오늘은 mPLUG 논문 리뷰를 가져왔습니다.

해당 논문은 2022년에 EMNLP에서 발표된 논문입니다.
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
저자 : Chenliang Li, Haiyang Xu, Junfeng Tian, Wei Wang, Ming Yan, Bin Bi, Jiabo Ye, Hehong Chen, Guohai Xu, Zheng Cao, Ji Zhang, Songfang Huang, Fei Huang, Jingren Zhou, Luo Si
[1] Introduction

mPLUG는 위 5가지 Vision Language Task에 좋은 성능을 내는 것이 목표입니다. 각 Task가 어떤 Task인지 짧게씩만 좀 짚고 넘어가겠습니다.
- Image Captioning : 이미지 input이 주어지면 해당 이미지가 어떤 이미지인지 답을 내는 Task
- VQA ( Vision Question Answering ) : 이미지와 텍스트 질문이 주어졌을 때 답을 내는 Task
- Image Text Retrieval : 이미지나 텍스트가 주어졌을 때 반대편의 결과물을 탐색하는 Task
- Visual Grounding : 텍스트 프롬프트에 맞는 Image의 일부분만 잘라내는 Task
- Visual Reasoning : 이미지가 주어져 있고 Text 프롬프트가 추가로 주어질 때 답을 추론해내는 Task
그리고 기존의 VLP 모델을 두 가지 형태로 나누고 각각의 문제점을 짚었습니다. 이미지와 텍스트 각각의 Encoder를 사용하고 Self Attention과 Feed Forward Network를 거치는 Dual Encoder 모델 ( CLIP, ALIGN 등 ), 그리고 각각의 Encoder가 있고 Cross Attention을 통해 더 세부적인 사항까지 고려할 수 있도록 만든 Fusion Encoder 모델 ( ALBEF, UNITER, LXMERT 등 ) 으로 나눴습니다. 그래서 각 방식의 문제점을 짚고 이점만 가져와 새로운 Cross Modal Fusion Machanism을 개발하였습니다.
[2] Related Work
1) Dual Encoder

Introduction에서 언급했듯이 본 논문에서는 Dual Encoder 모델과 Fusion Encoder 모델에 대해 언급하고 있고 먼저, Dual Encoder 모델이 뭔지 특징과 장단점을 살펴보겠습니다. Dual Encoder 모델은 이미지와 텍스트, 별도의 인코더를 사용하고 두 인코더에서 각 모달리티의 특징을 추출하며 이후 두 모달의 특징으로 이미지와 텍스트가 얼마나 매칭되는지 계산하는 식으로 학습합니다. 이러한 모델의 장점으로는 각 모달리티 즉, 텍스트나 이미지의 특징을 미리 계산하고 저장하기 때문에 검색, 비교 작업을 빠르게 수행할 수 있는 반면 각 모달리티가 독립적으로 처리되어 더 세부적인, 깊이 있는 정보까지는 캐치하지 못하고 두 모달리티의 정보량 차이 때문에 성능이 저하되는 경우가 있습니다. 위 그림처럼 Visual Encoder에서는 이미지를 Patch 단위로 막 잘랐는데 텍스트는 단 4개의 토큰이 존재할 때 이러한 경우에 두 모달리티의 정보량 차이가 나고 성능이 저하된다고 얘기를 하고 있습니다.
2) Fusion Encoder

다음은 Fusion Encoder도 좀 보겠습니다. Fusion Encoder 모델도 마찬가지로 이미지와 텍스트, 별도의 인코더를 사용하고 Self Attention, Cross Attention 등으로 이미지와 텍스트, 두 모달리티 간 세부적인 상호작용을 학습할 수 있다는 특징이 있습니다. 아무래도 Cross Attention을 서로 수행하기 때문에 정보의 불균형 문제를 해소할 수 있었고 이미지와 텍스트 간 세부적인 요소도 추론할 수 있다는 점이 장점이 되겠고, 그런 반면 연산량이 많아지기 때문에 시간과 비용이 증가한다는 단점이 존재합니다.
3) Skip Connection

그래서 본 논문에서는 앞서 본 두 Model의 단점을 보완한 형태의 이러한 아키텍쳐를 제안합니다. 특히 Skip Connection을 사용했다는 점이 특징적인데요. mPLUG는 이미지와 텍스트를 처리하는 두 개의 단일 인코더로 구성했고 이미지는 이미 Encoder에서부터 충분한 정보가 들어있다고 판단해 텍스트만 Selft Attention 연산 후 위의 Connected Attention Layer로 전달이 됩니다. 그래서 이렇게 모델을 구성했을 때 정보량 차이도 완화하면서 연산량을 줄일 수 있었다고 얘기하고 있고요. 오른쪽 그래프는 모델 아키텍쳐를 3가지 경우로 나눠서 러닝 타임을 분석한 그래프입니다. Feed Forward Network를 여러 번 쓰는 경우, Transformer 모델을 2개 즉 Skip Connection이 없는 모델의 경우, 왼쪽과 같은 모델 구조로 Skip Connection을 사용한 경우로 나눠서 분석을 하였고 Skip Connection을 사용한 경우가 연산 속도도 가장 빠르고, 성능도 가장 좋아서 이러한 형태의 모델을 사용했다는 얘기를 하고 있습니다.
[3] Model Architecture

모델 아키텍쳐는 이미지와 텍스트 각각의 인코더가 존재하고 있고 각각은 ViT Encoder, BERT Encoder를 사용하였다고 합니다. 그리고 중간에 Skip Connection Fusion Block를 여러 번 거쳐 Decoder로 전달되는 이러한 모델 구조를 가지고 있습니다. 이 중에서 Skip Connection Fusion Block에서 어떻게 계산이 되는지 좀 더 자세히 살펴보도록 하겠습니다.
Skip Connection Fusion Block은 위 사진과 같은 형태를 가지고 있고, 이러한 블록이 총 N번 쌓여진 형태를 띄고 있습니다. 그리고 초록색 네모 박스로 표현된 4가지 Loss Function을 가지고 학습을 시키는 것이 또 특징입니다. 전체적으로 딱 봤을 때 이미지와 텍스트가 각각의 인코더에 들어가서 서로 Image Text Contrastive Learning, ITC 학습이 진행됩니다. 그리고 Skip Connected Fusion Block을 거쳐 나온 임베딩 벡터는 Image Text Matching인 ITM, Masked Language Model인 MLM Loss Function으로 계산되고 디코더로 넘어가 마지막에 생성한 문장에 대해 PrefixLM 방법론으로 계산됩니다. 그래서 총 Loss Function은 각 Loss들을 합하여 계산하구요. 각각의 Loss Function에서 구체적으로 어떻게 연산되는지 더 보겠습니다.
1) Image Text Contrastive Learning

첫 번째로 ITC ( Image Text Contrastive Learning )입니다. ITC란 이미지와 텍스트쌍이 관련 있는 것끼리 가깝게 만들고 관련 없는 것끼리 멀게 만들면서 최적화시키는 방식을 의미합니다. 예시처럼 빠삐용 강아지 사진이 있으면 Positive Pair를 가깝게 Negative Pair를 멀게 만드는 거죠. 그러면 이미지와 텍스트 각각을 기준으로 삼아 가장 관련 깊은 Pair를 계산할 수 있고 mPLUG에서는 Image Loss, Text Loss를 더해 ITC Loss를 구성했으며 이를 통해 이미지와 텍스트 간 세부적인 상호작용에 대해 학습할 수 있었다고 합니다.
2) Image Text Matching


두 번째로는 ITM, Image Text Matching입니다. ITM은 이미지와 텍스트 각 요소별로 코사인 유사도를 왼쪽 예시와 같이 계산합니다. 그리고 각 요소별 가장 유사도가 높은 Positive Sample과 그 다음으로 유사도가 높은 Hard Negative Sample을 학습에 사용했다고 합니다. 무슨 얘기냐면 첫 번째 표에서 이미지 기준으로 봤을 때 이미지1에 대한 Positive Sample은 텍스트1입니다. 가려져있지만. 그런데 그 다음으로 텍스트2가 0.25로 유사도가 높고 이러한 경우에 텍스트2도 함께 학습에 사용했다는 얘기입니다. 두 번째 표도 보면 텍스트 기준으로 봤을 때 텍스트1의 Positive Sample은 가려져있지만 이미지1이고 Hard Negative Sample은 두 번째로 수치가 높은 이미지2가 되겠죠. 이러한 방식처럼 Positive Sample과 Hard Negative Sample 모두 학습에 사용했다고 합니다. 그래서 Positive Sample만 써도 학습이 잘 될 것 같은데 왜 Hard Negative Sample도 함께 쓰는지 좀 찾아봤습니다. 먼저 이러한 하드 네거티브 샘플은 이미지와 텍스트 간 미묘한 불일치를 보여 모델이 더 정교하게 학습하는데 도움을 준다고 하고 일반화 성능을 향상시킬 수 있으며 Positive Sample만 가지고 학습할 경우 과적합의 우려가 있다고 해서 Hard Negative Sample도 사용했다고 합니다.
그래서 위의 오른쪽 그림처럼 각각 Positive Sample, Hard Negative Sample이 입력되고 Fusion Block을 거쳐 나온 임베딩을 Concatenate하고 Label과 비교해서 Cross Entropy를 구해 Loss를 계산하는 방식이 ITM 방식입니다.
3) Masked Language Modeling

세 번째로는 MLM입니다. MLM은 BERT에서 주로 쓰였던 마스크 토큰에 들어갈 토큰이 뭔지 맞추면서 학습하는 방법론입니다. mPLUG에서는 Momentum Distillation 모델을 사용해가지고 마스크 토큰과 비슷한 5가지 키워드를 생성합니다. 이 예시에서는 3번 Water가 정답인데 비슷한 단어로 5개를 생성했죠. 그래서 이 토큰들 중 Cross Entropy Loss가 가장 적은 토큰을 선택하는 MLM 방식을 사용했습니다.
4) PrefixLM

네 번째로는 PrefixLM입니다. PrefixLM이란 AutoEncoding 방식과 AutoRegressive 방식을 모두 활용한 언어 모델링 방법론인데 mPLUG에서는 Transformer의 Decoder를 활용해 새롭게 문장을 생성해나가면서 PrefixLM Loss도 활용할 수 있었다고 합니다.
그래서 모델 아키텍쳐 내용이 좀 길었는데 정리를 좀 하자면 첫 번째로 각 인코더를 학습시킬 때 ITC 방법론을 사용합니다. 그래서 텍스트와 이미지의 세부적인 상호작용을 이해할 수 있도록 하고 N개의 Skip Connected Fusion Block을 거칩니다. 거쳐서 나온 피쳐들, 임베딩들의 관계성을 잘 매칭시킬 수 있는지 분류할 수 있는지 ITM 방법론으로 학습하고 텍스트 표현을 더 잘 이해하기 위해서 MLM도 사용을 했습니다. 그리고 나온 Output은 Decoder로 넘어가 문장을 생성하면서 PrefixLM 방법론까지 활용을 한 이러한 아키텍쳐로 mPLUG가 구성되어 있습니다.
[4] Experiments
1) Dataset & Setup

다음은 실험 부분입니다. 처음으로 데이터셋 구성과 셋업 부분인데, In-domain 데이터셋으로는 MS COCO와 Visual Genome을 활용하였고 out-domain 데이터셋으로는 이러한 데이터들을 사용했다고 합니다. 그리고 셋업은 GPU는 A100 GPU, Optimizer는 아담, Learning Rate는 인코더마다 다르게 이렇게 설정해주었구요. 등등 사진에 나와있는 저러한 모델 셋업을 가지고 있습니다.

mPLUG는 이미지와 텍스트 모두를 다루는 대규모 모델이다보니 학습시킬 때 많은 문제들에 직면했다고 합니다. 그래서 메모리 사용량과 학습 시간을 단축시키려는 여러 전략을 사용했습니다. 그 중 Zero 기술은 모델 파라미터, 가중치, 옵티마이저 등을 여러 GPU에 나누어 저장해 메모리를 아끼는 방식이고 가중치 체크포인트 방식도 사용해 메모리 사용량을 감소시켰다고 합니다. 그리고 계산 시간 감소를 위해 fp32보다 bf16을 사용해가지고 성능은 조금 낮아질 수 있지만 그래도 계산 속도의 효율성을 위해서 사용했습니다.
2) 5가지 Task에 대한 성능 향상

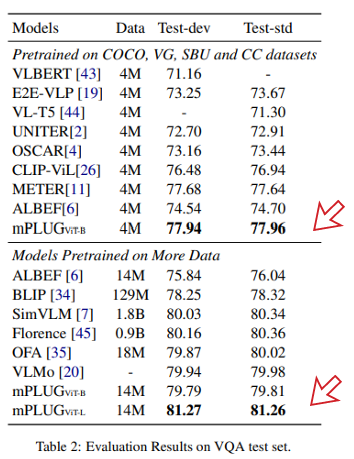
5가지 Task에 대한 구체적인 성능 지표는 논문 딴에서 확인해주시면 감사하겠습니다.
절대 귀찮아서 두 지표만 올린 거 아닙니다 ㅎㅎ
- Image Captioning
- COCO Caption Dataset, CIDEr 평가에서 SOTA 성능을 달성
- NoCaps 검증 데이터셋에서도 매우 적은 데이터만으로 최고 성능에 근접하거나 능가하는 모습을 보여줌
- VQA
- 전체적으로 기존 모델들에 비해 높은 성능 기록
- Test - Standard Deviation 분할 측면에서는 점수 81.27로 약 100배, 60배 많은 데이터를 학습한 SimVLM, Florence 보다 높은 성능을 기록
- Dual Encoder 모델인 CLIP 기반 모델보다 높은 성능 기록
- Image Text Retrieval
- 이미지와 텍스트 유사도를 계산해 등장가능한 K개의 후보를 선정, 선정한 K개의 후보를 다시 순위를 매겨 평가
- 모든 부분에서 SOTA 달성
- 특히 BLIP, Florence 등 당시 핫했던, 학습 데이터를 많이 사용한 모델보다 높은 성능을 기록
- Visual Grounding
- RefCOCO, RefCOCO+, RefCOCOg Dataset 모두에서 SOTA 성능 달성
- Visual Reasoning
- NLVR2 Task : 두 이미지 쌍이 주어진 문장을 설명할 수 있는지 여부를 판단
- SNLI-VE Task : 주어진 이미지와 텍스트쌍이 의미론적으로 중립인지, 모순적인지 등 어떻게 연관되어 있는지 판단
- 이러한 VR Task에서 매우 적은 데이터셋만으로도 SOTA급 성능을 달성했다고 시사
3) Effectiveness and Efficiency
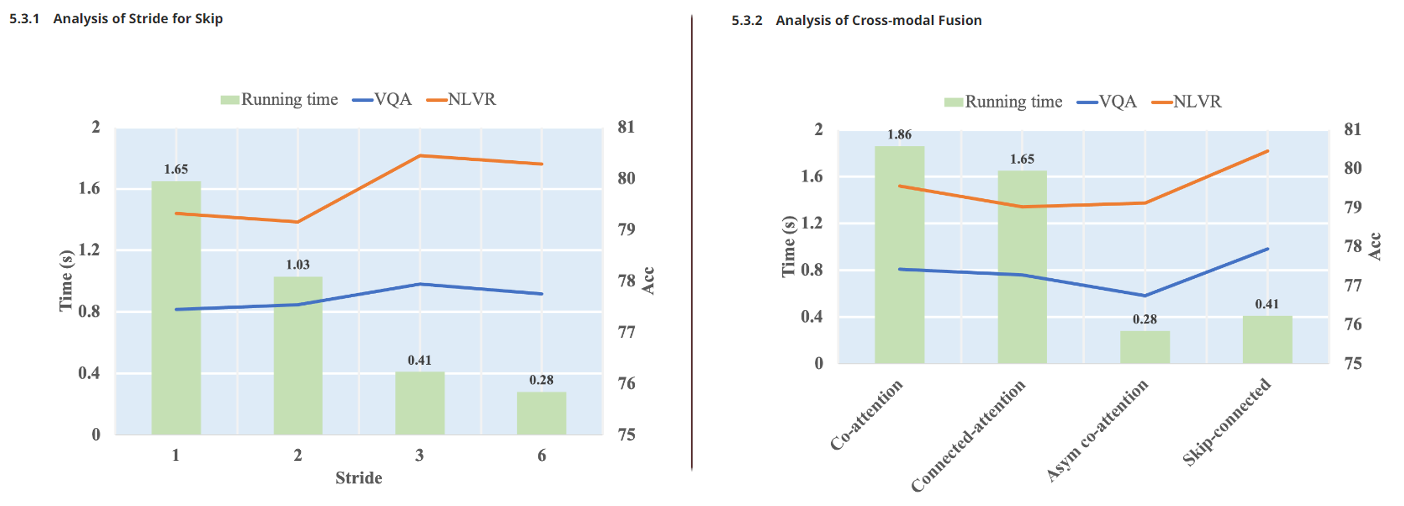
마지막 실험으로는 효율성 실험입니다. 왼쪽부터 설명을 하자면 Stride 그래프입니다. 여기서 말하는 Stride는 Model Architecture 중에 Skip Connected Fusion Block에서 텍스트는 어텐션 연산을 수행한다고 했습니다. 그 텍스트에 대해 어텐션할 때 Stride를 사용했다고 하고 그 결과 3일 때가 가장 Accuracy가 좋았지만 6일 때가 가장 속도가 빨랐다는 얘기입니다. 예를 들어, 단어 리스트 [a, b, c, d, e, f, g, h, i] 가 있을 때 Stride가 3이라면 [a, d, g], [b, e, h], [c, f, i]로 간격 3으로 어텐션 연산을 진행한다고 이해하시면 될 것 같습니다.
오른쪽 그래프는 맨 처음 Introduction에서 설명드렸던 그래프와 유사한데 앞에서부터 Self Attention과 Feed Forward Network를 겹겹이 쌓은 모델이 co attention이고 connected attention은 Skip Connection 없이 구성한 모델이고, 3번째는 BLIP 모델의 지표이고 마지막이 mPLUG 모델의 지표입니다. 그래서 따져봤을 때 BLIP보다 시간은 쪼금 더 오래 걸리지만 성능은 좋아졌다고 얘기를 하고 있습니다.
[5] Conclusions
- mPLUG는 효율적인 VLP 프레임워크 제안
- Vision Language 분야의 5가지 Task에 대해 적합시키기 위해 학습
- 기존의 Vision, Language의 정보량 차이를 해결한 Model Architecture
- 일부 Skip Connection 전략으로 이미지, 텍스트의 정보량 차이로 인한 퍼포먼스 저하를 해결
- Zero, Gradient Checkpoint, BF16 등 준수한 메모리 절약과 학습 속도 보장
- 다양한 Vision - Language Task에서 SOTA 달성
- 광범위한 작업에서 높은 성능을 보임
[6] Reference
Chat GPT
https://www.youtube.com/watch?v=6uECXx75jIo
[논문리뷰] SimVLM 논문 리뷰
오늘은 SimVLM 논문 리뷰를 가져왔습니다.해당 논문은 2022년에 ICLR에서 발표된 논문입니다.사실 논문 리뷰할 때마다 유튜브로 영상 찾아보고 관련 블로그도 찾아보는 편인데 이번 SimVLM은 논문 리
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] Whisper 논문 리뷰 (9) | 2024.08.27 |
|---|---|
| [논문리뷰] Flamingo 논문 리뷰 (0) | 2024.08.22 |
| [논문리뷰] CoCa 논문 리뷰 (0) | 2024.08.06 |
| [논문리뷰] SimVLM 논문 리뷰 (0) | 2024.08.01 |
| [논문리뷰] FILIP 논문 리뷰 (5) | 2024.07.23 |
| [논문리뷰] ALBEF 논문 리뷰 (2) | 2024.07.17 |
| [논문리뷰] T5 논문 리뷰 (0) | 2024.07.15 |
| [논문리뷰] CLIP 논문 리뷰 (0) | 2024.07.10 |



