오늘은 SimVLM 논문 리뷰를 가져왔습니다.

해당 논문은 2022년에 ICLR에서 발표된 논문입니다.
사실 논문 리뷰할 때마다 유튜브로 영상 찾아보고 관련 블로그도 찾아보는 편인데 이번 SimVLM은 논문 리뷰를 찾기 힘들어서 오로지 논문과 GhatGPT를 활용해 공부하였습니다. 그래서 설명에 약간 잘못된 부분이 있더라도 좋게 봐주시고 알려주시면 좋겠습니다 ㅎㅎ
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
저자 : Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, Yuan Cao
[1] Introduction
본 논문에서는 처음에 두 가지 이야기로 시작을 하는데 그 중 하나가 Self Supervised Textual Representation Learning입니다. 이는 자기지도 언어표현 학습이라고 할 수도 있겠네요. 여기서 자기지도 학습, Self Supervised Learning이란 주어진 데이터셋에서 어떤 패턴이나 표현 등을 모델 스스로 학습하는 방법론을 얘기합니다. Transformer 기반의 BERT와 GPT 같은 모델을 예로 들 수 있구요.
그리고 두 번째로 이야기하는 부분은 기존 VLP 모델들, 방법론들이 복잡하다는 점을 문제로 삼고 이를 보완하고자 노력했다는 겁니다. 기존의 VLP 모델들은 객체 탐지 데이터셋을 활용해 관심 영역(ROI)을 식별하고 이후 이미지와 텍스트쌍 데이터셋에서 MLM을 수행하며 사전학습을 시켰습니다. 이러한 경우에 사전 학습과 Fine Tuning 과정을 필요로 하며 각 Task마다 추가적인 손실함수를 적용해야 하는 번거로움이 존재합니다. 그래서 SimVLM에서는 PrefixLM을 통해 BERT + GPT3의 특징을 통합한 언어 모델을 활용하였고 기존 VLP 모델과는 다르게 간소화된 접근법으로 우수한 성능을 내었다고 합니다.
[2] Related Work
2-1) Self Supervised Textual Representation Learning (BERT vs GPT)

다음은 관련 연구입니다. 위에서 설명드린 것처럼 본 논문에서는 자기지도 언어표현 학습을 했다고 하는데 이를 이해하기 위해 BERT와 GPT의 차이점에 대해 간략히 살펴보고 가겠습니다. 먼저 BERT와 GPT 모두 Transformer기반의 모델들입니다. BERT는 주로 Transformer의 Encoder를 층층이 쌓아 아키텍쳐를 구성했고 GPT는 반대로 Transformer의 Decoder를 층층이 쌓아 구성하였습니다. 그래서 각각의 모델은 장단점을 가지는데, BERT는 주로 Deep Bidirectional, 즉 양방향 학습을 통한 자연어 이해 능력이 출중합니다. 하지만 Encoder 기반의 모델이라 생성 Task에는 적합하지 않다는 단점이 있죠. GPT는 Decoder 기반의 모델이기에 Auto Regressive라고 앞의 주어진 토큰들에 기반해 다음에 나올 토큰을 예측하면서 학습을 하기 때문에 생성 Task에 적합하다고 할 수 있고 여기서 Zero Shot에도 뛰어난 성능을 보인다고 할 수가 있겠습니다. 하지만 앞의 토큰을 활용해 뒤에 나올 토큰을 예측하면서 학습하기 때문에 양방향 학습이 이루어지지 않는게 단점이 되겠죠. 그래서 뒤에서도 설명하겠지만 두 방식을 모두 활용한 PrefixLM을 사용했다고 합니다.
2-2) Vision-language Pretraining
기존 VLP 모델들은 이미지에서 객체 탐지를 해서 관심 영역을 확보합니다. 이 때 Faster R-CNN 같은 좋은 모델을 활용하다보니까 비용도 증가하고 대규모 이미지와 텍스트 라벨쌍의 데이터셋을 확보해야 하는 문제가 있어서 비용 측면에서 별로라고 얘기하고 있고 이러한 구조는 다양한 Vision Language Task에 최적화시키기 위해서 손실 함수를 새롭게 설정한다거나 하는 복잡한 절차가 필요합니다. 하지만 SimVLM은 이러한 복잡성과 비용을 줄이고자 하였습니다.
[3] Model
3-1) Model Architecture
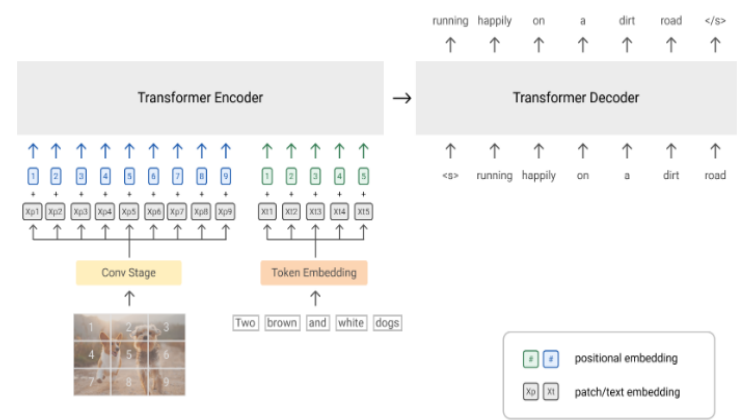
다음은 모델 아키텍쳐입니다. 왼쪽이 SimVLM의 구조도이구요. 이미지는 패치로 나누어서 각각 임베딩된 후 Encoder에 입력됩니다. 이 예시에서는 9개의 Patch로 나눴네요. 텍스트는 기존과 동일하게 토큰 임베딩으로 입력됩니다. 한 가지 특징적인 부분은 트랜스포머 기반의 아키텍쳐, 특히 PrefixLM을 사용했다는 점입니다. PrefixLM이란 입력 시퀀스에서 무작위로 접두사를 선택해 접두사인 부분과 아닌 부분으로 분리를 시키고 접두사 부분을 양방향으로 학습해 뒤에 나올 나머지 시퀀스를 예측하는 방식입니다. 여기서 이미지도 접두사로 간주될 수 있는데요. 특히 웹 문서 등에서 텍스트보다 이미지가 먼저 등장하는 경우가 많아서 이미지를 텍스트 앞에 배치해 접두사로 쓰일 수 있도록 설정했고 접두사를 양방향으로 학습하면서 이미지와 텍스트의 연결성도 학습할 수 있다고 합니다.
3-2) Prefix 예시
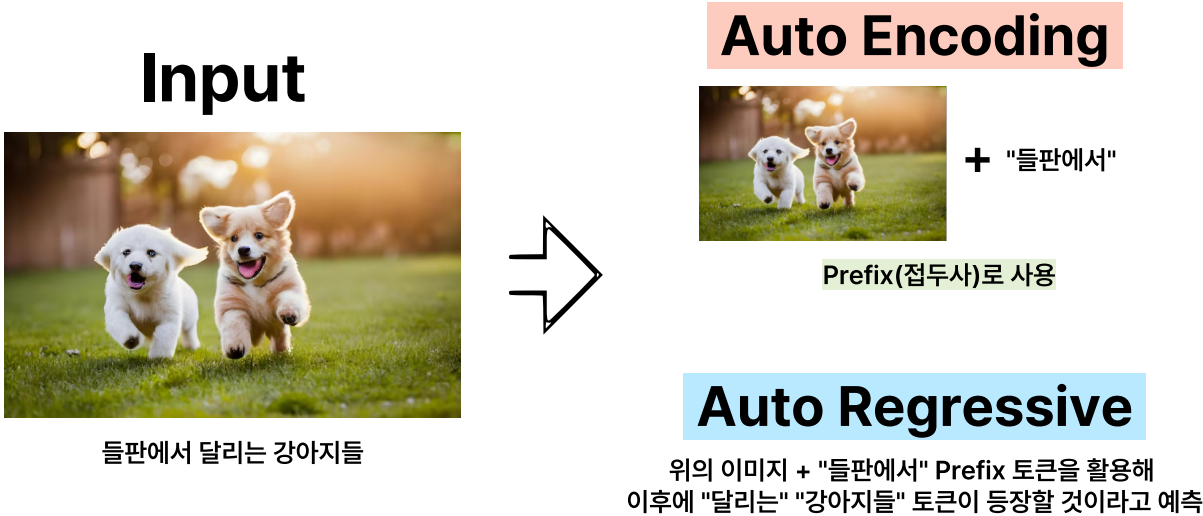
사실 이렇게만 얘기하면 PrefixLM에 대해 잘 이해가 안될 것 같아 예시를 가져왔습니다. 왼쪽처럼 이미지와 일련의 텍스트 시퀀스가 함께 입력이 됩니다. 그러면 이미지와 “들판에서”라는 토큰만 Prefix, 접두사로 사용되어서 이 때 이 접두사를 Auto Encoding, 양방향 학습을 합니다. 그리고 이미지와 들판에서 토큰을 가지고 뒤에 나올 달리는 강아지들 토큰이 등장할 것이다 하고 예측하면서 Auto Regressive 학습을 하는 이 과정을 PrefixLM이라고 쉽게 설명할 수 있을 것 같네요.
[논문리뷰] BART 논문 리뷰
자, 오늘은 X:AI Seminar 2024에서 진행한 BART 논문 리뷰를 가져왔습니다. 해당 논문은 2019년에 발표된 논문입니다. NLP 모델계의 중추 역할을 담당하고 있는 BERT와 GPT-1 의 두 모델의 각각 문제점을
dangingsu.tistory.com
3-3) Prefix 수식

수식적으로도 보겠습니다. 수식은 다음과 같은데, 빨간 밑줄 보면 T 시점에서 다음 토큰이 무엇일지 예측하는 조건부 확률을 계산합니다. 구체적으로 T 시점에 등장할 수 있는 모든 토큰에 대한 점수를 계산하고 Softmax 함수를 취해서 확률값으로 변환해서 사용합니다. 그리고 파란 밑줄처럼 이 조건부 확률값에 로그를 씌워서 합연산을 진행합니다. 여기서 로그는 수치적 안정성 때문에 씌웠다고 하구요. 그리고 확률이 1 이하의 값을 가지기 때문에 로그 조건부 확률은 음수값이 나올 겁니다. 그래서 이 음수값에 –를 곱해서 이 확률을 최대화하는 방향으로 목적함수를 설정했습니다.
3-4) Dataset 구성

다음은 Dataset 구성입니다. 위에서도 계속 설명드렸듯이 SimVLM은 객체 탐지 모듈에 의존하지 않고 Raw Image Patch를 사용하는데 이 때 웹에서 크롤링된 이미지, 텍스트쌍을 활용해 데이터셋을 구성함으로써 제로샷 일반화 능력을 향상했다고 합니다. 사실 github도 찾아보면서 어느 정도의 데이터셋 양을 구성했는지 찾아보고 싶었는데 중국어도 막 섞여있어서 구체적인 양은 찾지 못했습니다. 아쉽게도, 그래서 결국 본 모델은 이미지와 텍스트를 한 번에 학습해 비용 효율을 개선하였다고 정리할 수 있겠습니다.
[4] Experiments
4-1) Comparison with Existing Approaches

다음은 실험 부분입니다. 첫 번째 실험은 현존하는 VLP 모델들과 성능 비교입니다. 여러 벤치마크에서 성능 비교를 하였는데 그 중 이미지와 텍스트 관계성 판단 능력을 평가하는 Descriminate Task에서 기존 최고 모델인 VinVL을 크게 상회하는 성능을 보였습니다. 특히 VQA에서는 80점대가 없었는데 새롭게 80점대를 기록하기도 하였구요. 그리고 이미지 캡션 생성이나 이미지 내용을 번역 능력을 평가하는 Generation Task에서도 기존 모델들과 비슷하거나 더 뛰어난 성능을 보였습니다.
4-2) Zero-Shot Generalization

두 번째 실험은 Zero shot / Few shot 생성 능력 평가입니다. 이미지 캡션 생성에서 캡션의 정보성, 정확성, 번역 정확성 등을 평가하는 CoCa Task에서 중간에 M과 C가 캡션 정확도를 나타내는 지표거든요? 여기서 큰 폭으로 정확도가 향상되었고 새로운, 일반화된 콘텐츠를 생성할 수 있는지 평가하는 NoCaps Task에서는 모든 평가지표에 대해 성능이 향상되었습니다. 요약하자면 SimVLM은 이미지 캡션, 일반화 능력이 뛰어난 모델이라고 얘기할 수 있겠습니다.
4-3) Ablation Study

다음은 Ablation Study입니다. 모델의 각 구성요소가 전체 성능에 얼마나 미치는지 조사하였는데요. 크게 3가지로 나눠서 보면, 사전학습을 하지 않았을 때와 디코더 전용 모델일 때 성능이 크게 차이가 났죠. 아무래도 VQA 특성상 답변을 생성해야 하기 때문에 디코더 전용 모델이 VQA Task에 효과적이라는 것을 입증하였습니다. 두 번째로 Image 2 Text와 Text 2 Text를 비교했는데 확실히 Text가 VQA Task에서 중요한 역할을 하며 이미지 정보만으로는 답변을 생성하기에 부족하다는 것을 또 확인하였습니다. 세 번째로 Conv Block을 몇 개로 구성하는 것이 좋은가에 대한 실험도 진행했는데 3개의 Conv Block이 가장 좋은 성능을 보였고 이는 Resnet에서 영감을 받았다고 합니다.
[5] Conclusions
- SimVLM은 기존의 복잡한 VLP 접근법과는 달리 더 단순하고 효과적인 방법론 제안
- 객체 탐지 모델, Task별 손실함수가 필요하지 않고 PrefixLM을 통한 이미지-텍스트 연결성 학습
- 트랜스포머 기반의 Architecture 구성
- Raw Image 입력을 Patch로 나누어 처리
- 이미지 및 텍스트 일부 토큰을 접두사로 활용해 나머지 토큰을 예측하면서 AE + AR
- 다양한 Vision-Language Venchmark에서 실험 수행
- 특히 Descriminate Task, Zero Shot 부분에서 뛰어난 성능 향상
[6] Reference
https://arxiv.org/abs/2108.10904
ChatGPT
[논문리뷰] CLIP 논문 리뷰
오늘은 CLIP 논문 리뷰를 가져왔습니다. 해당 논문은 2021년에 OpenAI에서 발표한 논문입니다.Learning Transferable Visual Models From Natural Language Supervision저자 : Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh,
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] Whisper 논문 리뷰 (9) | 2024.08.27 |
|---|---|
| [논문리뷰] Flamingo 논문 리뷰 (0) | 2024.08.22 |
| [논문리뷰] mPLUG 논문 리뷰 (0) | 2024.08.18 |
| [논문리뷰] CoCa 논문 리뷰 (0) | 2024.08.06 |
| [논문리뷰] FILIP 논문 리뷰 (5) | 2024.07.23 |
| [논문리뷰] ALBEF 논문 리뷰 (2) | 2024.07.17 |
| [논문리뷰] T5 논문 리뷰 (0) | 2024.07.15 |
| [논문리뷰] CLIP 논문 리뷰 (0) | 2024.07.10 |



