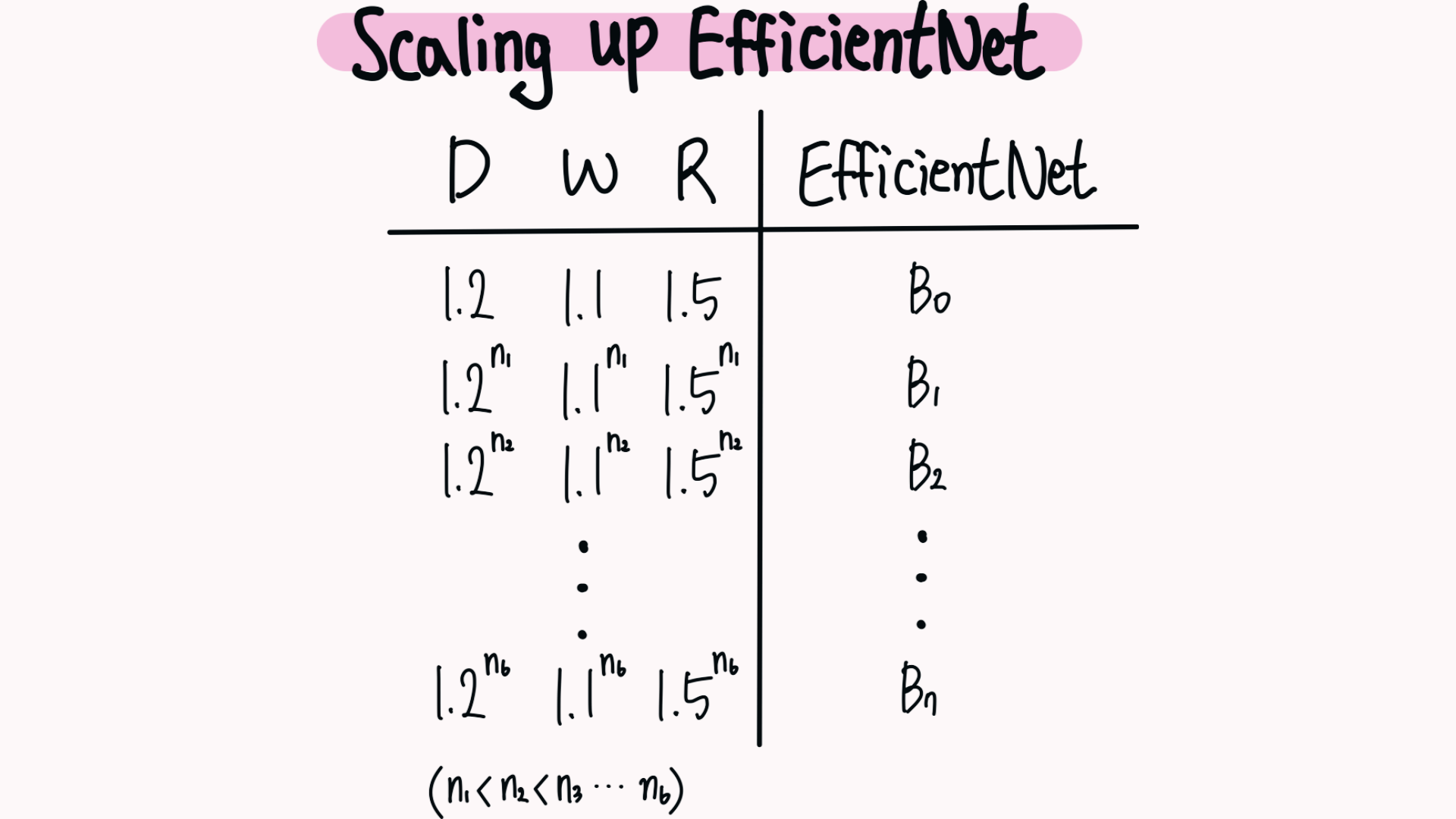
→ 이후 $ α, β, γ $ 를 고정하고 다양한 $ϕ$ 값을 사용해 EfficientNet-B1 부터 B7까지 확장했습니다.
[5] Experiments
1) EfficientNet Performance Results on ImageNet

첫 번째 실험은 비슷한 정확도를 가진 모델끼리 묶어서 EfficientNet의 성능, 파라미터, 연산량을 비교하는 실험입니다.
표의 내용은 다음과 같습니다 :
- #Params : 모델의 파라미터 수
- Ratio-to-EfficientNet : EfficientNet과 비교한 파라미터 증가율
- #FLOPs : 모델의 연산량
- Ratio-to-EfficientNet : EfficientNet과 비교한 연산량 증가율
☑️실험 결과, EfficientNet 모델들은 기존 CNN 모델에 비해 파라미터 수와 연산량을 많이 줄이면서도 일관되게 높은 성능을 보였습니다.
2) Compound Scale Up의 효과

두 번째 실험은 MobileNet과 ResNet을 기준으로 기존 Scale Up 방법과 EfficientNet의 Compound Scale Up 성능을 비교한 실험입니다.
☑️실험 결과, 연산량이 비슷하게 Scale Up 했을 때 Compound Scale Up 방법 성능이 가장 높았습니다.
3) Transfer Learning Results
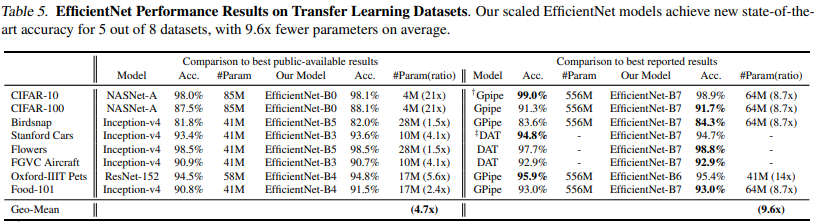

세 번째 실험은 ImageNet 사전학습 모델을 기반으로 다양한 데이터셋에 전이 학습을 적용한 성능을 분석한 실험입니다.
NasNet과 같은 공개된 모델과 비교했을 때 적게는 1.5배, 많게는 21배 파라미터를 줄이며 높은 정확도를 기록하였고, GPipe 등 최신 모델과 비교했을 때에도 적은 자원으로 비슷하거나 더 나은 성능을 냈습니다.
☑️실험 결과, EfficientNet은 평균적으로 적은 파라미터를 가지고도 더 높은 정확도를 달성했습니다.
4) Class Activation Map

네 번째 실험은 Compound Scale Up 방법이 왜 다른 방법들보다 우수한지 검증하는 실험입니다.
Compound Scale Up 을 적용한 모델은 객체 영역을 더 세부적으로 집중하는 경향이 있습니다.
위 예시에는 객체가 마카롱인데 다른 방법에 비해 마카롱에 유난히 집중하는 걸 볼 수 있습니다.
☑️실험 결과, 복합 스케일링은 이미지에서 중요한 영역에 초점을 맞추고 세부 정보를 잘 잡아내지만, 다른 방법들은 중요한 영역을 놓치거나 일부만 인식합니다.
[6] Conclusion
- EfficientNet은 CNN 모델을 확장할 때 어떻게 확장하는 것이 가장 효율적인지 알아내고자 등장
- Compound Scale Up
- CNN 모델의 깊이, 너비, 이미지 해상도를 균형있게 증가시켜야 함을 찾아냄
- $α = 1.2, β = 1.1, γ = 1.15$ 가 최적의 파라미터이고 $ϕ$ 를 곱해줘서 조정
- Architecture
- NAS가 만들어줌
- MBConv Layer를 활용한 Architecture
- CNN 모델을 확장할 때 Compound Scale Up 공식을 활용할 것을 제시하며 효율적이고 높은 성능의 모델을 제안했다는 의의
[7] References
https://ffighting.net/deep-learning-paper-review/vision-model/efficientnet/
https://ffighting.net/deep-learning-paper-review/vision-model/wide-resnet/
https://ahn1340.github.io/neural%20architecture%20search/2021/04/26/NAS.html
[논문리뷰] MoblieNet 논문 리뷰
MobileNet 논문 리뷰입니다.본 논문은 2017년도에 등장한 논문입니다. 논문 : MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications저자 : Andrew G. Howard Menglong Zhu Bo Chen Dmitry Kalenichenko Weijun
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] RetinaNet 논문 리뷰 (2) | 2025.02.03 |
|---|---|
| [논문리뷰] RoBERTa 논문 리뷰 (4) | 2025.02.02 |
| [논문리뷰] GPT-1 논문 리뷰 (2) | 2025.01.26 |
| [논문리뷰] YOLO 논문 리뷰 (2) | 2025.01.25 |
| [논문리뷰] U-Net 논문 리뷰 (2) | 2025.01.23 |
| [논문리뷰] Faster R-CNN 논문 리뷰 (2) | 2025.01.20 |
| [논문리뷰] ELMo 논문 리뷰 (2) | 2025.01.19 |
| [논문리뷰] Attention 논문 리뷰 (0) | 2025.01.16 |



