오늘은 XL-Net 논문 리뷰를 가져왔습니다.

해당 논문은 2019년에 발표된 논문입니다.
XLNet: Generalized Autoregressive Pretraining for Language Understanding
저자 : Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
[1] Background
NLP 분야에서 대규모 Unlabeled Text Data로 사전학습시키고 Downstream Task에 맞게 추가 파인튜닝하는 방법이 매우 성공적이었습니다.
그 중에서 대표적으로 AR(Auto Regressive)과 AE(Auto Encoding) 방식이 있습니다. (AR은 GPT, AE는 BERT)
→ 일단 본 논문은 RoBERTa 이전의 논문입니다.
1) Auto Regressive
AR 언어 모델링은 텍스트 데이터의 확률 분포를 자기회귀 모델로 추정하는 방법입니다.
즉, k 시점 이전의 데이터들을 가지고 k번째를 예측하는, 앞에서부터 순차적으로 예측하는 방식을 의미하죠.
대표적인 예시로 GPT가 있습니다.
하지만 이러한 AR 방식의 언어 모델(예를들어, GPT)은 한 방향으로만 예측하기 때문에 문장의 앞뒤 관계를 고려하지 못한다는 한계가 존재합니다. (실제 NLP 작업에서는 문맥을 양방향으로 고려해야 하는 경우가 많음)
2) Auto Encoding
반면, AE 기반 사전학습은 확률분포를 추정하는 방식을 사용하지 않고 손상된 입력을 바탕으로 원본 데이터로 복원하는 방식으로 동작합니다.
위 사진처럼 입력 토큰 중 일정 부분을 MASK 토큰으로 대체하고 MASK 토큰이 원래 무슨 토큰이었는지 예측하면서 학습하죠.
그래서 AR 언어 모델의 양방향 정보 부족 문제를 해결하여 성능 향상을 가져왔습니다.
대표적인 예시로 BERT가 있습니다.
하지만 BERT는 사전학습 때 MASK 토큰을 활용하지만 Fine Tuning 시에는 MASK 토큰이 존재하지 않습니다.
그래서 사전학습과 파인튜닝 사이에 차이가 발생합니다.
또한, BERT는 [MASK] 토큰의 단어들 사이에 독립적이라고 가정하는데, 자연어에서는 단어들 간 연관성이 강하기 때문에 이런 가정이 지나치게 단순화되어 있는 것도 문제점입니다.
💡사전학습에는 MASK 토큰이 있는데, 파인튜닝 시에는 MASK 토큰이 없다?
예를 들어, "너무 신난다." 라는 문장을 감정분석하는 Task라면
사전학습 시에는 "[MASK] 신난다."의 입력을 받겠지만
파인튜닝 시에는 "<SOS> 너무 신난다. <EOS>"의 입력을 받아 입력 문장에 따라 긍정/부정/중립 등 출력을 생성합니다.
즉, 입력 자체도 다르고, 사전학습과 파인튜닝에 사용하는 Loss Function이 각각 다르기 때문에
'사전학습과 파인튜닝 사이에 차이가 발생'한다는 의미입니다.
3) XL-Net의 등장배경
위와 같은 AR, AE 등 각 방식의 언어 모델의 장단점이 드러나는 상황에서 XLNet은 AE의 장점을 결합한 AR 방식의 모델을 제안합니다.
기존의 AR 모델은 고정된 방향(앞 → 뒤 or 뒤 → 앞)으로만 단어를 예측하는 방식이었지만 XLNet은 가능한 모든 순열에 대해 log likelihood를 최대로 하는 방식으로 학습합니다.
순열 방식을 활용하면 결과적으로 양방향 문맥을 효과적으로 반영할 수 있게 되어 기존 AR 방식의 한계점을 보완할 수 있습니다.
반대로 XLNet은 AR 모델이기 때문에 [Mask] 토큰을 사용하지 않아 사전학습과 파인튜닝 간의 차이 문제를 겪지 않기 때문에 AE 방식의 한계점도 보완할 수 있습니다.
추가로, Transformer-XL에서 영감을 받아 Model Architecture 도 개선했다고 합니다.
💡 What is Transformer-XL?
- XLNet 논문리뷰이기 때문에 Transformer-XL 핵심 개념만 간략하게 정리
1) Segment Recurrence Mechanism
- 기존 Transformer의 가장 큰 장점은 장기의존성 문제를 완벽히 해결한 점인데, 일반적인 Transformer는 길이가 정해진 문장만 처리가 가능하기에 긴 문장을 처리할 때 문맥이 잘리는 문제가 발생
- 문장을 여러 Segment로 나누고 한 토큰씩 이동하면서 추론해 더 긴 범위의 의존성을 학습 가능하게 함
예를 들어, 아래의 두 문장이 입력됐다면
Segment 1: "나는 오늘 도서관에서 책을 빌렸다."
Segment 2: "그런데 그 책이 정말 재미있었다."
기존 Transformer에서는 Segment 2가 Segment 1의 정보를 알지 못해 "그 책"이 어떤 책인지 이해할 수 없음
Transformer-XL에서는 Segment 1의 출력을 Segment 2의 입력에 포함시켜서 학습
→ Segment 2를 예측할 때, Segment 1의 정보를 참조할 수 있게 설계
2) Relative Positional Encoding
- 일반적인 Transformer는 그냥 임의의 수치를 부여하는 절대적 positional encoding을 사용하지만, 문장 내에서 단어들의 상대적인 위치가 더 중요한 경우가 많음
→ 특히 순열에서 상대적 순서는 더욱 중요함 (고양이가 쥐를 쫓는다 / 쥐가 고양이를 쫓는다)
- 그래서 단어 간 상대적 위치 정보를 반영하는 새로운 positional encoding 방식 도입 (토큰끼리의 상대적 거리를 학습)
Transformer-XL이 더 궁금하신 분들은 아래 포스팅을 참고해주세요. (정리가 잘 되어있더라구요)
Transformer-xl: Attentive language models beyond a fixed-length context
Extra-Large한 Language Model을 만들어볼까? | 16기 장준원
velog.io
추가적으로, XLNet 등장 이전에도 순열을 활용한 언어 모델이 있기는 했지만 XLNet과는 다음과 같은 차이점이 있다고 합니다. (관련 연구는 봐도 이해가 잘 안되서 GPT의 힘을 빌렸슴닷)
[2] Proposed Method, XL-Net
- 1번에서 언급했던 AR, AE의 장점은 가져가고 단점을 극복하기 위해 등장한 모델이 XL-net, but 어떻게 극복했을까?
2-1) Permutation Language Modeling Objective
- 입력 Sequence의 순서의 모든 permutation(순열)을 고려한 AR 방식 사용
- [x1, x2, x3, x4]를 예측할 때, Zt = [[1,2,3,4], [1,2,4,3], [1,3,2,4], …]
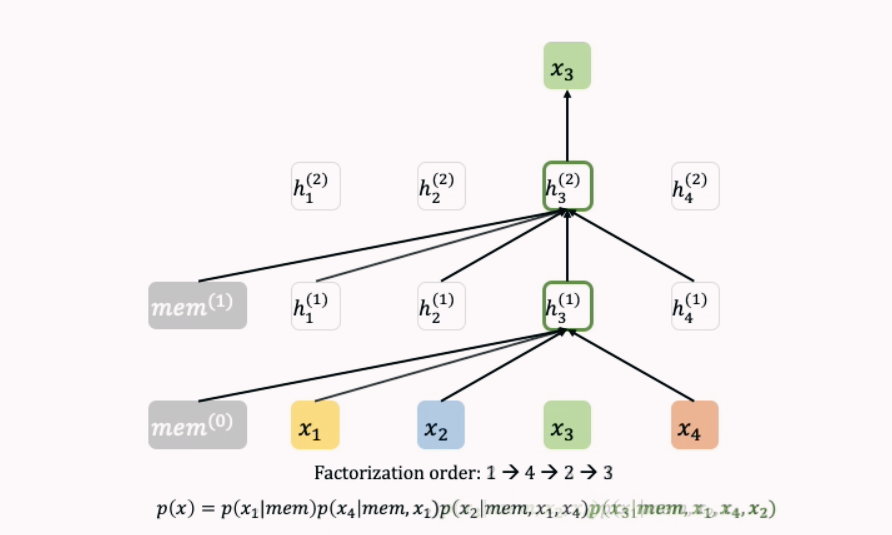
- 각 Token들은 원래 순서에 따라 Positional Encoding이 부여되기 때문에 모델은 x1 다음에 x2가 오는 것을, x2 다음에 x3가 오는 것을 학습 가능 (토큰의 절대적 위치와 어텐션 점수 활용)
- 순열을 모두 학습하기 때문에 양방향 context를 고려한 AR 방식으로 학습
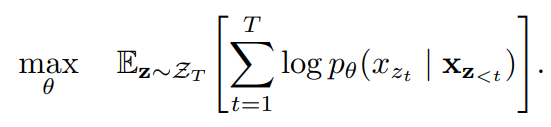
- ZT 는 길이가 T인 모든 가능한 순열의 집합
- xzt 는 특정 순열에서 t번째 위치에 있는 단어
- x(z<t) 는 특정 순열에서 t 이전까지 등장한 단어들을 의미합니다.
→ 따라서 위 식은 특정 순열에서 t번째 단어를 예측하는 확률을 최대화하고 이 확률들의 E(기댓값)를 최대화하도록 학습하는 의미를 지닙니다.
- 하지만 이 방식에도 문제점이 존재하는데, 타겟 위치에 따라 달라지는 정보를 학습할 수 없다는 것입니다.
- [2,3,1,4]의 경우 p(x1 | x2, x3)을 계산하기 위해 h(x2, x3)을 이용
- [2,3,4,1]의 경우 p(x4 | x2, x3)을 계산하기 위해 h(x2, x3)을 이용
- 결국 같은 representation을 이용해서 x1과 x4를 예측해야 되는 문제 발생
2-2) Two - Stream Self-Attention for Target Aware Representation
위처럼 기존 Transformer 구조를 사용한다면 고정된 Positional Encoding을 사용하기에 타겟 위치에 따라 달라지는 위치 정보를 학습할 수 없다는 문제가 발생합니다.
타겟 위치와 상관없이 동일한 확률 분포가 예측되어, Permutation 방식의 이점을 제대로 활용할 수 없습니다.
그래서 XLNet에서는 위 두 조건을 만족하기 위해 하나의 스트림 대신 두 개의 스트림을 사용합니다.
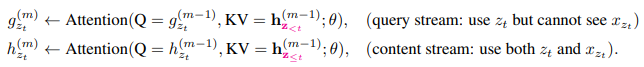
g_θ 는 쿼리 스트림으로, 이전 문맥과 타겟 단어의 위치까지만 포함하고
h_θ 는 문맥 스트림으로, 이전 문맥과 타겟 단어의 내용을 포함하도록
두 스트림을 분리해 문제를 해결합니다.
왜 위처럼 두 스트림으로 나누었냐면, 기존 Transformer(BERT, GPT)에서는 Self-Attention을 수행할 때 Query(Q), Key(K), Value(V)를 모두 같은 입력에서 가져왔습니다. 즉, 모델이 예측해야 할 단어를 이미 알고 있는 상태에서 학습하게 되는 문제가 발생할 수 있었던 거죠.
XLNet은 Query Stream과 Content Stream을 분리하여 이를 해결했습니다.
- Query Stream → 학습해야 할 단어를 감추고(Hidden), 문맥만 학습
- Content Stream → 학습해야 할 단어와 문맥을 모두 활용하여 정교한 정보 반영
- 두 개의 Stream을 사용하면 모델이 실제로 단어를 모르는 상태에서 문맥을 기반으로 예측할 수 있게 됨

- Query Representation (t 시점을 예측)
- 3 - 2 - 4 - 1 을 학습한다고 가정
- 3은 학습가능한 g_i = w 로 초기화되어 w만 가지고 학습을 진행
- 2는 먼저 나온 3의 hidden vector + 2의 위치 정보(w) ,,,

- Context Representation (t 시점 이후를 예측)
- 기존 Transformer처럼 토큰 정보만 활용해서 학습
- 가장 첫번째인 3을 예측할 때 이전 문백 정보 + x3의 문맥 정보
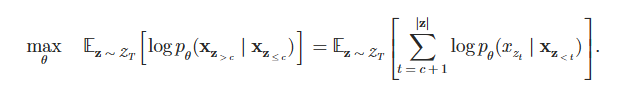
☑️ query, context stream 정리
t 시점의 토큰을 예측할 때 h(문맥정보) 는 g(위치정보)를 구할 때 쓰이고, t 시점의 토큰 x를 구할 때 쓰이고, 추가로 모든 순열에 대한 x 확률분포의 log likelihood 기댓값을 최대화하는 것이 XLNet 의 최종 목표입니다.
[4] Modeling
XLNet의 입력 구조는 BERT와 유사하지만, 몇 가지 중요한 차이가 존재합니다.
- Pre - training
- BERT와 유사하게 [CLS, A, SEP, B, SEP] 로 입력
- Seg A, B를 랜덤으로 샘플링하고 하나로 concat해 permutation 수행
- XL-net-Large는 NSP의 효과가 없어서 사용 X
- BERT는 절대적 segment encoding을 사용하는데 XLNet은 상대적 인코딩 개념을 사용
- 두 단어를 봤을 때 두 단어가 같은 segment인지 아닌지만 학습 → 절대적인 segment를 저장하지 않기에 확장성 Good
- Permutation 집합에서 하나의 Token을 예측할 때 마지막 K개의 예측만 사용함 (base 모델에서는 K = 6)
- 이를 통해 불필요하게 많은 연산을 하지 않고, 효율적인 정보만 학습할 수 있도록 최적화
| Model | BERT | XLNet |
| Training Objective | Masked Language Model (MLM) | Permutation-based Auto Regressive |
| Bidirectional Context | 가능 | 가능 |
| Next Sentence Prediction (NSP) | 사용 | 미사용 |
| Positional Encoding | 절대적 | 상대적 |
| Self-Attention Mechanism | Query, Key, Value 동일 | Query Stream, Content Stream 분리 |
| Long-term Dependency | 어려움 | Transformer-XL 기반으로 해결 |
[5] Experiments
사전 학습 시에 BERT와 동일하게 Bookcorpus, Wikipedia 데이터셋 (13GB) 을 활용하고 추가로 Giga5 (16GB), ClueWeb 2012-B (19GB), Common Crawl (110GB) 데이터셋을 활용했다고 합니다.
→ 사전학습 때 데이터를 이렇게나 많이 늘렸으니 당연히 성능이 오를수밖에 없는 느낌..?
1) RACE Dataset
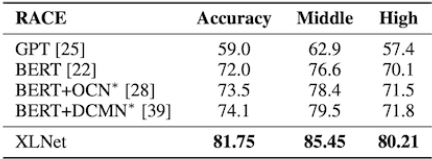
- Resoning에 대한 질문을 포함하는 가장 어려운 QA dataset 중 하나
- Sequence length를 640으로 fine-tuning 시켜 수행
2) SQuAD Dataset
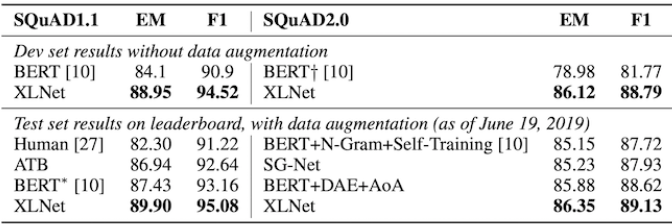
- SQuAD dataset에서도 꽤 큰 격차로 SOTA 달성
- 문장의 길이가 비교적 긴 Task라서 더욱 그렇지 않았나 싶음
3) GLUE Dataset
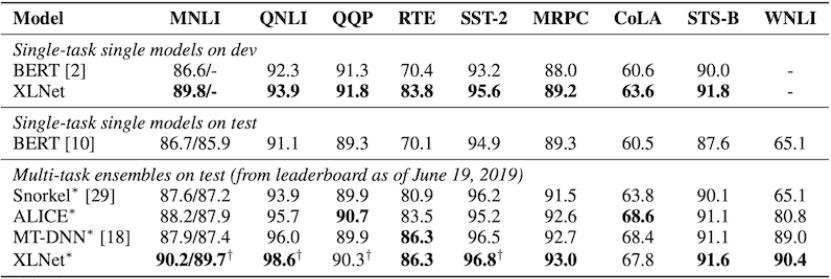
- 전체 9개의 Task 중 7개에서 SOTA 달성
4) Ablation Study
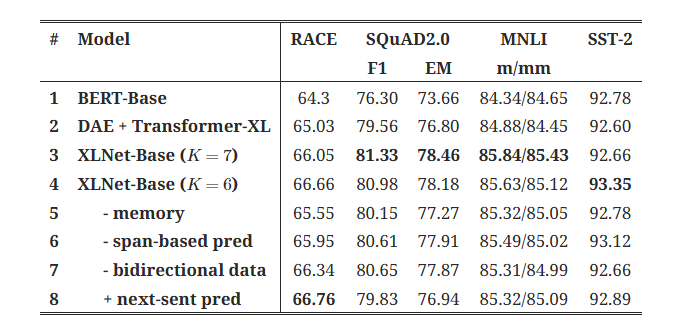
- XLNet에서 설계한 각 요소가 성능에 어떤 영향을 미치는지 조사
- DAE : Denoising Auto Encoding
- 1~4번째 행을 보면 Tranformer-XL, PLM 방식이 BERT 보다 XLNet 성능을 좋게 해준 주요 원인임을 알 수 있음
- 5번째 행처럼 메모리 캐싱을 제거했을 때 성능이 분명하게 하락했으며 특히 RACE benchmark 에서 두드러짐
- RACE가 다른 4개의 Task에 비해 가장 긴 문맥을 포함하는 Task이기 때문
- 6~7번째 행을 보면 Span based pred와 양방향 입력도 XLNet에서 중요한 역할을 함
- 8번째 행처럼 NSP가 꼭 성능 향상을 가져오지 않음 > 제거
[6] Conclusion
- XL-net은 AE + AR 의 단점을 보완하고 장점은 보존한 언어 모델
- Pre-training 단계에서 permutation을 활용해 학습
- 이로 인해 생기는 문제를 새로운 방식의 Transformer를 제시해 해결
- Transformer-XL에서 아이디어를 얻음 (같은 저자)
[7] Reference
https://arxiv.org/abs/1906.08237
https://youtu.be/v7diENO2mEA?si=zEH5MFi0IeobD6Du
https://jeonsworld.github.io/NLP/xlnet/
[논문리뷰] BERT 논문 리뷰
자, 오늘은 X:AI Seminar 2024에서 진행한 BERT 논문 리뷰를 가져왔습니다.해당 논문은 2019년에 발표되어 ELMO, GPT-1의 모델과 비교를 하면서 얘기를 시사하고 있습니다. 논문 : BERT, Pre-training of Deep Bidire
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] FILIP 논문 리뷰 (5) | 2024.07.23 |
|---|---|
| [논문리뷰] ALBEF 논문 리뷰 (2) | 2024.07.17 |
| [논문리뷰] T5 논문 리뷰 (0) | 2024.07.15 |
| [논문리뷰] CLIP 논문 리뷰 (0) | 2024.07.10 |
| [논문리뷰] Transformer 논문 리뷰 (0) | 2024.06.26 |
| [논문리뷰] MT-DNN 논문 리뷰 (0) | 2024.05.23 |
| [논문리뷰] BART 논문 리뷰 (2) | 2024.05.15 |
| [논문리뷰] BERT 논문 리뷰 (0) | 2024.04.30 |



