자, 오늘은 OpenAI의 Whisper 모델 설명을 마치고 공부한 다음 프로젝트 준비 겸 파인튜닝을 가볍게 시도해보려고 합니다.
Whisper 논문리뷰나 모델 설명이 궁금하신 분은 아래 링크 들어가셔서 참고해주시면 좋을 것 같습니다 ~ !
[논문리뷰] Whisper 논문 리뷰
오늘은 Whisper 논문 리뷰를 가져왔습니다.Robust Speech Recognition via Large-Scale Weak Supervision저자 : Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever[1] Introduction1) 기술적 배경 음성 인식
dangingsu.tistory.com
1. 환경 설정
오늘 파인튜닝 프로세스는 대체로 허깅페이스에서 모델과 데이터셋을 받아서 학습시키는 방식으로 진행하도록 하겠습니다.
허깅페이스를 쓰는 이유는 .. 뭐 그냥 별다른 이유는 없고 원래 이렇게 많이 해왔고 이 방법이 가장 간편한 것 같아서요 .. ㅎㅎ
아무튼 허깅페이스에서 모델 혹은 데이터셋을 받아오기 위해서는 토큰이 필요합니다.
아래 사진처럼 본인 페이지 > Settings > Access Tokens 에 접근하면 생성할 수 있고 Value 값을 Token으로 사용하면 됩니다.
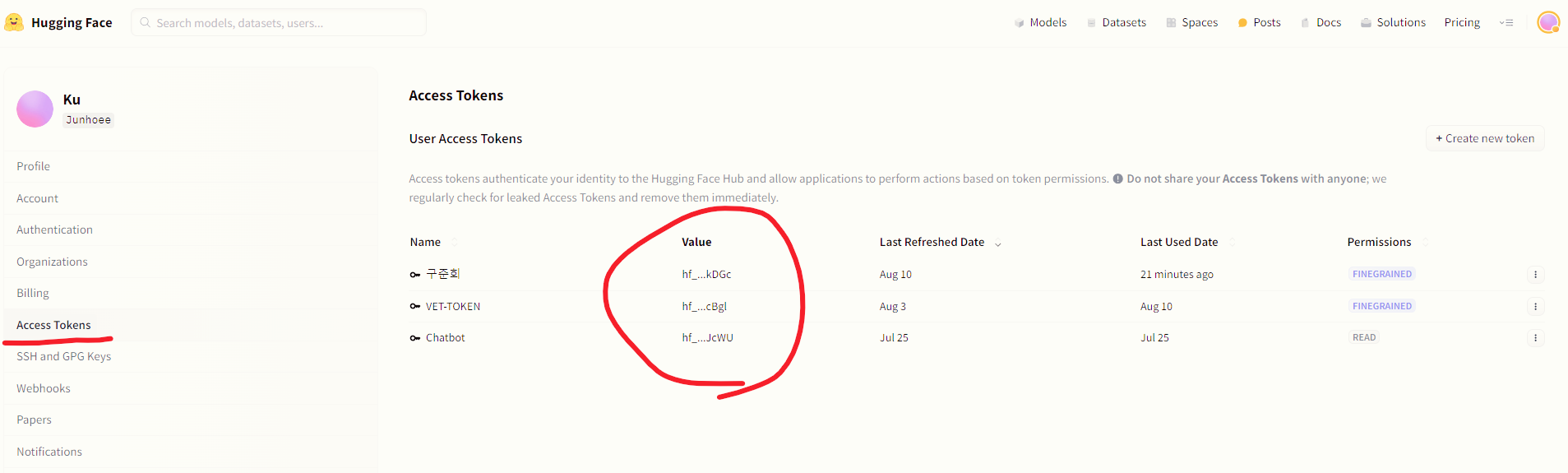
허깅페이스 토큰 발급이 어려우신 분들은 아래 블로그 참고해주시면 감사하겠습니다.
(제 블로그는 아닌데 설명이 잘 되어 있어서 소개드립니다..!)
[Hugging Face API] 허깅페이스 API key 발급 및 여러 모델 사용 예제
🔹 허깅페이스 API Hugging Face는 다양한 NLP 모델과 도구를 개발하고 공유함으로써 개발자들이 쉽게 NLP 기술을 활용할 수 있도록 지원합니다. Hugging Face의 API 서비스를 사용하면 다양한 사전 훈련
sunshower99.tistory.com
Log-In HuggingFace
파이썬 환경에서 허깅페이스에 로그인하는 방법은 크게 두 가지입니다.
1. os에 접근해서 토큰을 입력하는 방법
2. 허깅페이스 로그인 패키지를 활용하는 방법
뭐 사실 두 방법 모두 결과는 같으니 선호하시는 방법 자유롭게 쓰셔도 무방합니다.
import os
os.environ["HF_TOKEN"] = "토큰입력"from huggingface_hub import notebook_login
notebook_login('토큰입력')2. 모델 및 데이터셋 불러오기
환경 설정을 마쳤다면 이제 본격적으로 모델과 데이터셋을 불러올 차례입니다.
어쩌다보니 허깅페이스 강의처럼 되어가고 있는 느낌인데..ㅋㅋ 기분탓입니다.
아무튼 아래처럼 허깅페이스 > Models > Whisper 검색 을 통해 원하는 모델을 탐색할 수 있습니다.
데이터셋도 허깅페이스 > Datasets > 검색 을 통해 원하는 데이터셋을 찾을 수 있는데
추가로 사진에는 나와있지 않지만 Language 설정에서 Korean을 선택하면 한국어 모델, 데이터셋만 찾아볼 수도 있습니다.

Whisper 모델을 좀 찾아보니까 이렇게 많은 버전이 있더라구요.
이 중에 저는 제 GPU, Disk 환경에서 작동되는 가장 큰 버전인 Medium 버전을 선택해서 학습시켜보도록 하겠습니다.

아마 허깅페이스의 각 모델 설명에도 나와있겠지만 아래와 같이 모델 학습을 준비해주시면 되겠습니다.
from transformers import WhisperForConditionalGeneration
from transformers import WhisperFeatureExtractor
from transformers import WhisperTokenizer
from transformers import WhisperProcessor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-medium")
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-medium", language="Korean", task="transcribe")
processor = WhisperProcessor.from_pretrained("openai/whisper-medium", language="Korean", task="transcribe")
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-medium")
model.config.forced_decoder_ids = None
model.config.suppress_tokens = []
다음은 데이터셋인데.. 제 음성 <-> 텍스트 데이터셋을 활용하도록 하겠습니다.
절대 홍보 아니고 (홍보해봤자 얼마나 쓰겠어요..)
기존 데이터셋들을 합치고 전처리해서 제가 각색한 내용 추가해서 정성스럽게 만든 데이터셋입니다 ^^
약 80,000개의 행으로 구성되어 있어요.
Junhoee/STT_Korean_Dataset_80000 · Datasets at Hugging Face
아 교재 반품하신다고요? 회원님 저희가 자세한 안내를 위해서는 회원님 정보 확인이 필요해요. 실례지만 회원님 아이디랑 성함이 아이디랑 연락처는 어떻게 아 네, 네, 소중한 정보 확인 감사
huggingface.co
데이터셋은 허깅페이스의 datasets 패키지, load_dataset을 활용해서 받아올 수 있습니다.
from datasets import load_dataset
from datasets import Dataset, DatasetDict, concatenate_datasets
ds = load_dataset("Junhoee/STT_Korean_Dataset_80000")
데이터셋 전체를 사용하기보다 평가를 위해 데이터셋을 분할하는 과정을 추가해서 사용하겠습니다.
# 데이터셋을 훈련 데이터와 테스트 데이터, 밸리데이션 데이터로 분할
train_testvalid = ds['train'].train_test_split(test_size=0.2, shuffle = True)
test_valid = train_testvalid["test"].train_test_split(test_size=0.5, shuffle = True)
datasets = DatasetDict({
"train": train_testvalid["train"],
"test": test_valid["test"],
"valid": test_valid["train"]})3. 데이터셋 포맷팅
Whisper 모델 학습을 위해서 오디오 파일을 학습에 용이한 형태로 포맷팅하는 작업이 필요합니다.
아래 코드는 음성 데이터를 처리하기 위해 오디오 파일을 16kHz로 로드한 후 log-Mel spectrogram으로 변환하고, 텍스트 트랜스크립트를 토크나이저로 처리하여 모델 학습에 필요한 형식으로 배치 내 데이터를 준비합니다.
이렇게 하는 이유는 오디오와 텍스트 데이터를 모델이 학습할 수 있는 입력(features)과 레이블(labels)로 변환하기 위해서입니다.
마지막으로, 데이터셋에 함수를 적용해 대량의 데이터 배치를 효율적으로 처리할 수 있도록 설정합니다.
def prepare_dataset(batch):
# 오디오 파일을 16kHz로 로드 및 처리
input_features = []
labels = []
# 배치 내의 모든 오디오 샘플과 트랜스크립트를 처리
for audio, transcript in zip(batch["audio"], batch["transcripts"]):
# input audio array로부터 log-Mel spectrogram 변환
feature = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
input_features.append(feature)
# target text를 label ids로 변환
label = tokenizer(transcript).input_ids
labels.append(label)
# 변환된 데이터를 배치에 추가
batch["input_features"] = input_features
batch["labels"] = labels
return batch
# 데이터셋에 함수 적용, 배치 처리 활성화
low_call_voices = datasets.map(prepare_dataset, batched = True, remove_columns=datasets.column_names["train"], num_proc=1, load_from_cache_file=False, keep_in_memory=False)
아래 코드는 음성 시퀀스 데이터를 모델에 입력할 수 있도록 적절히 패딩하고 정리하는 데이터 콜레이터를 구현합니다. 오디오 인풋 데이터와 레이블(토큰화된 텍스트 데이터)은 길이가 다르기 때문에 서로 다른 방식으로 패딩이 적용되며, 오디오 데이터는 간단히 텐서로 변환하고, 텍스트 데이터는 최대 길이로 패딩합니다. 레이블에서 패딩 토큰을 -100으로 치환하여 손실(loss) 계산 시 무시되도록 하며, 필요 시 처음의 bos 토큰을 제거합니다.
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# 인풋 데이터와 라벨 데이터의 길이가 다르며, 따라서 서로 다른 패딩 방법이 적용되어야 한다. 그러므로 두 데이터를 분리해야 한다.
# 먼저 오디오 인풋 데이터를 간단히 토치 텐서로 반환하는 작업을 수행한다.
input_features = [{"input_features": feature["input_features"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# Tokenize된 레이블 시퀀스를 가져온다.
label_features = [{"input_ids": feature["labels"]} for feature in features]
# 레이블 시퀀스에 대해 최대 길이만큼 패딩 작업을 실시한다.
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# 패딩 토큰을 -100으로 치환하여 loss 계산 과정에서 무시되도록 한다.
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# 이전 토크나이즈 과정에서 bos 토큰이 추가되었다면 bos 토큰을 잘라낸다.
# 해당 토큰은 이후 언제든 추가할 수 있다.
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)4. 평가지표 설정
다음은 평가지표 설정 부분입니다.
STT 모델의 평가지표도 다른 Task와 마찬가지로 여러 개 존재합니다. 그 중 대표적으로 WER, CER이 있는데요.
- WER (Word-Error-Rate) : '단어' 기준으로 오류율 판단
- CER (Character-Error-Rate) : '음절' 기준으로 오류율 판단
이 중에서 CER을 쓸 계획입니다.
왜냐하면 한국어는 형태소로도 분리되고 음절에 따라 맞고 틀리는 경우가 종종 있기 때문이죠.
이를 코드로 구현하자면 아래와 같습니다.
compute_metrics 함수는 모델의 예측 값(predictions)과 실제 라벨(label_ids)을 비교하여 문자 오류율을 계산합니다. 먼저, 패딩된 라벨에서 -100 값을 패딩 토큰 ID로 치환하고, 예측과 라벨 시퀀스를 special token을 제외한 텍스트로 디코딩한 후, CER 지표를 계산합니다.
최종적으로, CER 값을 백분율로 반환하여 모델의 성능을 평가합니다.
!pip install evaluate
!pip install jiwer
import evaluate
metric = evaluate.load('cer')
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# pad_token을 -100으로 치환
label_ids[label_ids == -100] = tokenizer.pad_token_id
# metrics 계산 시 special token들을 빼고 계산하도록 설정
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
label_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)
cer = 100 * metric.compute(predictions=pred_str, references=label_str)
return {"cer": cer}5. 실제 학습
이제 실제로 학습을 시켜볼 단계입니다.
학습도 허깅페이스에서 제공하는 Trainer 패키지를 활용할 예정입니다.
아래와 같이 학습에서 설정할 수 있는 인자들 설정해주고
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="whisper-medium-korean-finetuning", # 훈련된 모델이 저장될 디렉토리 경로
per_device_train_batch_size=1, # 훈련 시 디바이스별 배치 크기
gradient_accumulation_steps=16, # 배치 크기를 축소하여 메모리를 절약하고 업데이트 빈도를 조정
learning_rate=2e-5, # 학습률 설정
warmup_steps=500, # 학습 초기 단계에서 학습률을 점진적으로 증가시키기 위한 워밍업 단계
max_steps=3000, # 학습할 최대 스텝 수, epoch 대신 사용
gradient_checkpointing=True, # 메모리를 절약하기 위해 중간 단계에서 그래디언트를 저장
fp16=True, # 훈련 속도와 메모리 효율성을 위해 16비트 부동 소수점 사용
evaluation_strategy="steps", # 지정한 스텝마다 모델 평가
per_device_eval_batch_size=1, # 평가 시 디바이스별 배치 크기
predict_with_generate=True, # 평가 중 텍스트 생성 활성화
generation_max_length=256, # 생성 시퀀스의 최대 길이
save_steps=500, # 지정한 스텝마다 체크포인트 저장
eval_steps=500, # 지정한 스텝마다 평가 수행
logging_steps=25, # 지정한 스텝마다 로그 작성
report_to=["tensorboard"], # 텐서보드에 로그 전송
load_best_model_at_end=True, # 훈련이 끝날 때 가장 좋은 성능의 모델을 로드
metric_for_best_model="cer", # 'cer' 지표를 기준으로 최고의 모델 선정
greater_is_better=False, # 'cer'은 값이 낮을수록 성능이 좋음
push_to_hub=True, # 모델을 Hugging Face Hub에 푸시
)
허깅페이스의 S2STrainer 패키지를 활용해서 학습을 시켜줍니다.
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=low_call_voices["train"],
eval_dataset=low_call_voices["test"], # or "test"
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=processor.feature_extractor,
)
trainer.train()6. 모델 저장
학습시킨 모델을 나중에 사용해보거나 할 때 저장은 필수죠.
모델 저장하는 부분까지 작성하고 이번 포스팅을 마무리하겠습니다.
저장을 원하는 레포지토리 이름을 설정하고 task, tags 등 추가적으로 설정해줍니다.
꼭 이렇게 하실 필요는 없고 간단하게 push_to_hub(모델명)만 해도 잘 올라갑니다.
kwargs = {
"dataset_tags": "사용한 데이터셋 이름",
"dataset": "설정해주고 싶은 데이터셋 이름",
"dataset_args": "config: ko, split: valid",
"language": "ko",
"model_name": "설정해주고 싶은 모델 이름",
"finetuned_from": "openai/whisper-medium",
"tasks": "automatic-speech-recognition",
"tags": "hf-asr-leaderboard",
}
trainer.push_to_hub(**kwargs)
processor.push_to_hub("레포지토리 이름")
tokenizer.push_to_hub("레포지토리 이름")
이렇게 오늘은 OpenAI의 Whisper 모델을 파인튜닝해보는 시간을 가져보았습니다.
많은 분들이 AI를 활발히 연구해서 편리한 AI 모델이 많아졌으면 좋겠네요.
[프로젝트] 자전거 교통사고 원인 분석 프로젝트 리뷰
2023년 2학기 다변량 통계 분석 과목을 수강하면서 진행했던 프로젝트에 대해 리뷰해보려고 한다.해당 프로젝트는 데이터 분석 프로젝트이고 분야는 데이터 분석, 시계열이 되겠다. 주제 선정
dangingsu.tistory.com
'프로젝트' 카테고리의 다른 글
| [프로젝트] 제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 리뷰 (1) (6) | 2024.12.03 |
|---|---|
| [프로젝트] HR_면접자 정보 맞추기 프로젝트 (3) (2) | 2024.10.12 |
| [프로젝트] HR_면접자 정보 맞추기 프로젝트 (2) (1) | 2024.10.04 |
| [프로젝트] HR_면접자 정보 맞추기 프로젝트 (1) (4) | 2024.10.01 |
| [프로젝트] 티스토리 블로그 Web Crawling (11) | 2024.09.14 |
| [프로젝트] 2024 하반기 ICT 학점연계 프로젝트 인턴십 합격 후기 (0) | 2024.08.14 |
| [프로젝트] 국내 주요 게임사 텍스트 데이터 분석 프로젝트 리뷰 (2) (4) | 2024.07.12 |
| [프로젝트] 자전거 교통사고 원인 분석 프로젝트 리뷰 (0) | 2024.07.09 |



