Faster R-CNN 논문 리뷰입니다.
본 논문은 2015년도에 등장한 논문입니다.

논문 : Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
저자 : Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun
[1] Background
여느 Faster R-CNN 모델 리뷰와 동일하게 R-CNN, Fast R-CNN의 모델 구조와 문제점을 찍먹하고 Faster R-CNN 리뷰를 하겠습니다.
Object Detection

그 전에 Object Detection Task에 대해 간단히 살펴보고 가겠습니다.
객체 탐지 Task는 말 그대로 이미지에서 객체가 어디에 있고, 그 객체가 무슨 객체인지 인식하는 작업이며,
라벨 값은 위 사진과 같습니다.
위에서 P는 해당 Bounding Box 안에 객체가 있다(1) / 없다(0) 를 나타내고
x, y, h, w는 각각 Bounding Box의 크기와 위치를 나타내는 값이며
c1, c2 등은 여러 클래스 중에 어떤 클래스인지 의미하는 정보입니다.
Bounding Box
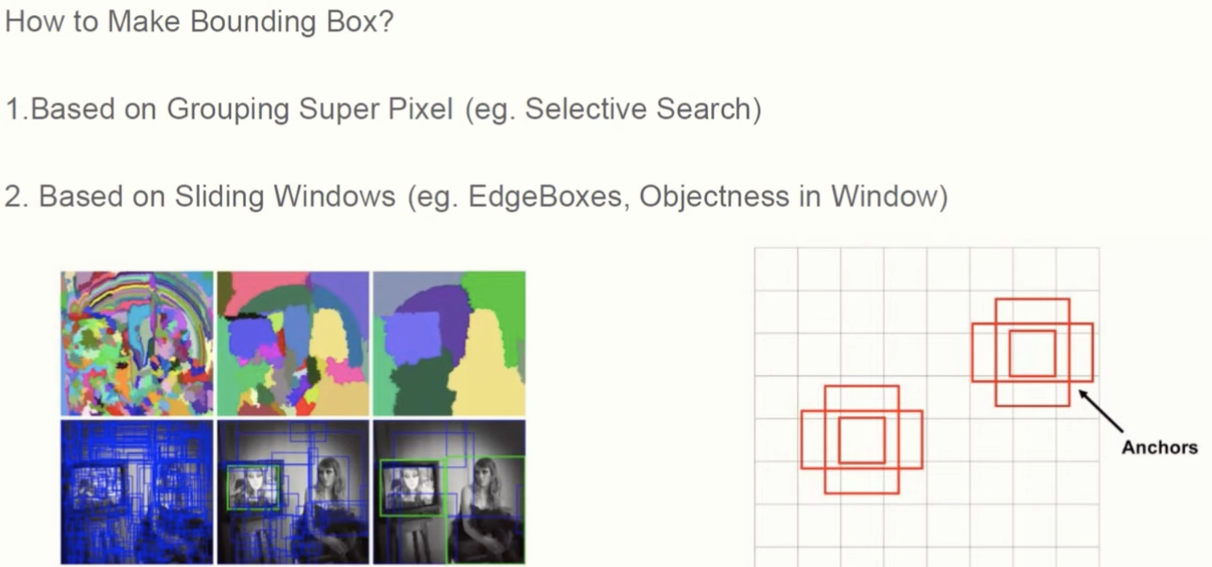
그렇다면 위에서 설명한 Bounding Box를 어떻게 생성한다는 걸까요?
기본적으로 Bounding Box를 생성하는 방법은 Selective Search와 같은 픽셀 단위 생성방식과 Edgeboxes, Anchors 처럼 Sliding Windows 로 만드는 방식으로 나뉩니다.
픽셀 단위로 생성된 BB는 작은 픽셀 단위로 쪼개고 비슷하거나 같은 색깔끼리 점점 뭉쳐지면서 Segment 되면서 생성되고 Sliding Windows 로 생성된 BB는 한 단위씩 이동하면서 생성됩니다.
R-CNN
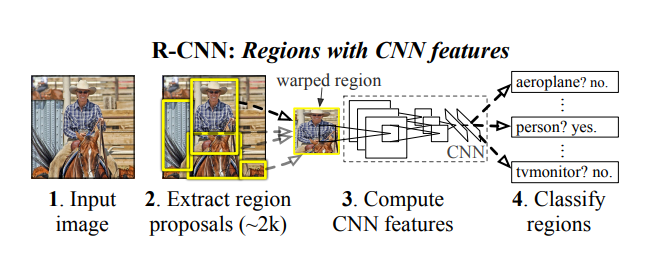
R-CNN은 Region Proposal + CNN 구조의 모델입니다.
그래서 이제 Region Proposal의 개념이 등장하는데 Region Proposal이란 탐지하고자 하는 물체가 속할 가능성이 있는 ROI 영역들을 찾는 작업을 의미합니다.
R-CNN에서는 Selective Search 알고리즘을 활용해 약 2,000개의 ROI를 Input Image로부터 얻어내죠.
여기서 R-CNN의 문제점이 여럿 등장합니다.
1) Input Image 로부터 약 2,000개의 Bounding Box를 생성하는데 이 과정이 매우 오래걸리며, 심지어 GPU로도 안돌아가고 CPU로 연산을 수행해야 한다.
2) Bounding Box를 CNN에 입력하기 위해 이미지를 동일한 크기로 warp해줘야 하는데 이 과정에서 정보 손실이 발생한다.
3) 생성된 모든 Bounding Box를 전부 CNN에 입력해서 Classification을 하기 때문에 연산량이 많이 필요하다.
그래서 이를 보완하기 위해 Region Proposal과 CNN 과정을 분리하지 말고 한 번에 end-to-end 방식으로 진행한 모델이 Fast R-CNN입니다.
Fast R-CNN
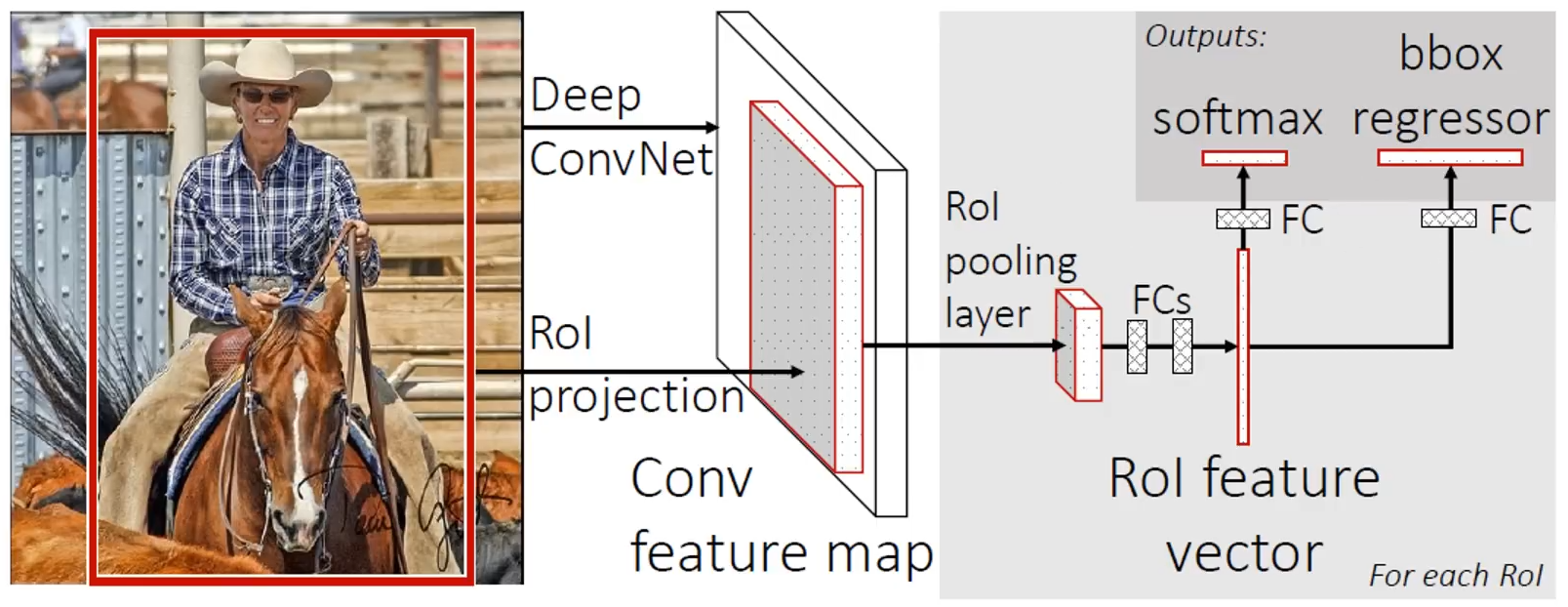
Fast R-CNN에서는 R-CNN과 다르게 ROI 영역을 모두 각각 개별 CNN에 입력하지 않고 ROI 영역을 추출만 한 후 (위치만 알아낸 후) 그대로 CNN에 입력하고 ConvNet을 통과한 Feature Map에 Projection(사영)합니다.
이후, ROI Pooling Layer와 FC Layer를 지나서 분류 Task(Softmax), 회귀 Task(bbox regressor)에 쓰이게 됩니다.
Fast R-CNN에서 가장 핵심은 ROI Pooling Layer인데요.
ROI Pooling Layer
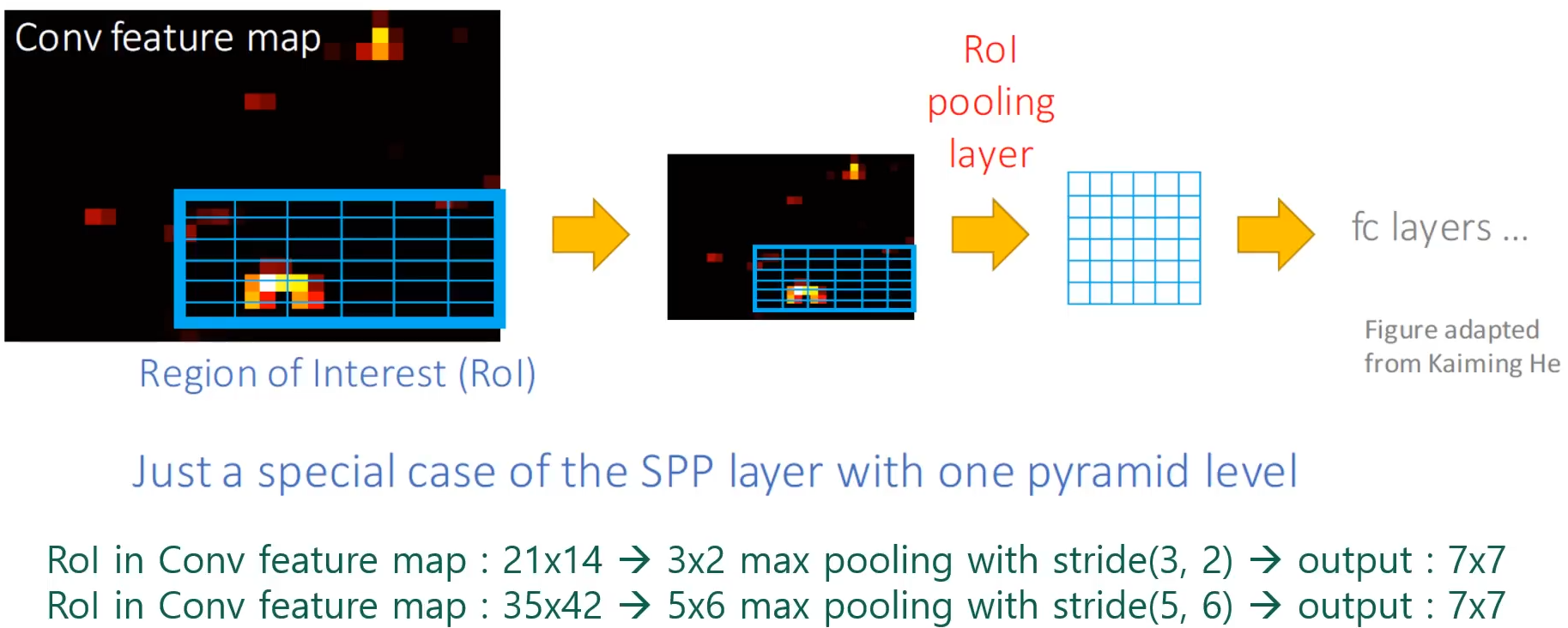
ROI Pooling Layer란, ConvNet를 지난 Feature Map에 사영된 ROI 영역에 대해 Pooling 작업을 거쳐서 FC Layer에 입력할 수 있도록 크기를 조정하는 역할을 하는 Layer입니다.
위와 같은 구조로 되어 있는 Fast R-CNN에도 여전히 문제점은 존재하였습니다.
1) ROI 영역을 선정하는 Region Proposal은 여전히 Selective Search 방식을 사용 중이다. (여전히 CPU)
2) R-CNN보다 빨라지기는 했지만 과연 충분히 빨라진 것인가?
[2] Faster R-CNN
그래서 Faster R-CNN은 Region Proposal Network를 Selective Search 방식이 아니라 모델 내에서 같이 수행되도록 만들어보자는 개념이 추가된 모델입니다.
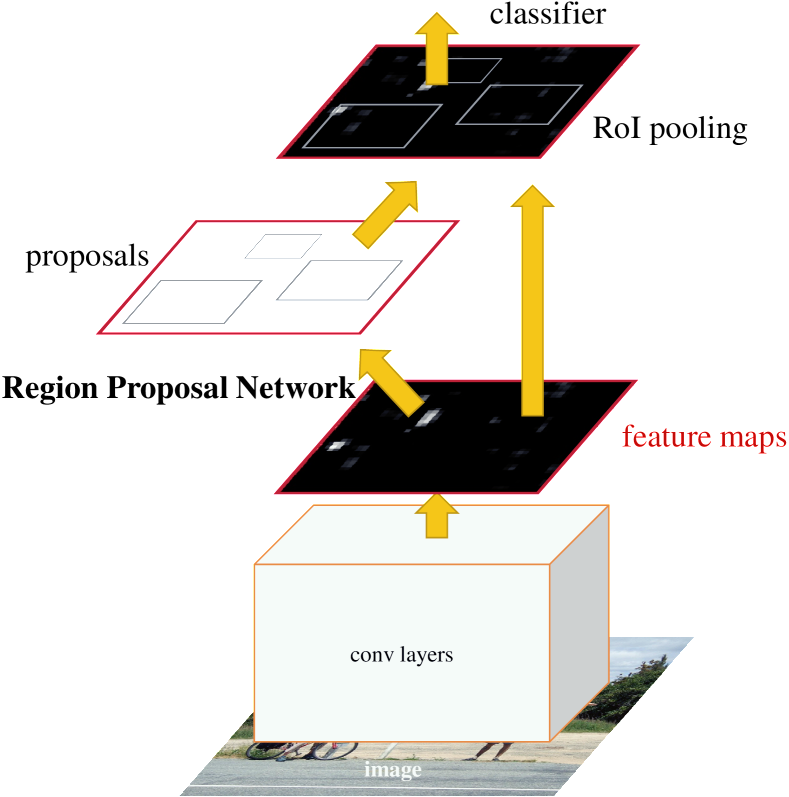
모델 구조는 RPN + Fast R-CNN 구조로 되어 있어 Faster R-CNN은 기존 Fast R-CNN에 Region Proposal Network를 추가한 모델입니다.
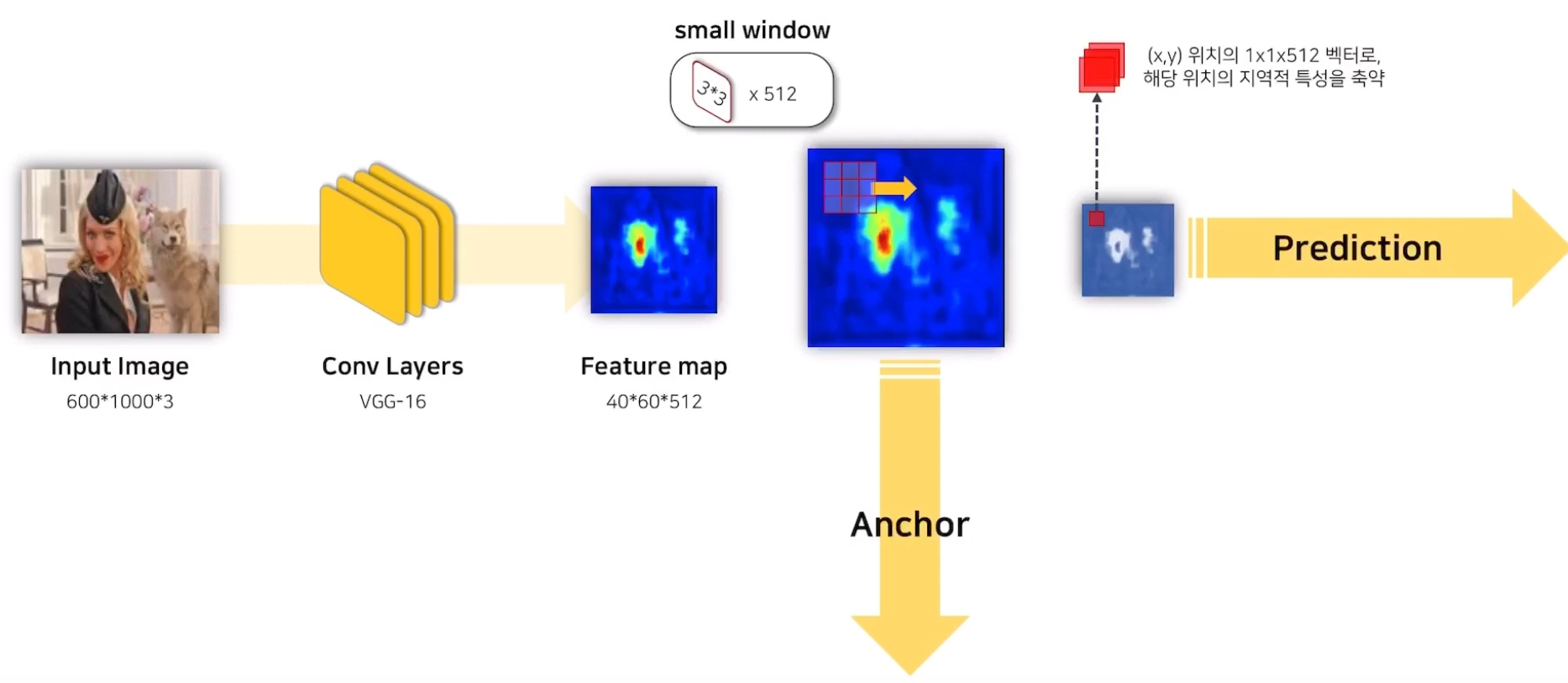
RPN은 Conv Layers를 지난 Feature Map에 3x3 size의 small window를 Sliding 시켜서 Anchor와 Feature Map을 생성하는데, 이 때 1x1 padding이 수행되어 Feature Map의 크기는 바뀌지 않습니다.
그래서 Prediction에 쓰이는 Feature Map의 1x1 크기의 pixel은 이전 Feature Map의 3x3 지역정보를 축약하고 있다고 이해하면 될 것 같습니다.
Anchor Box
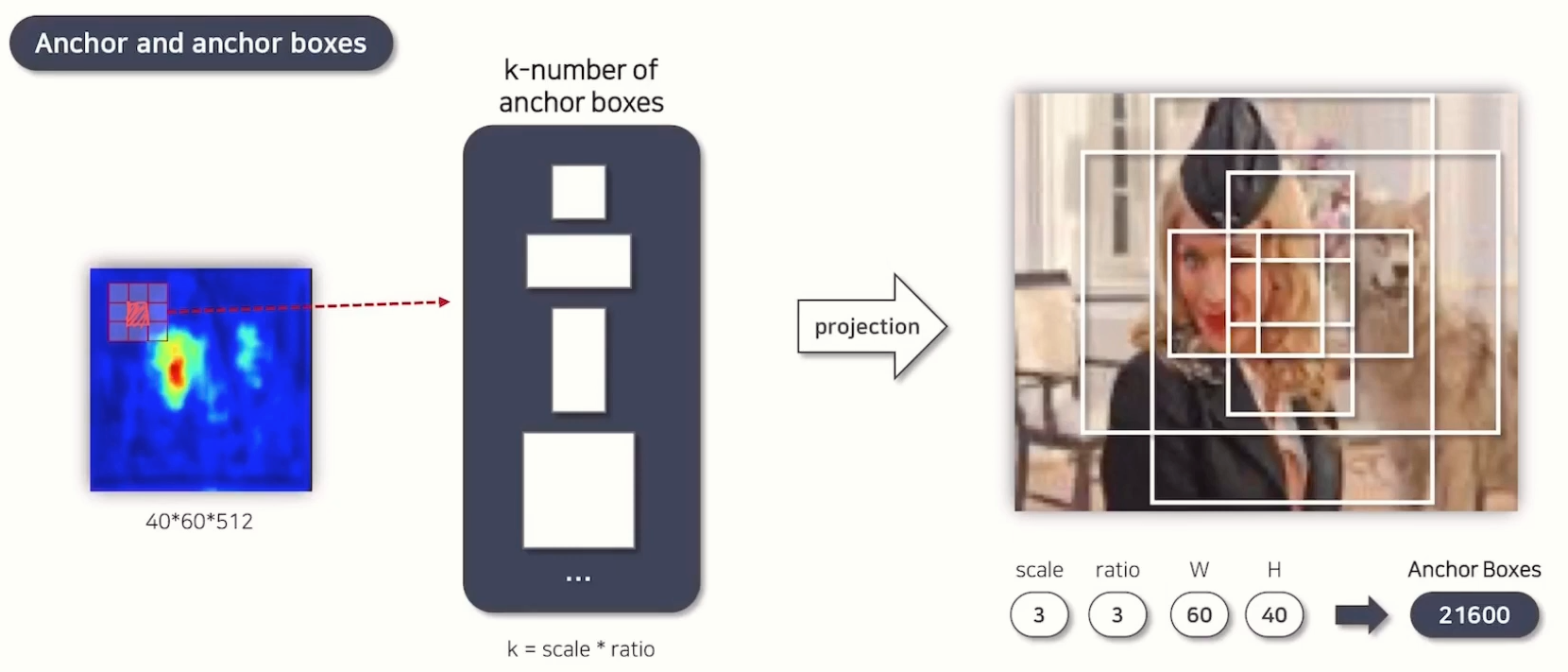
위 사진의 왼쪽의 3x3 layer 중 가운데의 1x1 pixel을 anchor라고 부릅니다.
위에서 1x1 padding이 수행된다고 언급했는데 이 덕분에 모든 픽셀에 sliding window가 적용됩니다.
그리고 각 앵커 박스들은 scale과 ratio라는 값에 의해 생성이 됩니다.
- scale : 앵커 박스의 크기를 결정 (작거나 크거나)
- ratio : 앵커 박스의 너비와 높이 간 비율을 결정 (정사각형, 직사각형 등등)
그래서 본 연구에서는 다양한 크기와 형태의 객체(작은, 중간, 큰 객체 / 정사각형, 세로로 긴, 가로로 긴)를 효과적으로 탐지하기 위해 3x3 조합의 많은 anchor box를 생성합니다. (성능과 계산 효율 간 균형을 맞춘 설정이라고 합니다)
따라서 이전 Feature Map의 크기가 40x60이었고 scale과 ratio를 각각 3으로 한다면
생성되는 anchor boxes의 개수는 21,600개가 됩니다.
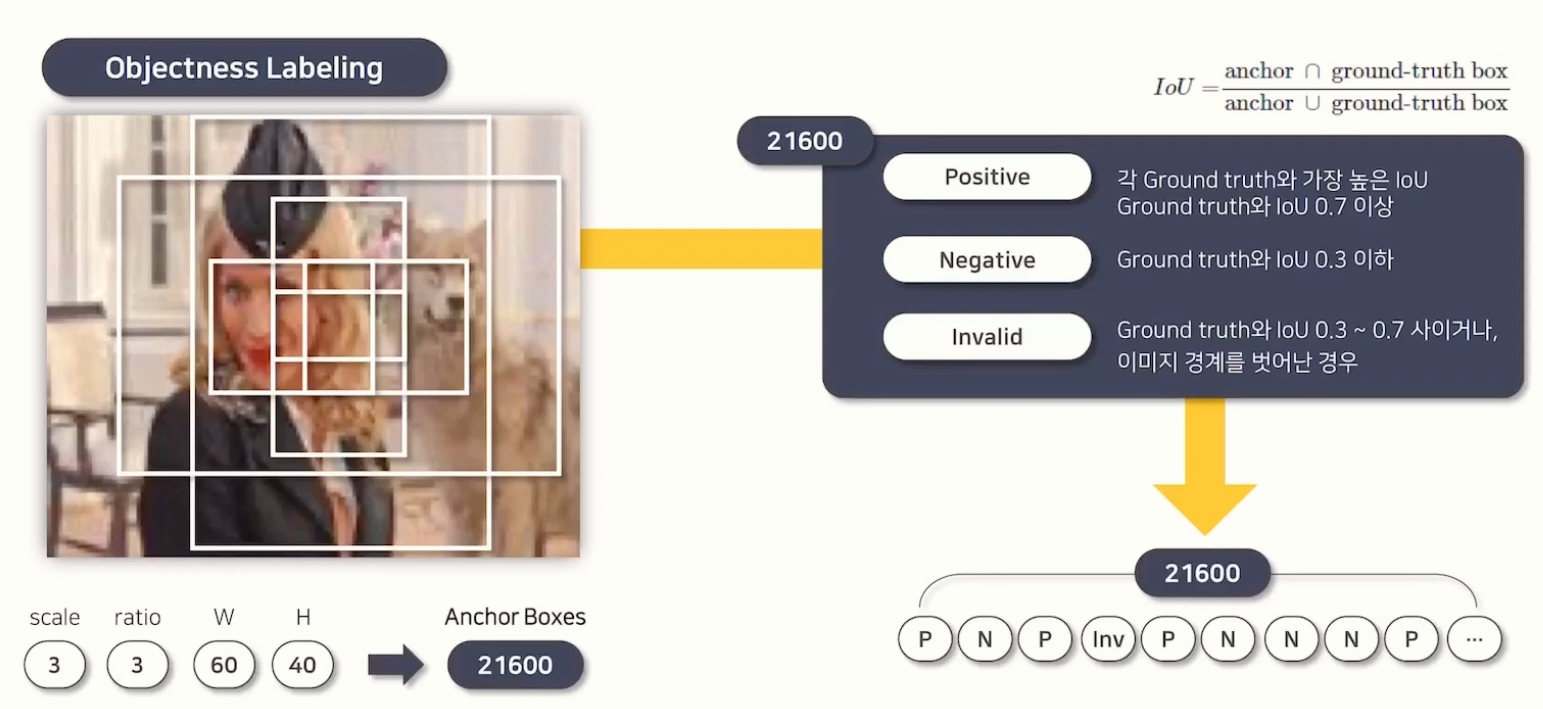
생성된 Anchor Box 들은 나중에 Prediction을 위한 정답으로 쓰이기 위해 라벨링이 우선 되어야 합니다.
라벨링은 Ground Truth (이미 정해진 정답)와 비교해서 IoU 수치가 0.7 이상이면 Positive Label, 0.3 이하라면 Negative Label로 라벨링을 해주고 그 사이이거나 이미지 경계를 벗어난 경우 Invalid Label로 라벨링됩니다.
만약, 가장 IoU 수치가 높은 앵커박스가 0.7 이하라면 가장 높은 IoU의 Anchor Box를 그냥 Positive label로 해준다고 합니다.
그래서 이를 Objectness Labeling이라고 부르고
이후에, Positive Anchor Box에 한해 Ground Truth와 비교해 어느 위치에 있는지 알려주는 Bbox offset labeling을 수행합니다.

Anchor Box는 사전 정의된 고정된 위치와 크기를 가지기 때문에, 실제 Ground Truth Box와 정확히 일치하지 않을 가능성이 높기 때문에 Anchor Box를 얼마나 이동시키고 크기를 조정해야 하는지에 대한 정보를 알기 위해서 Bbox Offset Labeling을 수행합니다.
구체적으로 Positive Anchor Box에 대해 Ground Truth Box와의 차이를 계산하여 Offset 레이블(tx,ty,tw,th)을 정의하고
모델이 예측한 예측값과 정답 레이블 간 차이를 계산해 Smooth L1 Loss를 계산합니다.
그래서 이 회귀값을 가지고 객체의 정확한 위치와 크기를 알 수 있도록 하는 역할도 수행합니다.
결론적으로, Objectness Labeling, Bbox offset Labeling 의 두 가지 라벨링이 출력됩니다.
각 라벨링은 21,600 차원의 벡터가 됩니다. (각 앵커박스마다 라벨이 붙을테니까요)
그리고 이 라벨값은 이 후 RPN에서 예측할 정답 데이터로 사용됩니다.
💡여기서 21,600차원의 벡터가 된다는게 헷갈렸는데,
21,600개의 앵커박스에 각각 P/N/I 라벨이 붙고, P 라벨에 한해 Bbox offset label이 붙으니 앵커박스 개수만큼의 차원 벡터가 생성된다는 의미로 이해했습니다.
Prediction Network
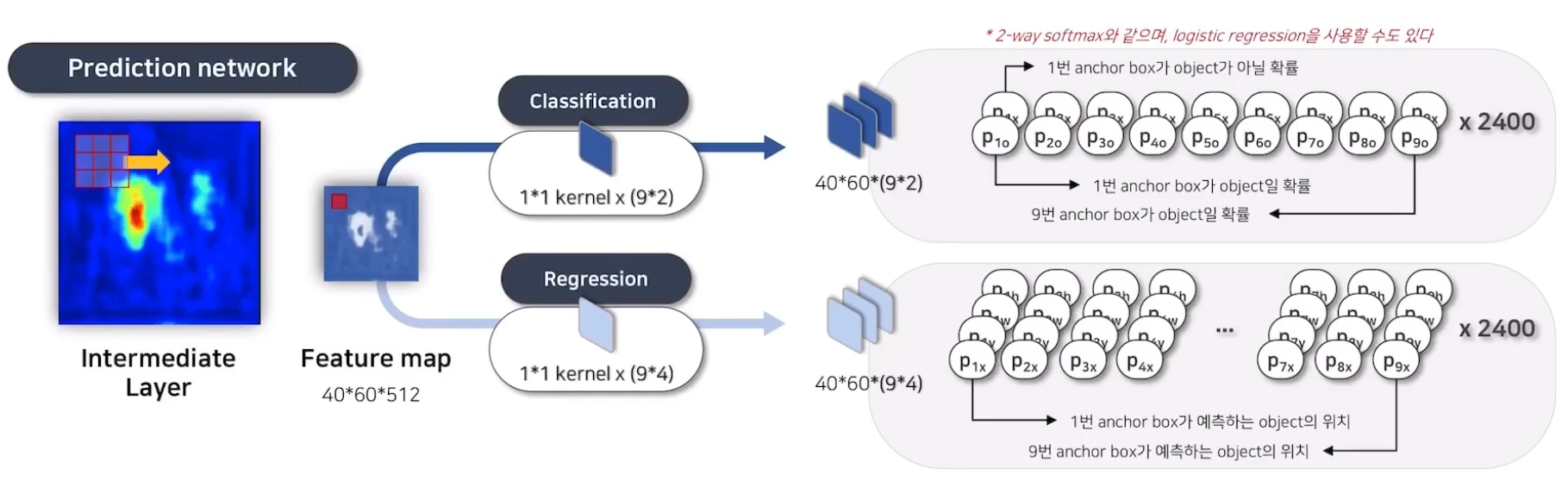
지금까지 앵커 박스 생성에 대해서 얘기했으니 실제로 모델이 예측하는 Prediction Network를 보겠습니다.
Intermediate Layer의 Feature Map이 3x3 filter를 거쳐서 생성된 Feature Map의 1x1 pixel은 이전 Layer의 3x3 정보를 담고 있다고 위에서 언급했습니다.
해당 Feature Map을 1x1 Filter에 통과시키는 1x1 conv 연산을 수행해 채널 수를 줄입니다.
여기서도 Anchor Box와 동일하게 분류 / 회귀로 나뉘어지며,
분류쪽은 Anchor Box가 Object 일 확률에 대해 2개의 채널로 만듭니다.
근데 아닐 확률과 맞을 확률 두 개로 나눴기 때문에 하나로 합칠 수 있다고(LR 쓸 수 있다고) 논문 뒷편에서 이야기하고 있습니다.
회귀쪽은 Anchor Box가 예측하는 Object의 x, y, w, h 위치 정보의 4채널 벡터를 출력합니다.
따라서, RPN은 입력으로 Feature Map과 Anchor Box를 받아서, 각 앵커 박스에 대해 두 가지를 예측합니다.
- Objectness Score : 각 앵커 박스가 객체를 포함할 확률을 예측
- Bounding Box Offset : Positive로 분류된 앵커 박스에 대해, Ground Truth Box와 얼마나 차이나는지 위치, 크기를 예측
Loss Function

Loss Function은 다음과 같고
기본적으로 분류 문제의 Log Loss와 회귀 문제의 Smooth L1 Loss를 더한 값입니다.
분류 Loss : 각 앵커 박스에 대해 객체가 있을 확률을 계산한 Score와 Label값 간의 Cross-Entropy Loss
회귀 Loss : Positive Anchor Box에 대해 예측된 Offset과 Ground Truth Offset 간의 Smooth L1 Loss
라고 정리할 수가 있겠고, 결론적으로 Anchor를 매개체로 활용해 Ground Truth Bounding Box와 최대한 가까운 Proposal을 생성하도록 학습되는 것이 Loss Function의 궁극적인 목표라고 할 수 있겠습니다.
추가적으로 람다는 두 Loss Function의 비율을 어느 걸 더 중점적으로 볼 것인가 조정하는 하이퍼파라미터입니다.
Sharing Features for RPN and Fast R-CNN
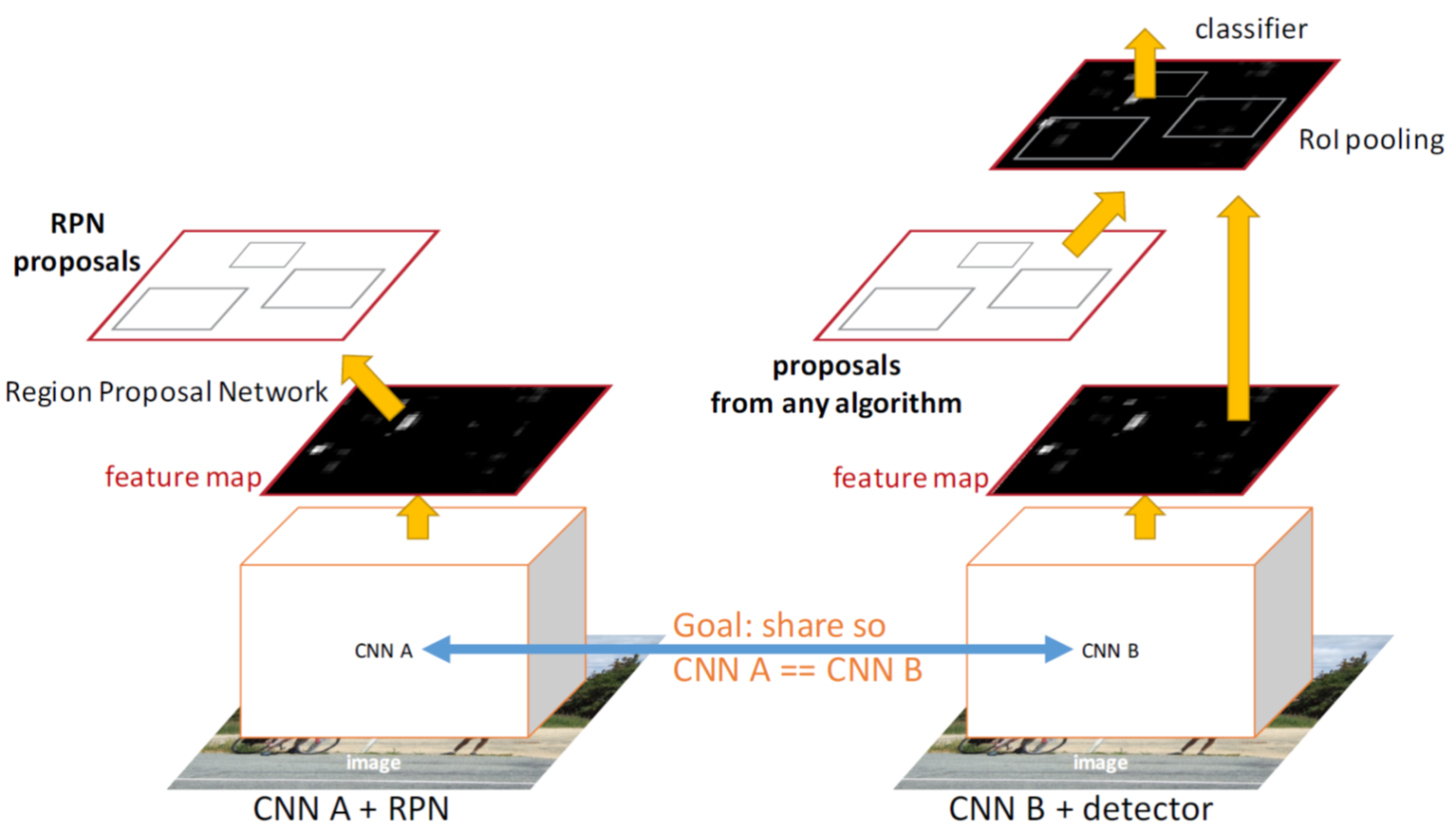
지금까지 설명한 RPN을 실제로 Fast R-CNN과 결합하는 부분입니다.
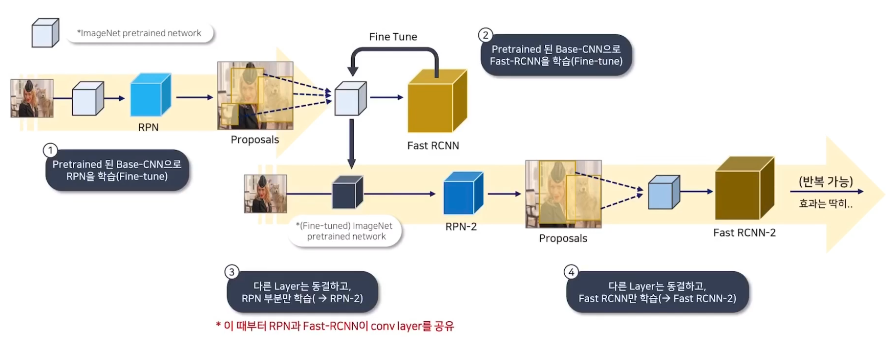
RPN과 Fast R-CNN이 독립적으로 학습하면 Conv Layer의 가중치를 공유할 수 없기 때문에 4단계에 걸쳐 학습이 진행됩니다.
1) RPN을 ImageNet으로 사전학습된 모델로 Fine Tuning
2) 1차 학습된 RPN의 Proposal 을 활용해 Fast R-CNN을 별도로 학습
3) Fast R-CNN으로 학습된 네트워크를 사용해 RPN을 재학습 (공유된 Conv Layer는 고정)
4) 공유된 Conv Layer는 고정하고 Fast R-CNN의 고유 Layer만 다시 Fine Tuning
Implementation Details
모델 학습을 위해 몇 가지 세부 사항을 준비했다고 논문에 제시되어 있습니다.
1) 모든 이미지를 짧은 변의 길이가 600 pixel이 되도록 Resize
2) Anchor Box는 Sliding Window 방식을 활용해서 생성
3) 리사이즈된 이미지에서 ZF 및 VGG 네트워크의 마지막 Convolution Layer의 Stride는 16 (높이면 정확도, 낮추면 속도에 강점)
4) 앵커 박스는 3가지 Scale(128, 256, 512)와 3가지 Ratio(1:1, 1:2, 2:1)로 생성됨
5) 보통 ROI를 생성할 때 이미지 피라미드 방식을 사용하기도 하는데 이러한 방식은 각각 다른 이미지, 필터 크기에 의존하다보니 파라미터들이 공유되지 않고 속도도 느림
6) Faster R-CNN은 Receptive Field보다 큰 영역도 예측할 수 있다고 언급 (Anchor Box가 생성될 때 실제 이미지 바깥 영역도 포함할 수 있기 때문에 가능)
7) 하지만 이미지 영역을 벗어나는 Anchor Box는 크기를 이미지 영역에 맞게 특별히 조정해야 함
8) RPN이 Object에 대해 중복되는 Bounding Box를 생성하기 때문에 NMS 알고리즘(IoU threshold : 0.7)을 적용
[3] Experiments
PASCAL VOC 2007 Benchmark
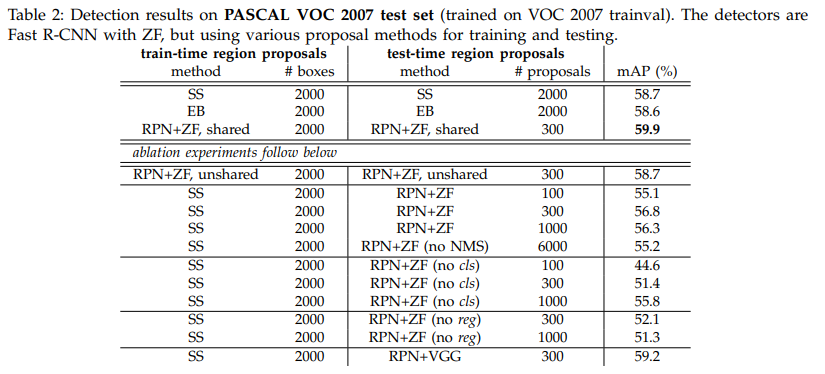
- RPN과 Fast R-CNN을 같이 쓰면서 Selective Search보다 훨씬 빠르고 높은 정확도를 달성.
- RPN+ZF가 SS보다 적은 proposal로 높은 mAP 기록 (59.9%)
- 4-Step Training의 2단계에서 멈춘 경우, 즉 가중치가 공유되지 않는다면 58.7%로 약간의 성능 하락
- Detection Network에 Fine Tuning된 feature로 RPN을 Fine Tuning할 때 proposal의 정확도가 향상
- Proposal 중 top 100개만 사용한 경우와 6,000개 모두를 사용한 경우(no NMS) 성능이 유사
- NMS가 mAP를 훼손하지 않고 필요한 작업임을 입증
- RPN에서 생성하는 cls, reg label을 각각 없앴을 때 mAP가 급격히 감소
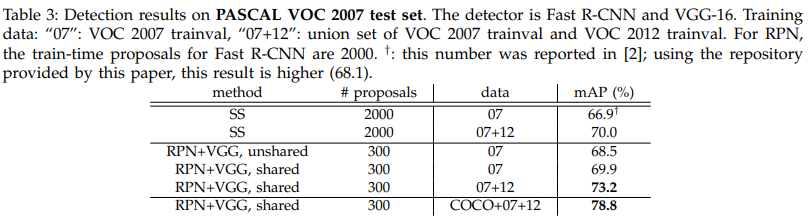
위에서 언급한 ZF 모델이 아닌 VGG16모델을 활용했을 때 더 높은 성능을 달성했습니다.
COCO 데이터셋까지 추가 학습 시에 78.8% mAP로 성능이 크게 증가했습니다.

학습에 소요된 시간을 봤을 때 Selective Search보다 훨씬 적은 양의 proposal을 생성하기 때문에 속도 측면에서 큰 향상을 이루어냈고, ZF-net으로 학습한 모델의 경우 17 FPS를 달성하였습니다.
*17 FPS = 1초에 17장의 이미지를 처리할 수 있다는 의미
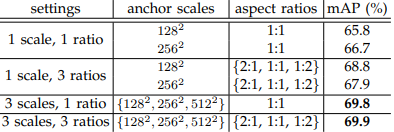

다음은 하이퍼파라미터 얘기인데, scale과 ratio를 각각 3개씩 해서 k = 9의 하이퍼 파라미터가 있었고, 회귀식에 곱해주는 람다 의 하이퍼파라미터가 존재했습니다.
결론적으로, 앵커 박스를 다양한 크기로 생성하는 것이 성능 향상에 도움이 되었고, 람다 값은 0.1처럼 매우 낮은 값이 아니라면 성능에 크게 영향을 많이 주지는 않네요.
[4] Conclusions
- Faster R-CNN은 Region Proposal과 Object Detection 단계를 통합한 모델로, 기존 Selective Search 방식의 문제점을 해결하기 위해 등장함
- Faster R-CNN에서 제시하는 RPN은 Conv Layer의 가중치를 Fast R-CNN과 공유하여 빠르고 좋은 성능을 낼 수 있었음
- Anchor Box를 생성하고 이를 라벨값으로 활용해 예측
- 거의 실시간 속도로 동작하며 Anchor Box의 품질과 Object Detection Task 정확도를 모두 개선함
[5] References
https://www.youtube.com/watch?v=ZhvU7D_qKO8&t=1367s
https://www.youtube.com/watch?v=HmJWvwIpW5g&t=595s
https://oi.readthedocs.io/en/latest/computer_vision/object_detection/faster_r-cnn.html
[논문리뷰] SPPNet 논문 리뷰
SPPNet 논문 리뷰입니다.본 논문은 2014년도에 등장한 논문입니다. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 저자 : Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun [1] Introduction이번
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] RoBERTa 논문 리뷰 (4) | 2025.02.02 |
|---|---|
| [논문리뷰] GPT-1 논문 리뷰 (3) | 2025.01.26 |
| [논문리뷰] YOLO 논문 리뷰 (2) | 2025.01.25 |
| [논문리뷰] U-Net 논문 리뷰 (3) | 2025.01.23 |
| [논문리뷰] ELMo 논문 리뷰 (2) | 2025.01.19 |
| [논문리뷰] Attention 논문 리뷰 (0) | 2025.01.16 |
| [논문리뷰] MoblieNet 논문 리뷰 (2) | 2025.01.12 |
| [논문리뷰] SPPNet 논문 리뷰 (0) | 2025.01.08 |



