RoBERTa 논문 리뷰입니다.
본 논문은 2019년도에 등장한 논문입니다.

논문 : RoBERTa: A Robustly Optimized BERT Pretraining Approach
저자 : Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov
[1] Background
RoBERTa : A Robustly Optimized BERT Pretraining Approach
본 논문은 이름에서 알 수 있듯이 BERT 모델을 더 발전시킨 언어 모델입니다.
그래서 기존 BERT 모델에 비해 어떤 점이 달라졌고 발전되었는지 비교하면서 보면 좋을 것 같습니다.
추가로 같은 해에 등장한 XLNet과도 비교를 하고 있습니다.
논문에서 제시하는 가장 핵심적인 배경은 ELMo, GPT, BERT, XLNet 등 다양한 언어 모델이 등장하고 NLP Task에서 성능 향상이 되었지만 각 논문에서 사용하는 방법론과 데이터셋 등 서로 상이해 어떤 방법론이 성능 향상에 가장 큰 기여를 하는지 알기가 힘들다는 것이고, BERT에서 사용하는 MLM은 아직 경쟁력이 있으며 BERT가 학습이 덜 되었다는 것입니다.
BERT의 더 자세한 내용은 아래 포스팅을 참고해주시면 감사하겠습니다.
[논문리뷰] BERT 논문 리뷰
자, 오늘은 X:AI Seminar 2024에서 진행한 BERT 논문 리뷰를 가져왔습니다.해당 논문은 2019년에 발표되어 ELMO, GPT-1의 모델과 비교를 하면서 얘기를 시사하고 있습니다. 논문 : BERT, Pre-training of Deep Bidire
dangingsu.tistory.com
[2] Method
RoBERTa에서 새로 추가하거나 바꾼 학습방법
▷ 더 큰 데이터로 더 오래 학습
▷ 큰 배치사이즈로 학습
▷ NSP 제거
▷ 동적 마스킹
1) 더 큰 데이터로 더 오래 학습

- large-scale text copora dataset(160GB)
- BookCorpus + Wikipedia (16GB)
- CC-News (76GB)
- CommonCrawl News Dataset의 영어부분에서 수집한 CC-News Dataset
- 2016년 9월 ~ 2019년 2월 사이에 크롤링된 6300만개의 영문 뉴스 기사 포함
- Open Web Text (38GB)
- Open-GPT2에서 설명한 WebText Corpus의 open-source recreation
- Reddit에서 공유되는 URL에서 추출한 Web Contents
- Stories (31GB)
- CommonCrawl Data의 하위 집합을 포함
- 이야기와 같은 스타일의 Winograd schema와 일치하도록 filtering
☑️실험 결과 기존의 BERT 모델에 비해 사전학습 데이터를 10배 늘렸더니 성능이 올랐고, 이는 더 오래 학습시킬수록 성능이 더욱 올랐습니다. 추가로, XLNet에도 추가적인 데이터로 학습을 시켰을 때에도 RoBERTa가 성능이 더 높았다는 이야기를 하고 있는데 애초에 data랑 batch size 크기가 다른데 저 수치보다 성능이 높았다는 것은 조금 의문이 들긴 합니다.
2) 큰 배치사이즈로 학습

Batch Size란 모델의 가중치가 업데이트되기 전에 처리되는 데이터의 수를 의미합니다.
예를 들어, Batch Size가 256이라면 가중치 업데이트를 수행하기 전에 256개의 데이터를 참고한다는 거구요.
2K, 8K와 같이 Batch Size가 클수록 한 번의 업데이트에 훨씬 더 많은 데이터를 처리합니다.
Batch Size를 키운다는 것은 모델의 성능을 개선하고 동시에 학습 효율성을 높이기 위해 중요합니다.
일단 Step 수를 줄여서 더 적은 업데이트로도 모델 성능을 올릴 수 있고, GPU의 효율적인 사용에도 도움이 된다고 합니다.
그리고 큰 Batch는 데이터의 분포를 더 잘 반영하므로 가중치 업데이트 방향이 정확하기 때문에 더 큰 폭으로 가중치를 업데이트 할 수 있고 이를 위해 Learning Rate를 키우는 것이 적합합니다.
☑️ Batch Size가 커질수록 가중치의 분산이 줄어드는 것을 보완하기 위해 LR를 증가시켜야 한다는 논문도 있다고 합니다.
실험 결과, Batch Size 2K의 경우가 가장 Perplexity가 낮았고 Fine Tuning 단계에서도 성능이 가장 좋았습니다.
3) NSP 제거
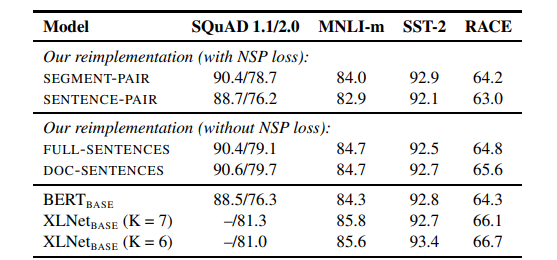
기존 BERT 논문에서는 NSP(Next Sentence Prediction)가 QNLI, MLNI, SQuAD 등 여러 문장의 문맥적 의미를 파악하는데 중요한 역할을 했다고 주장하는데, RoBERTa에서는 이 NSP를 제거해서 실험해봅니다.
- SEGMENT-PAIR + NSP
- BERT의 원본 방식과 동일 ( 하나의 입력에 두 개의 Segment를 이어 붙임 )
- 두 Segment는 50% 확률로 같은 문서에서 연속적으로 추출되거나 전혀 다른 문서에서 추출됨
- SENTENCE-PAIR + NSP
- segment 대신 문장 단위로 쪼개서 두 문장을 합침
- 문장 단위로만 자른 뒤 합치므로 입력 시퀀스가 상대적으로 짧아서 총 토큰 수를 맞추기 위해 Batch Size를 늘림
- FULL-SENTENCES
- 512 토큰을 꽉 채우도록 여러 문장을 연속적으로 이어붙임 ( 문서 경계와는 무관하지만 문서 구분 토큰을 입력 )
- 문서 1의 문장1 → 문서 1의 문장2 ... (512 토큰이 될 때까지) → 문서1의 토큰을 다 쓰고 남는다면 바로 문서 2의 문장1부터 이어 붙이는 방식 ( NSP loss 제거 )
- DOC-SENTENCES
- FULL-SENTENCES와 유사하게 512 토큰까지 문장을 이어붙이되 문서 경계는 넘지 않도록 설정
- document의 끝 부분에 sampling된 입력은 512개의 token보다 짧을 수 있으므로 이러한 경우 전체 batch와 비슷한 수의 전체 sentence를 얻기 위해 동적으로 batch size를 늘림
→ 입력 토큰 수가 적어 512를 못 채운 경우 padding을 적용하거나 후에 batch size를 재조정하는 등의 방법으로 코드를 작성한 것 같습니다.

☑️ 실험 결과, NSP를 제거해도 오히려 성능이 개선되는 결과가 나타났고, Doc-Sentences의 경우가 가장 높은 성능을 기록하였습니다.
4) 동적 마스킹
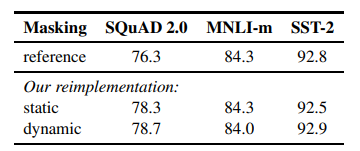
기존 BERT에서는 임의의 15% 토큰을 [MASK] 토큰으로 치환하고 이를 예측하도록 학습하며 마스킹 작업을 데이터 전처리 시점에 한 번만 수행했습니다. (모델 입력 전에 수행)
그렇기 때문에 매 에포크마다 같은 마스킹 패턴을 학습하는 결과로 이어지고 이 부분이 비효율적이라고 주장합니다.
그래서 RoBERTa는 마스킹 패턴을 매번 재생성하는 동적 마스킹 방식을 사용합니다.
이를 통해 다양하고 풍부한 마스킹 케이스를 학습할 수 있고 데이터셋이 커지더라도 중복학습되는 경우를 그나마 방지할 수 있어서 이러한 장점을 기대했습니다.
☑️ 실험 결과, 성능이 대폭 개선되거나 하지는 않았지만 학습 효율성 측면에서 동적 마스킹 방식이 앞으로 대규모 Corpus 학습에 더 적합하다는 점이 중요하겠습니다.
5) 텍스트 인코딩
기존 BERT와 달리 RoBERTa에서는 BPE(Byte-pair Encoding)을 사용합니다.
💡 BPE란?
BPE는 서브워드 단위 인코딩 기법으로 한 단어를 더 이상 쪼갤 수 없을 때까지 빈도가 높은 문자 쌍으로 반복적으로 Merge 시키면서 단어를 만듭니다.
→ "l o w e r", "n e w e r" 등의 단어가 있을 때 가장 자주 등장하는 문자열 쌍부터 순차적으로 합치며 subword 집합을 확장
<장점>
1) 미등록 단어 문제를 크게 줄일 수 있다
2) 문자 단위로 학습할 때보다 훨씬 빠르고, 문맥 정보를 풍부하게 활용할 수 있다
기존 BERT의 방식은 문자 기반으로 쪼개 약 30K 크기의 subword 사전을 만들었습니다.
예를 들어 "don't" 같은 단어가 [don, ', t]의 형태로 쪼개질 수 있습니다.
RoBERTa는 위와같은 바이트 기반 BPE를 사용해서 약 50K 크기의 subword 사전을 만들었습니다.
이를 통해 문자를 굳이 전처리로 쪼개지 않아도 되므로, 추가적인 토크나이저 규칙이 필요없고 희귀 단어나 다양한 언어도 일관된 방식으로 처리할 수 있습니다.
하지만 subword 사전이 증가한 만큼 파라미터가 증가한 점이 단점입니다.
기존 BERT의 약 30K의 사전보다 성능이 조금 떨어지거나 비슷한 결과가 나타났지만 언어 처리의 강건함 측면에서 바이트 기반 BPE의 이점이 훨씬 크다고 판단하여 RoBERTa에서는 BPE를 사용했습니다.
[3] Experiments
1) GLUE Task
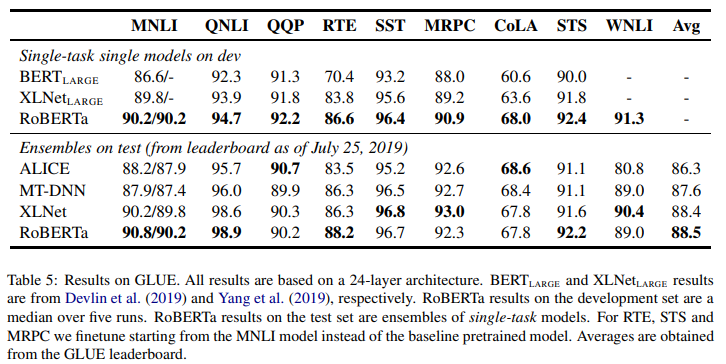
- RoBERTa는 GLUE Benchmark Single Model 부분에서 9개 부분 모두 BERT와 XLNet을 능가하는 뛰어난 성능을 기록함
- Test Set에서도 5~7개의 모델을 앙상블해 9개 중 4개의 Task에서 SOTA를 달성하고 평균 1위를 기록함
- 이를 통해 대규모 데이터를 활용한 충분한 사전학습이 중요함을 시사함
2) SQuAD Task
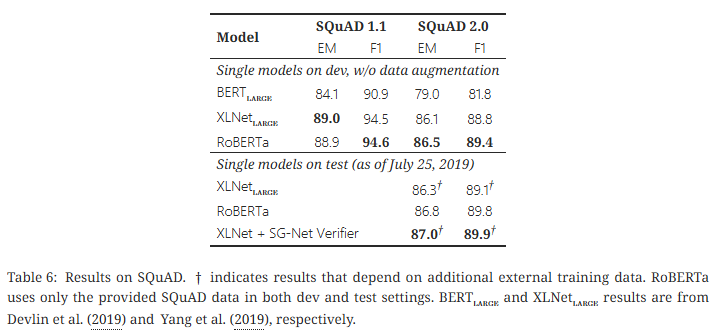
- RoBERTa는 별도의 데이터 증강 없이 SQuAD 공식 데이터만 사용해 BERT, XLNet과 비슷하거나 더 나은 성능을 달성
- SQuAD v2.0에서는 이전 대비 0.4 EM, 0.6 F1 향상으로 새로운 최고 성능을 기록하며, 외부 QA 데이터 없이도 상위권을 차지 (위 사진에는 나오지 않음)
- 단일 모델 기준으로도 경쟁력 있는 결과를 내며, 데이터 증강의 필요성을 최소화한 간단한 접근법을 제시함
3) RACE Task
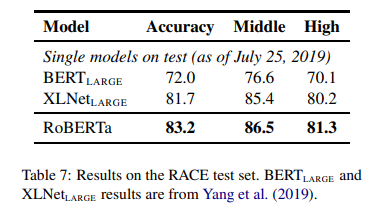
- RoBERTa는 RACE 태스크에서 질문·지문·후보답안을 하나의 시퀀스로 연결해 분류하는 간단한 접근법을 사용
- 이 과정에서 각 후보마다 별도 [CLS] 임베딩을 얻어 정답 후보를 예측하며, 입력 길이를 최대 512 토큰으로 제한
- 결과적으로 중학생(Middle)·고등학생(High) 버전 모두에서 기존 BERT, XLNet 대비 최고 성능을 달성함
[4] Conclusions
- RoBERTa는 BERT가 학습이 덜 되었다는 점을 지적해 데이터 증강, 마스킹 전략 등을 개선한 모델
- 사용한 방법론
- 동적 마스킹 전략
- 더 많은 데이터로 더 오래 학습
- 더 큰 배치사이즈 사용
- NSP 제거
- BPE 사용
- RoBERTa는 GLUE, SQuAD, RACE 등 대표적인 벤치마크에서 뛰어난 성능을 보이며 SOTA를 달성
[5] References
https://www.youtube.com/watch?v=_FUXSTK_Xqg
https://jeonsworld.github.io/NLP/roberta/
[논문리뷰] XL-Net 논문 리뷰
오늘은 XL-Net 논문 리뷰를 가져왔습니다. 해당 논문은 2019년에 발표된 논문입니다. XLNet: Generalized Autoregressive Pretraining for Language Understanding저자 : Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Sa
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] RetinaNet 논문 리뷰 (2) | 2025.02.03 |
|---|---|
| [논문리뷰] GPT-1 논문 리뷰 (2) | 2025.01.26 |
| [논문리뷰] YOLO 논문 리뷰 (2) | 2025.01.25 |
| [논문리뷰] U-Net 논문 리뷰 (2) | 2025.01.23 |
| [논문리뷰] Faster R-CNN 논문 리뷰 (2) | 2025.01.20 |
| [논문리뷰] ELMo 논문 리뷰 (2) | 2025.01.19 |
| [논문리뷰] Attention 논문 리뷰 (0) | 2025.01.16 |
| [논문리뷰] MoblieNet 논문 리뷰 (2) | 2025.01.12 |



