[프로젝트] HR_면접자 정보 맞추기 프로젝트 (1)
논문 읽는 학회에 멤버로 참여해 매주 논문을 하나씩 읽어보면서 공부했던 시절에는 매주 블로그 소재가 하나씩 생겼는데 이 활동이 끝나니까 블로그 소재가 뚝 떨어졌네요.. ㅠㅠ 그래서 새로
dangingsu.tistory.com
지난 1편에 이어서 진행되겠습니다!
1편에서는 전처리, EDA 등 주로 데이터에 대해 알아보았습니다.
2편에서는 본격적으로 모델 파인튜닝 및 평가를 해보려고 합니다!
1. Task 확인

모델 파인튜닝을 위해서는 먼저 우리가 할 Task, 즉 궁극적인 목표가 무엇인지 설정하는 것이 중요합니다. 하나의 소재라도 다양한 Task를 진행할 수 있기 때문이죠. 예를 들면 아래와 같습니다.
- 면접자 성별을 맞추는 이진분류 Task
- 면접자 성별, 연령대, 경력 등 정보를 결합한 후 다중분류 Task
- 면접자의 정보를 텍스트로 생성하는 Text Generation Task
등등 다양한 Task가 있을 수 있는데 이번에는 2번째 항목인 "성별, 연령대, 경력 정보를 결합한 후 다중분류 Task"로 풀어볼 예정입니다!
2. 모델 탐색
데이터도 찾았고 Task도 설정 완료했다면 이제 모델을 찾을 차례입니다.모델은 Github, HuggingFace 등 다양한 출처에서 찾을 수 있지만 저는 간편성을 위해 허깅페이스를 이용하겠습니다.
Hugging Face – The AI community building the future.
The Home of Machine Learning Create, discover and collaborate on ML better. We provide paid Compute and Enterprise solutions. We are building the foundation of ML tooling with the community.
huggingface.co
허깅페이스 > Models 에 들어왔다면 위와 같은 페이지가 보일 겁니다. 저희는 NLP Task를 진행할 거라 왼쪽 항목 중에 NLP 항목들을 보면 되는데요. NLP 항목에도 Text Classification, Token Classification, Full Mask 등 다양한 분류 태스크가 존재합니다. 사실 아직까지도 잘 모르긴 하지만 앞의 두 분류 Task는 감정분석이나 점수를 매기는 등의 적은 클래스의 분류 문제를 해결하는데 적합한 것 같고 저는 Full Mask 항목에서 모델을 찾아서 사용했습니다.
그리고 언어 설정도 할 수 있는데요. Language > Korean 으로 설정하면 한국어 모델을 찾을 수 있습니다. 위에서부터 보통 가장 Trending 모델이 뜨는데 Facebook이나 Google에서 Opensource로 배포하는 모델을 바로 쓰기보다 대규모의 한국어 데이터로 파인튜닝한 후 사용하는게 더 낫다고 생각해서 위 모델들은 사용하지 않았구요.(지극히 개인적인 생각입니다!) 언어 모델계에서 유명하신 "beomi" 님의 kcbert-base 모델을 써볼까도 했었는데 저 모델은 max_length가 300이더라구요.. 그래서 사용하지 않았습니다. 결국 사용한 모델은 kobigbird 라는 모델인데, 이름이 뭔가 귀엽지 않나요? ㅋㅋ 아무튼 이름도 귀엽고 꽤 상위에 있기도 하고 max_length도 길고 한국어 파인튜닝도 되어 있었으며 모델 학습 시키기에 메모리도 적당해서 이 모델을 사용하기로 했습니다.
3. 파인튜닝
이제 데이터, 모델, Task 설정까지 모두 마쳤으니 본격적으로 파인튜닝할 시간입니다.
일단 저도 GPU가 없어서 캐글 Notebook에서 무료로 제공하는 P100 GPU를 활용하였습니다.
1) Package Import
## 필요한 패키지 임포트
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
import pandas as pd
import torch
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
pd.set_option('display.max_colwidth', 1000)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)- Dataset : 허깅페이스에서 제공하는 pandas dataset 활용 패키지
- AutoTokenizer : 허깅페이스에서 제공하는 Tokenizer 패키지
- AutoModelForSequenceClassification : 허깅페이스에서 제공하는 다중분류 Task Model 패키지
- Trainer : 허깅페이스에서 제공하는 자동으로 편리하게 학습시킬 수 있게 해주는 패키지
- TrainingArguments : Trainer 패키지에 인자 설정해줄 수 있는 패키지
2) Dataset Load & Formatting
## dataset load
df = pd.read_csv('/kaggle/input/1003-dataset/Interview.csv')
## tokenizer max length에 맞게 데이터 정제
df.answer_length = df.answer_text.apply(lambda x : len(x))
df = df.loc[df.answer_length < 512].reset_index(drop = True)
## 성별, 연령대, 경력 정보를 결합한 새로운 레이블 생성 및 인코딩
df['combined_label'] = df[['gender', 'ageRange', 'experience']].apply('_'.join, axis=1)
df['combined_label_encoded'] = LabelEncoder().fit_transform(df['combined_label'])
## 데이터를 학습 및 평가 세트로 분할
train_df, test_df = train_test_split(df, test_size=0.1)
## Hugging Face Dataset으로 변환 및 열 이름 변경
train_dataset = Dataset.from_pandas(train_df).rename_column("combined_label_encoded", "labels")
test_dataset = Dataset.from_pandas(test_df).rename_column("combined_label_encoded", "labels")- 추가 설명을 하자면 원래 gender, ageRange, experience로 나뉘어져 있던 지원자 정보를 결합한 후 라벨 인코딩으로 이를 수치화하고 이 label을 맞추는 다중분류 Task로 구현하였습니다.
3) Tokenizer & Model
## 모델 및 토크나이저 로드
num_labels = len(df['combined_label_encoded'].unique()) ## 클래스 수 계산
model = AutoModelForSequenceClassification.from_pretrained('monologg/kobigbird-bert-base', num_labels=num_labels).to(device)
tokenizer = AutoTokenizer.from_pretrained('monologg/kobigbird-bert-base')
## 토크나이저 함수를 정의
def tokenize_function(dataset):
return tokenizer(dataset['answer_text'], padding='max_length', truncation=True, max_length = 512)
## 토크나이징 적용
train_dataset = train_dataset.map(tokenize_function, batched=True)
test_dataset = test_dataset.map(tokenize_function, batched=True)
## 불필요한 텍스트 필드 제거
train_dataset = train_dataset.remove_columns(["answer_text"])
test_dataset = test_dataset.remove_columns(["answer_text"])- 다중분류 Task에 맞게 클래스 수를 계산해서 num_labels로 설정해주었습니다
- 그리고 dataset에 tokenize 함수를 적용했는데 input_ids, labels를 직관적으로 model에 넘겨주기 위해서 answer_text를 지우긴 했습니다
4) Training
## 학습 설정
training_args = TrainingArguments(
output_dir='./results', ## 결과 저장 경로
evaluation_strategy='steps', ## 평가 전략 (스텝마다 평가)
eval_steps=500, ## 500 스텝마다 평가
per_device_train_batch_size=16, ## 배치 크기
per_device_eval_batch_size=16, ## 평가 배치 크기
num_train_epochs=3, ## 에포크 수
weight_decay=0.01, ## 가중치 감쇠
logging_dir='./logs', ## 로그 경로
logging_steps=500, ## 로그 기록 빈도
)
## Trainer 객체 생성
trainer = Trainer(
model=model, ## 학습할 모델
args=training_args, ## 학습 설정
train_dataset=train_dataset, ## 학습 데이터셋
eval_dataset=test_dataset, ## 평가 데이터셋
)
import wandb
## 환경 변수에서 토큰을 가져와 자동으로 로그인
wandb.login(key = '여기에 wandb키를 입력하면 바로 로그인됩니다.')
## 모델 학습
trainer.train()
## 학습 후 모델을 Hugging Face에 업로드
auth_token = your_token
trainer.push_to_hub("여기에 레포짓 이름 입력하시면 됩니다.", use_auth_token=auth_token)
tokenizer.push_to_hub("여기에 레포짓 이름 입력하시면 됩니다.", use_auth_token=auth_token)
## wandb 끝
wandb.finish()- 데이터셋 끝까지 고루 학습하라고 epoch로 설정해주었습니다
- loss 확인은 좀 더 상세하게 하기 위해 500 step으로 해주었습니다
- batch size는 16으로 하긴 했는데, 크게 하면 데이터셋을 더 잘 반영하지만 메모리가 크게 들고 작게 하면 덜 반영하지만 메모리를 아낄 수 있습니다. 각각의 장단점이 있는거죠
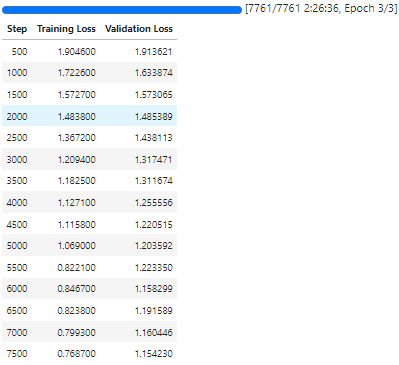
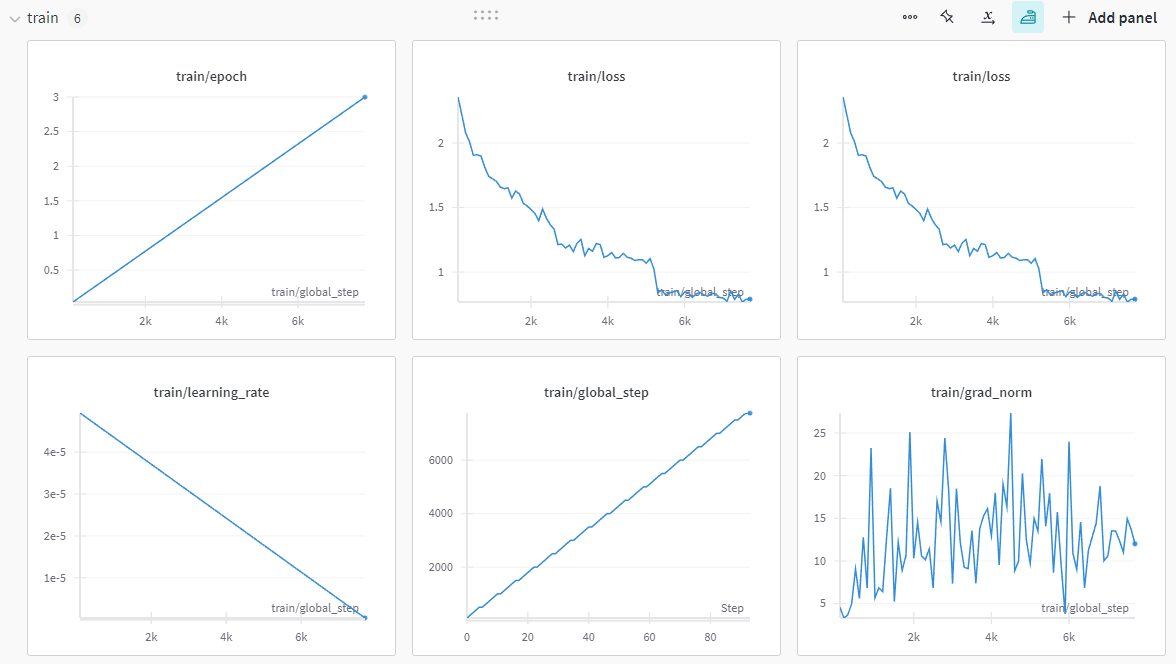
전체적으로 우하향하는 loss 그래프를 그리고 있고 validation loss와 그렇게 큰 차이도 나지 않아서 학습이 잘 되었다고 볼 수가 있겠습니다.
이번 포스팅은 여기서 마무리하도록 하겠습니다.
다음 포스팅에서는 Inference 결과를 보면서 모델이나 데이터를 어떻게 후처리할지 고민하는 시간을 가져보면 좋을 것 같습니다.
[프로젝트] HR_면접자 정보 맞추기 프로젝트 (3)
https://dangingsu.tistory.com/47 [프로젝트] HR_면접자 정보 맞추기 프로젝트 (2)https://dangingsu.tistory.com/46 [프로젝트] HR_면접자 정보 맞추기 프로젝트 (1)논문 읽는 학회에 멤버로 참여해 매주 논문을 하
dangingsu.tistory.com
'프로젝트' 카테고리의 다른 글
| [프로젝트] 제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 리뷰 (3) (2) | 2024.12.09 |
|---|---|
| [프로젝트] 제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 리뷰 (2) (9) | 2024.12.06 |
| [프로젝트] 제주어, 표준어 양방향 음성 번역 모델 생성 프로젝트 리뷰 (1) (6) | 2024.12.03 |
| [프로젝트] HR_면접자 정보 맞추기 프로젝트 (3) (2) | 2024.10.12 |
| [프로젝트] HR_면접자 정보 맞추기 프로젝트 (1) (4) | 2024.10.01 |
| [프로젝트] Whisper 파인튜닝 (3) | 2024.09.21 |
| [프로젝트] 티스토리 블로그 Web Crawling (11) | 2024.09.14 |
| [프로젝트] 2024 하반기 ICT 학점연계 프로젝트 인턴십 합격 후기 (1) | 2024.08.14 |



