ELMo 논문 리뷰입니다.
본 논문은 2018년도에 등장한 논문입니다.

논문 : Deep contextualized word representations
저자 : Matthew E. Peters , Mark Neumann , Mohit Iyyer , Matt Gardner, Christopher Clark∗ , Kenton Lee∗ , Luke Zettlemoyer
[1] Background

본 논문은 Embeddings from Language Model 인 만큼 자연어를 임베딩하는 방법을 새롭게 제시하는 논문입니다.
Word2Vec이나 GloVe 등 전통적인 단어 임베딩 방식은 고정된 벡터 형태로 단어를 표현하는 방식입니다.
단어를 고정된 벡터로 변환해 단어 간 유사성을 측정하거나 언어적 관계를 추론 ( king - man + woman = queen )하는데 효과적이었습니다.
하지만 이런 경우에 단어의 '다의성'을 제대로 다룰 수 없다는 한계를 가지고 있습니다.
예를 들어 "쓰다" 라는 단어는 아래와 같이 많은 의미를 담고 있는데 이 때 전부 하나의 고정 벡터로 변환되는 점이 문제입니다.
1) 물건을 사기 위해 돈을 쓰다
2) 이 감기약은 너무 쓰다
3) 작가는 글을 쓰는 직업이다
따라서 이러한 문제점을 해결하기 위해 단어 표현을 문장 전체 문맥의 일부분으로 보면서 단어가 문장에서 어떤 의미로 쓰였는지 더 깊이 이해하도록 하는 개념을 제시합니다.
[2] Method
1) 캐릭터 기반의 Preliminary 임베딩

ELMo 논문에서 제시하는 핵심 개념 중 첫 번째는 캐릭터 기반의 예비 임베딩입니다.
예를 들어 본다면, "Anarchy" 라는 단어가 입력되었을 때 해당 단어는 각 철자, 캐릭터로 구분됩니다.
구분된 철자는 각각 고유 숫자로 mapping 되고 padding 작업이 수행된 후 고유 벡터 Matrix로 변환됩니다.
이제 CNN Layer에 들어가서 여러 채널에 단차원 Output을 생성하고
Max Pooling을 통해 단일 차원으로 압축합니다.
이후 Highway Network를 거쳐 512차원으로 줄이는 임베딩을 먼저 실행합니다.
이 캐릭터 기반의 임베딩 덕분에 오타가 발생하는 그런 상황에서 유연하게 단어를 다룰 수 있다는 점이 강점이라고 합니다.
여기서 Highway Network란 Residual Connection과 비슷한 개념으로, 특정 정보를 학습된 변환을 통해 변형하거나, 원래의 입력값을 그대로 전달하도록 선택할 수 있는 구조를 얘기합니다.

해당 수식을 따르는데, Residual Connection과 다른 점은 Residual Connection은 항상 출력값에 입력 정보를 F(x) + x로 더하지만, Highway Network는 변환할지, 그대로 전달할지 선택할 수 있는 유연성이 있습니다.
2) 양방향 LSTM 구조를 활용한 문맥정보 추출
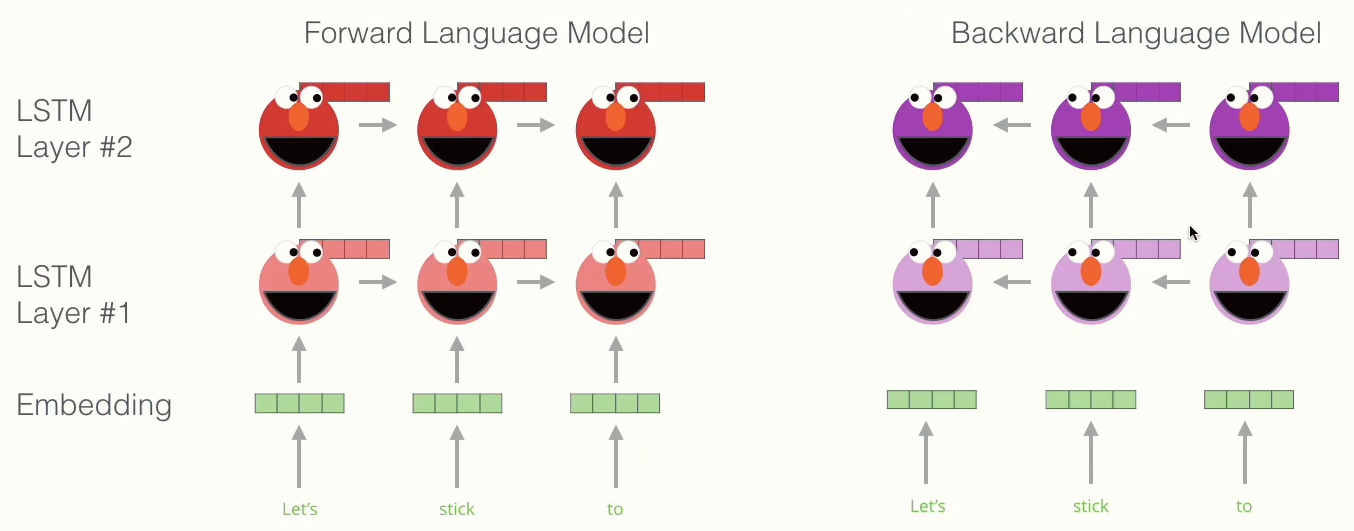
임베딩 층을 지난 후에는 위 사진처럼 양방향 LSTM 구조로 구성되어 있습니다.
정방향 LSTM (Forward Language Model) 에서는 처음부터 t -1 시점까지 등장한 단어의 확률분포를 가지고 다음 나올 단어를 예측하는 과정으로 문맥정보를 파악합니다.
역방향 LSTM (Backward Language Model) 에서는 반대로 끝에서부터 t+1 시점까지 등장한 단어 확률분포로 t 시점 단어의 문맥정보를 파악합니다.
따라서, 문맥에 독립된 단어 자체의 정보보다 문맥에서 쓰이고 있는 단어의 의미에 집중해서 보는 방식이 되겠습니다.

그 후 LSTM Layer를 지난 각각의 정방향, 역방향 임베딩 벡터는 Concat됩니다.
그런데 여기서 concat 된 Hidden Vector들끼리 가중치를 부여해서 가중합을 하는데, 여기서 s0, s1, s2에 해당하는 가중치들은 후에 Downstream Task에 따라 학습이 되어 조정됩니다.
예를 들어, 구문분석, pos 태깅 등의 task에서는 s0의 가중치가 큰 영향을 차지하도록 학습이 되고, 분류나 감성분석 등의 context에 대한 이해가 필요한 경우에는 s2의 가중치가 큰 영향을 주도록 학습이 됩니다.
결국 3번의 파란색 Vector가 ELMo로 생성한 단어 임베딩 벡터가 되는 것입니다.
3) 수식적으로 더 자세히 알아보기

정방향은 한 시퀀스 내에 단어가 1부터 N번째까지 있다고 가정할 때, k 시점의 단어 확률은 k-1까지의 단어를 모두 조건부로 삼아서 k 단어가 등장할 확률을 계산한 후 전부 곱해주는 방식으로 구합니다.
여기서 핵심은 정방향 LSTM에서는 k 이전에 등장한 단어에 대해서만 영향을 받는다는 것입니다.

반대로 역방향은 N에서부터 k+1까지의 단어들을 조건부로 삼아서 k 단어가 등장할 확률을 계산하고 곱해주는 방식입니다.
한마디로 미래의 문맥을 고려해 이전 토큰을 예측하는 방식인거죠.
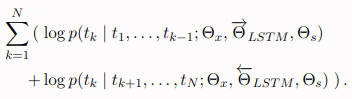
앞에서 나온 정방향 확률과 역방향 확률을 모두 최대화하는 k를 찾는 방식으로 계산을 하게 됩니다.
그리고 계산한 조건부 확률값들에 로그를 씌우고 다 더하면 총 로그 확률값이 나오는 구조로 되어 있습니다.

그래서 ELMo에서 생성하는 최종 단어 k에 대한 임베딩은 캐릭터 임베딩 + 정방향 임베딩 + 역방향 임베딩의 가중합 구조로 되어 있습니다.
위 식에서 f와 b는 down stream task에 따라 낮은 차원의 임베딩에 더 중점을 둘건지, 아니면 문맥도 고려해야 하는 높은 차원의 임베딩에 중점을 둘건지 결정하는 파라미터이고, r은 전체적인 임베딩의 scale을 조정하는 파라미터라고 보면 되겠습니다.
[3] Experiment

- 위 표는 ELMo를 추가한 모델이 6개의 NLP Benchmark Task에서 SOTA를 달성했음을 보여줌
- 특히 SQuAD와 SRL에서는 높은 수치의 상대적 성능 개선이 이루어졌으며 Coref와 NER에서도 이전 모델 앙상블 결과를 뛰어넘는 SOTA를 달성함
- ELMo가 다양한 모델 구조와 언어 이해 작업에서 일반적으로 성능을 향상시킨다는 것을 입증

- Table 2는 biLM을 마지막 계층만 사용했을 때(양방향 LSTM을 두번 지난 벡터)와 모든 계층을 사용했을 때의 성능 차이를 비교하며, 모든 계층을 사용한 경우에 더 높은 성능을 보임
- 람다는 크게 설정하면(람다 = 1) 가중치를 평균적으로 만들기 때문에 과적합 방지에 도움이 되고 작게 설정하면(람다 = 0.001) 가중치를 자유롭게 설정하기에 성능 향상에 도움이 되는 파라미터
- Table 3는 ELMo를 입력 단계, 입력+출력 단계, 출력 단계에 적용했을 때의 각각 성능을 보여주며, SRL을 제외하고 입력+출력 단계에 모두 ELMo를 활용하는 것이 성능 향상에 도움이 됨
여기서 출력 단계에 ELMo를 활용한다는 것은 모델이 최종적으로 예측을 생성할 때도 ELMo 벡터를 다시 참고한다는 의미입니다.
예시: 감정 분석 (Sentiment Analysis)
- 입력: "I don't think this movie is bad."
- 입력 계층에서 ELMo 벡터를 사용하여 문맥을 이해하고, 모델이 처리합니다.
- 출력 계층에서 ELMo 벡터를 추가하여, "bad"가 문맥적으로 부정적인 의미로 쓰였다는 것을 더 명확하게 만듭니다.
- 예: "don't"과 "bad"의 조합을 고려하여, 모델이 "positive" 감정임을 정확히 예측.
➡ 입력과 출력 단계 모두에서 ELMo를 활용하면, 모델이 단어의 문맥적 의미를 더 잘 파악하고 최종 예측을 개선
[4] Conclusions
- ELMo는 biLM을 활용해 단어의 문맥적 의미를 반영하는 고품질의 깊은 컨텍스트 종속 표현을 학습하기 위해 도입됨
- ELMo는 biLM의 여러 계층에서 학습된 구문 및 의미 정보를 모두 활용하며, 이를 통해 다양한 NLP 작업에 적합한 문맥 표현을 제공함
- 캐릭터 예비 임베딩 + 양방향 LSTM을 통한 임베딩을 활용하여 문맥 정보를 효과적으로 학습
- 실험 결과, ELMo를 활용한 모델은 대부분의 NLP 작업에서 성능이 크게 향상되었으며, 모든 계층을 결합하여 사용하는 방식이 전반적인 성능 향상에 가장 효과적임을 확인함
[5] Reference
https://www.youtube.com/watch?v=YilcZp3WuoI&t=606s
https://www.youtube.com/watch?v=zV8kIUwH32M
[논문리뷰] BERT 논문 리뷰
자, 오늘은 X:AI Seminar 2024에서 진행한 BERT 논문 리뷰를 가져왔습니다.해당 논문은 2019년에 발표되어 ELMO, GPT-1의 모델과 비교를 하면서 얘기를 시사하고 있습니다. 논문 : BERT, Pre-training of Deep Bidire
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] GPT-1 논문 리뷰 (3) | 2025.01.26 |
|---|---|
| [논문리뷰] YOLO 논문 리뷰 (2) | 2025.01.25 |
| [논문리뷰] U-Net 논문 리뷰 (3) | 2025.01.23 |
| [논문리뷰] Faster R-CNN 논문 리뷰 (2) | 2025.01.20 |
| [논문리뷰] Attention 논문 리뷰 (2) | 2025.01.16 |
| [논문리뷰] MoblieNet 논문 리뷰 (3) | 2025.01.12 |
| [논문리뷰] SPPNet 논문 리뷰 (0) | 2025.01.08 |
| [논문리뷰] Inception v2, v3 논문 리뷰 (2) | 2025.01.04 |



