GPT-1 논문 리뷰입니다.
본 논문은 2018년도에 등장한 논문입니다.

논문 : Improving Language Understanding by Generative Pre-Training
저자 : Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever
[1] Background

논문에서 Abstract 부분에 Unlabeled Data가 Labeled Data 보다 양이 비교할 수 없을만큼 많다고 주장합니다.
당연한 얘기죠. Labeled Data는 사람이 직접 라벨링을 해야 하니까 양이 적을 수밖에 없습니다.
또한 Labeled Data를 만들기 위해서 시간과 비용, 인력이 소요됩니다.
논문 저자들은 자연스럽게 Unlabeled Data를 언어 모델에 활용할 수 없을까를 생각하게 됩니다.
하지만 Unlabeled Data를 학습에 사용하려고 해도 문제점이 여전히 존재했는데요.
1) 어떤 목적함수로 사전학습을 시켜야 파인튜닝 단계에서 효율적으로 학습이 되는가?
2) 전이학습 할 때 효율적으로 Target Task에 적용시키는 방법을 모른다
그래서 낸 결론은 사전학습 시에 Language Model, 즉 언어모델 자체의 목적함수를 사용하고 Transformer Decoder 구조를 사용하며 Fine Tuning 시에는 Task에 맞게 문장을 순서를 달리해서 입력하는 방식이었습니다.
무슨 말인지 차차 알아보겠습니다.
선행 연구로서 ELMo나 Transformer를 참고하셔도 좋습니다.
[논문리뷰] Transformer 논문 리뷰
오늘은 Transformer 논문 리뷰를 가져왔습니다. 해당 논문은 2017년에 발표된 논문입니다. 논문 : Attention Is All You Need저자 : Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz
dangingsu.tistory.com
[2] Model Architecture

위에서 설명했다시피 GPT 모델은 사전학습 단계와 파인튜닝 단계로 나눠서 학습이 진행됩니다.
Pretraining
사전 학습은 Unsupervised Learning 으로 처리합니다.
대용량 코퍼스 데이터를 사용해서 언어 자체를 학습하는 거죠.

비지도 학습 Corpus U는 1부터 n까지의 토큰으로 구성되어 있습니다. → $U = {u_1, . . . , u_n}$
여기서 언어 모델의 목표는 조건부확률 P를 최대화하는 것입니다. (가장 높은 확률의 토큰만 쏙쏙 골라 합한 확률을 최대화)
$i$ 번째 text가 나올 확률을 최대화하는 것이기 때문에 max likelihood를 loss function으로서 학습하고 이를 통해 비지도 학습이 가능해집니다.
그리고 저 언어 모델은 Transformer의 Decoder Module을 사용해서 학습을 시킵니다.

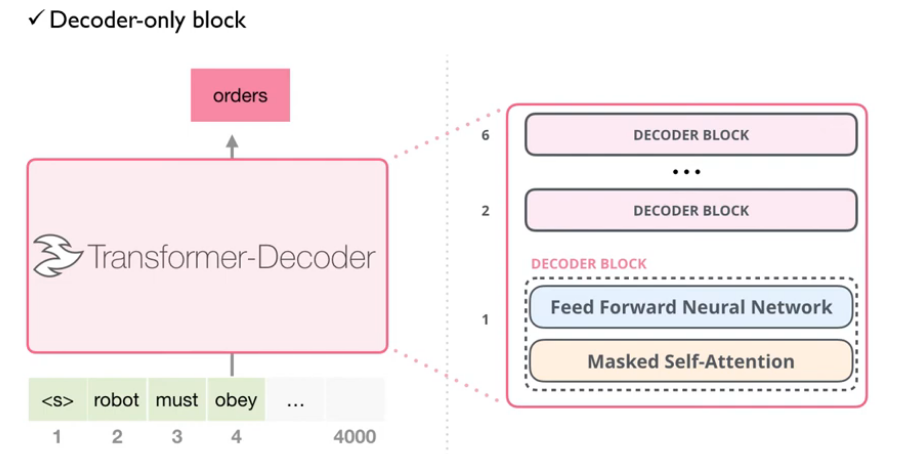
GPT-1 은 Transformer의 Decoder를 여러 층으로 쌓아서 활용합니다.
$h_0$ : 모든 토큰 임베딩 + 포지셔닝 임베딩 (concat 아니고 그냥 sum)
$h_l$ : l 이전의 토큰을 활용해 l 번째 토큰 예측 (Transformer Block)
$P(u)$ : 다음 토큰의 확률 분포를 예측하는데, 이때 각 단계에서 전체 시퀀스는 입력되지만 마스킹을 통해 l 번째 이후의 토큰은 보지 못하도록 설정하고 Softmax 함수를 취해서 확률값을 구함
→ 이렇게 구한 $P(u)$ 들의 합을 최대화하는 것이 목적함수의 목표
Jay Alamar의 블로그를 참조한 설명

입력 토큰이 robot must obey orders 라고 했을 때 각 $i$ 번째 입력되는 단어와 라벨은 위 사진과 같습니다.

간단하게 보면 다음과 같습니다.
1) Self Attention을 통해 Query, Key Matrix를 연산
2) Score Matix에 Masking 벡터 적용
3) 적용 후 Softmax 함수 취해서 가장 높은 토큰 출력
Fine Tuning
사전 학습 후 GPT 모델은 아래 수식으로 Fine Tuning을 진행합니다.

Input 문장 x에 토큰이 m 개 있을 때 마지막 Decoder Block을 거쳐서 나온 출력값의 softmax 임베딩과 라벨 임베딩과 cross entropy loss로 비교합니다.
$L2(C)$는 이러한 출력 y값의 확률을 최대화하는 log likelihood를 목표로 학습하는 겁니다.
추가적으로 본 논문 저자들은 신기한 사실을 알아냈는데요.
$L_3(C) = L_2(C) + λ *L_1(C)$
Loss Function을 설정할 때 $L_2(C)$ 뿐만 아니라 $L_1(C)$ 도 함께 사용하면 일반화 성능이 오르고 학습 속도가 빨라진다는 겁니다.
여기서 $L_1(C)$는 사전학습때 학습한 Loss Function을 Supervised Corpus를 활용해 다시 학습을 시키는 것을 의미합니다.
→ 즉, $L_1(C)$ 가 전이학습을 의미하는 개념이고, 바로 이 부분이 가중치만 학습시켰던 ELMo와 차이가 나는 부분입니다.
λ는 두 손실 사이의 균형을 조정하는 하이퍼파라미터입니다.
Task Specific GPT

GPT는 각 Specific, 특정 Task에 맞게 입력을 다르게 해서 적합시킵니다.
💡 각 Task에 따른 구체적인 예시
1) Classification (분류 - 감정분석 등)
- 입력 : <SOS> 너무 신난다. <EOS>
- 동작 : 입력 토큰의 특성을 분석해 전체 문장이 긍정일 확률이 높은지 부정일 확률이 높은지에 따라 응답 출력
- 출력 : 긍정, 부정, 중립 등
- 예상 라벨 : 긍정
2) Entailment (연역 - 문장 관계 분석 등)
- 입력 : <SOS> 손 들어! <Delim> 움직이면 쏜다! <EOS>
- 동작 : <Delim> 토큰으로 구분된 두 문장의 논리적 관계를 파악해 결과 출력
- 출력 : 참, 거짓, 중립 등
- 예상 라벨 : Contradiction (거짓, 모순)
3) Multiple Choice (다중 선택, 객관식 등)
- 입력 : <SOS> 존은 아침에 커피를 마셨다. <Delim> 1. 존은 차를 마셨다. <Delim> 2. 존은 커피를 마셨다. <Delim> 3. 존은 주스를 마셨다. <EOS>
- 동작 : <Delim> 토큰으로 구분된 n개의 문장 중에 가장 적절한 답을 선택
- 출력 : 가장 적절한 답의 번호
- 예상 라벨 : 2
4) Translation (기계 번역)
- 입력 : <SOS> 나는 밥을 먹었다. <To English> <EOS> (정해진 규칙은 없으나 명시적으로 알려준다면 성능 향상)
- 동작 : 입력된 문장을 다른 언어로 번역
- 출력 : 번역된 문장
- 예상 라벨 : I ate rice (Sequence=level cross entropy loss)
[3] Experiments
Dataset

사전 학습 시에는 Book Corpus 데이터셋을 활용하고 파인튜닝 시에는 위 데이터셋을 사용했다고 합니다.
Book Corpus 데이터셋에는 의미가 이어져 있는 문장이 많아 긴 정보를 학습하기에 용이했다고 합니다.
Natural Language Inference
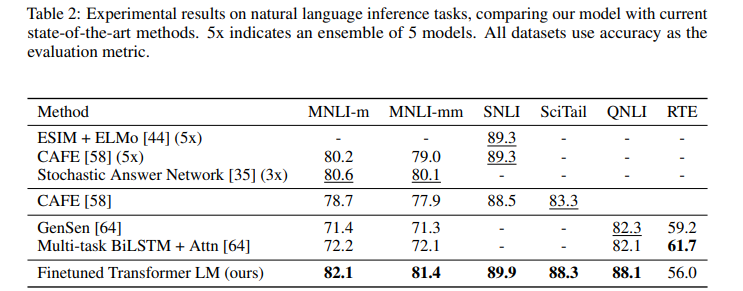
위 Table 2 의 Finetuned Transformer LM이 GPT를 의미하고 대부분의 NLI Task에서 SOTA를 달성했음을 알 수 있습니다.
Question & Answering

Table 3 에 나와있듯이 QA Task에서도 GPT가 가장 높은 성능을 기록하고 있습니다.
Semantic Similarity & Classification

Table 4 에 따르면 그렇지 않은 데이터셋도 있지만 많은 데이터셋에서 SOTA를 달성했음을 알 수 있습니다.
Ablation Studies

다음은 GPT Model에 대한 Ablation Study이고 왼쪽이 Decoder Block 수에 따른 성능, 오른쪽이 Fine Tuning의 결과 분석입니다.
결과적으로, Decoder Block을 많이 쌓을수록 성능이 올라갔고, Fine Tuning을 통해 사전학습된 모델을 업데이트시킬수록 대체로 성능이 향상되었습니다.

다음 실험은 사전학습의 효과에 대해서 알아보는 실험입니다.
Transformer w/ aux LM (full) : GPT 모델을 의미
Transformer w/o pre-training : 사전학습을 제외한, 기본 가중치를 가진 GPT 모델에 Supervised 학습만 시킨 모델
Transformer w/o aux LM : 사전학습된 모델만을 활용해 예측을 수행하는 모델 (파인튜닝 X)
LSTM w/ aux LM : Transformer Decoder가 아니라 LSTM을 사용한 모델
결론적으로, 데이터셋이 작은 경우에는 사전학습만 사용한 경우가 더 좋았고, 데이터셋이 좀 큰 경우에는 사전학습 + 파인튜닝이 좋았으며, LSTM은 Transformer Decoder에 못 미친다는 얘기를 하고 있습니다.
💡 이 부분에 대해 w/o aux LM 의 개념이 살짝 헷갈렸는데 다시 정리하자면
$L_1(U)$ : 대규모 Unlabeled Dataset에서 다음 단어를 예측하며 가중치를 사전학습하기 위한 목적함수
$L_1(C)$ : Labeled Dataset에서 다음 단어를 예측하며 가중치를 재학습하기 위한 목적함수
$L_2(C)$ : DownStream Task에 맞는 목적함수
따라서, w/o aux LM는 파인튜닝 단계에서 Likelihood를 $L_2(C)$만 쓴거라고 이해를 했습니다.
Task에 적합시키기에는 Task에 맞는 목적함수가 필요한데 이때는 $L_1(C)$가 보조함수가 될테니까요.
[4] Conclusions
- GPT-1 모델은 Labeled Dataset만 학습시켜왔던 기존의 방식을 해결하고자 Unlabeled Dataset으로 학습시키는 방법을 찾았고 그 과정에서 사전학습과 파인튜닝 단계로 나눠서 학습하는 PLM 모델을 제시했습니다.
- 모델은 Transformer의 Decoder Block 만을 쌓아서 활용해 이전 토큰을 가지고 다음 토큰을 예측하는 방식으로 학습을 진행하는 구조를 가지고 있습니다.
- 실험 결과, GPT-1은 다양한 자연어 이해 및 생성 Task에서 우수한 성능을 보였습니다.
[5] References
https://kyujinpy.tistory.com/74
https://velog.io/@tobigs-nlp/Improving-Language-Understandingby-Generative-Pre-Training-GPT-1
https://www.youtube.com/watch?v=o_Wl29aW5XM
[논문리뷰] BERT 논문 리뷰
자, 오늘은 X:AI Seminar 2024에서 진행한 BERT 논문 리뷰를 가져왔습니다.해당 논문은 2019년에 발표되어 ELMO, GPT-1의 모델과 비교를 하면서 얘기를 시사하고 있습니다. 논문 : BERT, Pre-training of Deep Bidire
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] Mask R-CNN 논문 리뷰 (1) | 2025.02.17 |
|---|---|
| [논문리뷰] EfficientNet 논문리뷰 (3) | 2025.02.05 |
| [논문리뷰] RetinaNet 논문 리뷰 (3) | 2025.02.03 |
| [논문리뷰] RoBERTa 논문 리뷰 (5) | 2025.02.02 |
| [논문리뷰] YOLO 논문 리뷰 (2) | 2025.01.25 |
| [논문리뷰] U-Net 논문 리뷰 (3) | 2025.01.23 |
| [논문리뷰] Faster R-CNN 논문 리뷰 (2) | 2025.01.20 |
| [논문리뷰] ELMo 논문 리뷰 (2) | 2025.01.19 |



