안녕하세요. 이번 포스팅에서는 올해 1학기에 진행했던 프로젝트에 대해서 얘기해보려고 합니다.

프로젝트 주제 : <제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트>
분야 : NLP, Translation, Deep-Learning, STS
GitHub - junhoeKu/Jeju-Translation: 제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 (알고리즘 | 비
제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 (알고리즘 | 비정형 | NLP | 딥러닝 | 기계번역 | 음성인식 | 멀티모달) - junhoeKu/Jeju-Translation
github.com
1. 주제 선정
처음으로 주제 선정입니다. 해당 프로젝트를 시작했을 때는 NLP 프로젝트를 해본 경험이 있는 사람은 저 뿐이었고, 나머지 팀원분들은 NLP의 N자도 모르는 상황이었어요. 그래서 바로 다음 세션 때까지 Transformer 논문을 각자 공부해오고 데이터 EDA 좀 해보고 오자고 얘기했었죠. 지금 생각해보면 갑자기 팀장이 과제를 내려줘서 팀원들이 당혹스러웠을 것 같긴 하네요.. ㅎㅎ
저는 데이터 스윽 보고 러프하게 전체 코드 로직을 짜오기로 했었습니다.
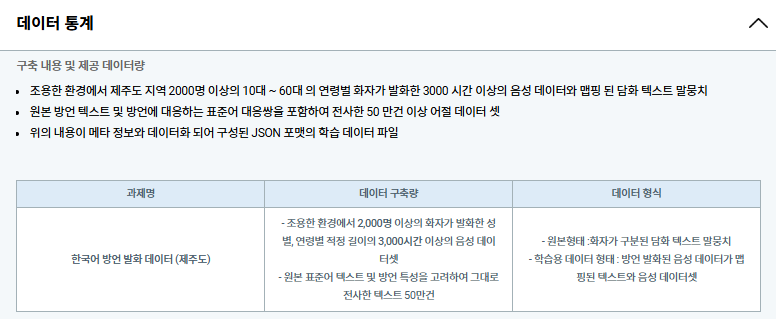
참고로 사용한 초기 데이터는 AI-Hub의 방언 데이터였습니다.
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
www.aihub.or.kr
도배하자 도메인의 LLM 개발 프로젝트를 경험하면서 스스로 많이 부족하다는 것을 느끼고 이번 프로젝트를 시작하기 전까지 언어 모델 공부를 나름 좀 했습니다. 그 중 인상적이었던 것은 언어 모델은 BERT와 GPT 계열로 나뉘고 각자 분석 혹은 생성 Task에 특화되어 있다는 것이었습니다. 같은 NLP라도 너무 다양한 Task가 있음을 알게 된 거죠.
이와는 별개로 초심자들이 시도해보기에 너무 어렵지 않고 흔하지 않은 (제가 살짝 홍대병이 있어서.. ㅎㅎ) 프로젝트를 탐색하던 중에 아래의 블로그를 발견하였습니다. 제주어 번역 Task로 주제를 정하게 된 계기는 바로 아래 블로그였습니다. 마침 우연의 일치로 저희 팀원 중에 한 명이 제주도 출생이었던 것도 한 몫 했구요.
[자연어 개인 프로젝트] 제주도 사투리를 번역하자 (1)
자연어 NLP 양방향 번역 모델 생성하기 안녕하세요 머킹입니다. 프로젝트를 진행하면서 얻는 것 또한 많았지만 개인 프로젝트를 (어떻게든) 완성해서 의미 있는 결과를 얻고 싶다는 생각이 들었
machinelog.tistory.com
게다가 흥미 위주의 주제일 뿐만 아니라 세계유네스코문화유산으로 지정된 제주도 방언을 보존하고 소멸 중엔 제주어를 되살리는 의미 있는 주제라고도 받아들였습니다. 아래 사진을 보면 제주어를 보존하기 위해 어린이들에게 가르치고 있죠.

그래서 제주어를 보존하는 마음 + 시도해보기 적당한 Task 였던 점을 생각해서 해당 프로젝트를 시작하게 되었습니다.
2. 데이터셋 EDA
제주어 번역 프로젝트에서 제가 가장 처음으로 한 일은 데이터셋 EDA였습니다.
데이터셋이 어떻게 생겼는지 알아야 써먹을 수 있을테니까요.
사실 EDA 했었던 그래프 파일이 있었는데 어디갔는지 안보이네요.. 허허
그래서 일단 행이 약 50만 건이었던 텍스트 데이터를 가지고 학습을 수행했었습니다!
이 전까지는 판다스 패키지를 사용해서 데이터프레임 형태의 데이터만 다뤄봤는데 해당 데이터는 JSON 데이터더라구요.
정말 사소한 거지만 이 프로젝트에서 처음 JSON to dataframe을 해봤습니다 ㅎㅎ
아래는 그 코드입니다!
import json
import pandas as pd
## 필요한 speaker_id, form, standard_form, dialect_form, isDialect 부분만 추출
def load_and_extract_data(file_path):
## json 파일 로드
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
## 발화 탐색
utterances = data['utterance']
extracted_data = []
for utterance in utterances:
speaker_id = utterance['speaker_id']
form = utterance['form']
standard_form = utterance['standard_form']
dialect_form = utterance['dialect_form']
isDialect = any(eojeol['isDialect'] for eojeol in utterance['eojeolList'])
utterance_data = {
'speaker_id': speaker_id,
'form': form,
'standard_form': standard_form,
'dialect_form': dialect_form,
'isDialect': isDialect,
}
extracted_data.append(utterance_data)
return extracted_data
그래서 폴더 내의 모든 json 파일에 대해 위 함수를 활용해서 데이터프레임으로 변형하였고, 이를 학습에 사용했습니다.
아래처럼 말이죠.

[프로젝트] 데이콘 주관 도배하자 질의응답 처리 언어모델 개발 공모전 리뷰
이번에 학회 프로젝트로 데이콘에서 주관하는 도배하자 질의응답 처리 언어모델 개발 공모전에 참여하였다.프로젝트 발표는 끝났지만 아직 대회 종료일이 남아, 대회 종료일까지는 열심히 달
dangingsu.tistory.com
3. 데이터 전처리
데이터를 적절히 가져왔다면 이제 전처리, 즉 가공을 할 시간입니다.
데이터 전처리는 특별한 기술을 사용하지는 않았고 일반적으로 사용되는 방법들을 활용하였고,
제주어 특성을 반영한 전처리를 추가로 해주었습니다.
전처리 기법
- 결측치 & 불용어 제거 : 학습에 방해되는 결측치, 불용어를 제거합니다.
- 발화 길이 조정 : 모델 입력 길이에 맞게 발화 길이를 조정합니다.
- 오탈자 교정 : 더 정확한 번역을 위해 오탈자를 교정합니다.
- 제주어 특성 및 문법 반영
- 단어 매핑 : 돼지는 도새기, 감자는 지슬 등 특정 단어가 잘 매핑되어 있는지 확인합니다.
- 발음 교정 : 제주어는 '되'를 '뒈'로 발음하는 경향이 있어 이 부분을 세밀하게 조정합니다.
- 받침 교정 : 제주어는 쌍시옷 받침이 올 수 없다고 하여 '쌍시옷' 받침을 '시옷'으로 변환합니다.
4. 모델 선택 및 파인튜닝
모델은 한글로 사전 학습되어 있는 BART 계열 모델, KoBART를 활용하였습니다.
gogamza/kobart-base-v2 · Hugging Face
Model Card for kobart-base-v2 Model Details Model Description BART(Bidirectional and Auto-Regressive Transformers)는 입력 텍스트 일부에 노이즈를 추가하여 이를 다시 원문으로 복구하는 autoencoder의 형태로 학습이 됩니다.
huggingface.co
위 모델을 선정한 이유는 BART 모델이 번역 Task에 특화된 모델이기도 하고, 무엇보다 한국어로 학습이 잘 되어 있었기 때문입니다. 다른 모델들보다 한국어를 잘 이해하고 모델 크기도 그렇게 크지 않아 빠르게 실행가능한 점도 장점이었구요.
위 모델 외에도 T5 계열 모델이나 제주어로 특별히 학습된 JeBERT라는 모델도 학습시켜서 Inference 해봤는데 성능이 별로여서 사용하지 않았습니다.
아래는 데이터셋 전처리를 포함한 초기 파인튜닝 코드입니다!
import transformers
import torch
import pandas as pd
import numpy as np
import os
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, Seq2SeqTrainingArguments, Seq2SeqTrainer
from tqdm.notebook import tqdm
from datasets import Dataset, DatasetDict
import accelerate
import transformers
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
## 모델과 토크나이저 로드
model_name = "gogamza/kobart-base-v2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
train_data = pd.read_csv('data.csv')
## 결측치 제거
train_data = train_data.loc[train_data.standard_form.notnull()]
## 발화 길이가 3 이하인 발화 제거
train_data['form_len'] = train_data.standard_form.apply(lambda x : len(str(x)))
train_data = train_data.loc[train_data.form_len > 3]
## form에 # 있는 경우 제거
train_data.form_샵 = train_data.form.apply(lambda x : 1 if '#' in x else 0)
train_data = train_data.loc[train_data.form_샵 == 0]
## form에 & 있는 경우 제거
train_data.form_앤드 = train_data.form.apply(lambda x : 1 if '&' in x else 0)
train_data = train_data.loc[train_data.form_앤드 == 0]
## 최대 길이 64로 지정
## 아래에서 데이터 포맷팅하는데 max_length가 64기 때문에 실행
train_data = train_data.loc[train_data.form_len <= 64]
## 제주어 토큰, 표준어 토큰 정의하기
jeju_token = "[제주]"
standard_token = "[표준]"
## 양방향 데이터 리스트 생성
bidirectional_data = []
for dialect, standard in zip(train_data['dialect_form'], train_data['standard_form']):
## 토큰이 [제주] 일 경우 제주어 -> 표준어
bidirectional_data.append({
"source": jeju_token + " " + dialect,
"target": standard
})
## 토큰이 [표준] 일 경우 표준어 -> 제주어
bidirectional_data.append({
"source": standard_token + " " + standard,
"target": dialect
})
## 데이터 토크나이징
tokenized_data = []
for item in bidirectional_data:
source_encodings = tokenizer(item['source'], max_length=64, truncation=True, padding="max_length", return_tensors="pt")
with tokenizer.as_target_tokenizer():
target_encodings = tokenizer(item['target'], max_length=64, truncation=True, padding="max_length", return_tensors="pt")
tokenized_data.append({
"input_ids": source_encodings["input_ids"],
"attention_mask": source_encodings["attention_mask"],
"labels": target_encodings["input_ids"]
})
## 변환된 데이터를 DataFrame으로 변환
formatted_data_df = pd.DataFrame([{
"input_ids": fd["input_ids"].numpy().tolist()[0], ## Tensor를 리스트로 변환
"attention_mask": fd["attention_mask"].numpy().tolist()[0], ## Tensor를 리스트로 변환
"labels": fd["labels"].numpy().tolist()[0] ## Tensor를 리스트로 변환
} for fd in tokenized_data])
## 데이터를 Dataset 형식으로 변환
train_dataset = Dataset.from_pandas(formatted_data_df)
train_test_split = train_dataset.train_test_split(test_size=0.1)
dataset_dict = DatasetDict({
'train': train_test_split['train'],
'test': train_test_split['test']
})
## 학습 매개변수 설정
training_args = Seq2SeqTrainingArguments(
output_dir="", ## 결과물을 저장할 디렉토리
evaluation_strategy="epoch", ## 평가 전략
learning_rate=2e-5, ## 학습률
per_device_train_batch_size=16, ## 디바이스 당 배치 크기
weight_decay=0.01, ## 가중치 감소
save_total_limit=3, ## 저장할 최대 체크포인트 수
num_train_epochs=3, ## 학습 에폭 수
predict_with_generate=True, ## 생성을 사용한 예측 활성화
)
## 학습 준비
trainer = Seq2SeqTrainer(
model=model, ## 학습할 모델
args=training_args, ## 학습 설정
train_dataset=dataset_dict['train'], ## 학습 데이터셋
eval_dataset=dataset_dict['test'], ## 평가 데이터셋
tokenizer=tokenizer
)
## 학습 시작
trainer.train()
다음 포스팅에서는 해당 코드에서 더 발전된 형태의 데이터셋, 아이디어, 파인튜닝 코드를 가져오겠습니다.
몇 번의 변천사를 거쳐서 발전된 느낌이거덩요.
[프로젝트] 제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 리뷰 (2)
안녕하세요. 이번 포스팅에서는 지난 포스팅에 이어 올해 1학기에 진행했던 프로젝트에 대해서 얘기해보려고 합니다. [프로젝트] 제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 리뷰
dangingsu.tistory.com
'프로젝트' 카테고리의 다른 글
| [프로젝트] 제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 리뷰 (3) (2) | 2024.12.09 |
|---|---|
| [프로젝트] 제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 리뷰 (2) (8) | 2024.12.06 |
| [프로젝트] HR_면접자 정보 맞추기 프로젝트 (3) (2) | 2024.10.12 |
| [프로젝트] HR_면접자 정보 맞추기 프로젝트 (2) (1) | 2024.10.04 |
| [프로젝트] HR_면접자 정보 맞추기 프로젝트 (1) (4) | 2024.10.01 |
| [프로젝트] Whisper 파인튜닝 (3) | 2024.09.21 |
| [프로젝트] 티스토리 블로그 Web Crawling (11) | 2024.09.14 |
| [프로젝트] 2024 하반기 ICT 학점연계 프로젝트 인턴십 합격 후기 (0) | 2024.08.14 |



