오늘은 ALBEF 논문 리뷰를 가져왔습니다.

해당 논문은 2021년에 Salesforce에서 발표한 논문입니다.
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
저자 : Junnan Li, Ramprasaath R. Selvaraju, Akhilesh D. Gotmare, Shafiq Joty, Caiming Xiong, Steven C.H. Hoi
[1] Background
이미지와 텍스트를 Multi Modal로 받아 Encoder를 활용해 학습을 시키는 경우는 크게 두 가지가 있습니다.
1. Transformer-based Multi-modal Encoder
2. Unimodal Encoder
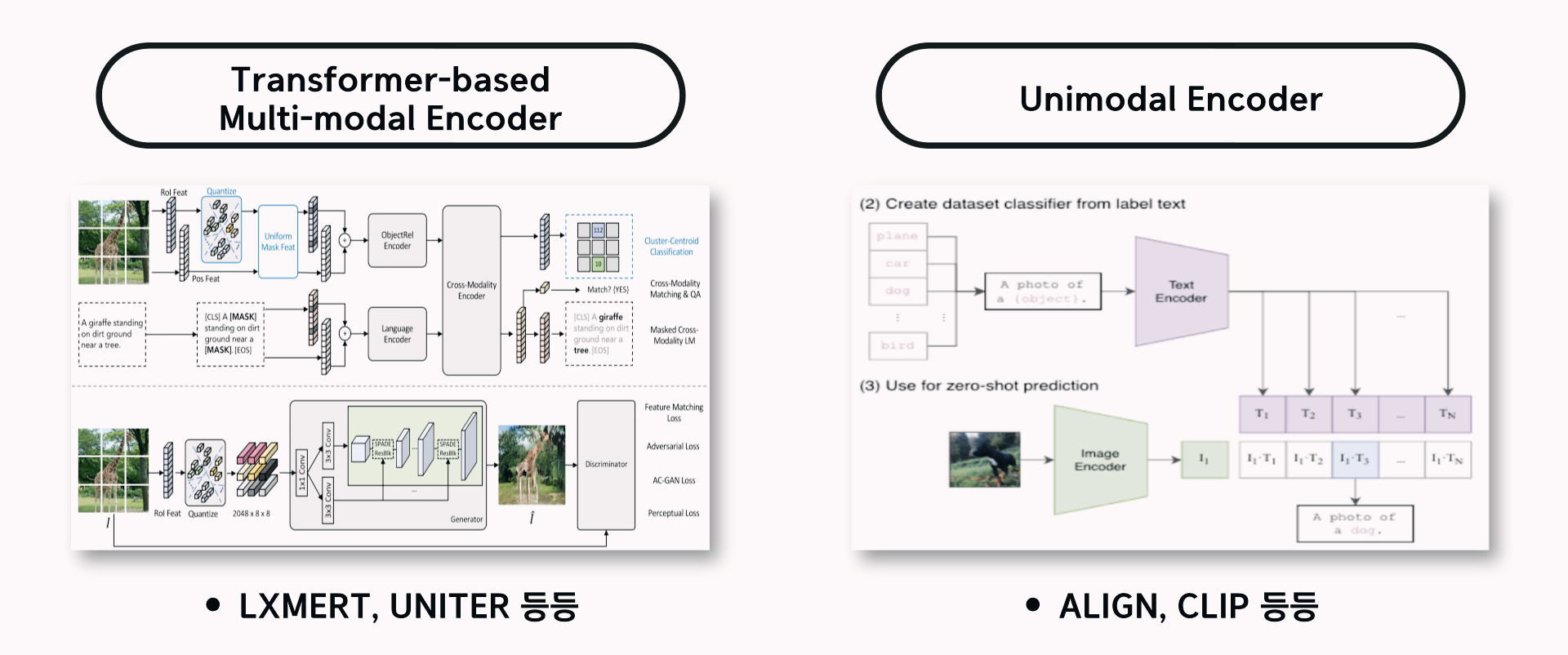
- Transformer-based Multimodal Encoder
- Transformer-based Multimodal Encoder를 사용하여 이미지와 텍스트 간 Interaction을 모델링
- 이미지와 텍스트에 대한 복잡한 추론이 필요한 NLVR2나 VQA와 같은 Downstream Task에서 우수한 성능을 달성
- But, 고해상도 이미지와 사전 훈련된 Object Detector가 필요함
- Unimodal Encoder
- 이미지와 텍스트를 위한 별도의 Unimodal Encoder 학습
- Contrastive Loss를 사용해 대규모 웹 데이터에 대한 사전학습을 수행함
- Image-Text Retrieval Task에서는 뛰어난 성능을 보이지만 다른 V + L Task에서 복잡한 Interaction을 모델링하지 못함
이번 포스팅에서 소개할 ALBEF는 이 두 가지 범주의 Encoder를 통합하여 Retrieval과 Reasoning Task 모두에서 뛰어난 성능을 발휘하는 강력한 Unimodal + Multimodal Representation을 제공하였고 기존 많은 방법에서 병목 현상을 일으키는 Object Detector가 필요하지 않다는 장점이 있습니다.
2024.07.09 - [논문리뷰] - [논문리뷰] CLIP 논문 리뷰
[논문리뷰] CLIP 논문 리뷰
오늘은 CLIP 논문 리뷰를 가져왔습니다. 해당 논문은 2021년에 OpenAI에서 발표한 논문입니다.Learning Transferable Visual Models From Natural Language Supervision저자 : Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh,
dangingsu.tistory.com
[2] ALBEF Pre-training
1) ALBEF Model Architecture

ALBEF Model Architecture는 Image Encoder, Text Encoder, Multimodal Encoder로 구성되어 있습니다. 그 중 각각을 하나씩 알아보겠습니다.
Image Encdoer는 12 Layer ViT-B/16을 사용하고 DeiT의 ImageNet-1K에서 사전학습된 가중치로 초기화하여 사용하였습니다. Image Input인 I는 일련의 임베딩 벡터 {Vcls, V1, ..., Vn}으로 인코딩되며 Vcls는 [CLS] 토큰의 임베딩 벡터를 의미합니다.
Text Encoder는 BERT base 모델의 첫 6개 Layer로 초기화하여 사용하였습니다. Image와 마찬가지로 Input Text인 T를 일련의 임베딩 벡터 {Wcls, W1, ..., Wn}으로 변환하여 Multimodal Encoder에 입력됩니다.
Multimodal Encoder는 BERT base 모델의 마지막 6개 Layer로 초기화하여 사용하였습니다. Multimodal Encoder의 각 Layer에서 Cross Attention 연산을 통해 Image Feature와 Text Feature가 융합됩니다.
두 Encoder가 Fuse되기 전에 Image - Text Pair의 Unimodal 표현을 학습하기 위해 Image - Text Contrastive Loss (ITC Loss)를 제안하였고 이미지와 텍스트 간의 Multimodal Interaction을 학습하기 위해 추가로 ITM Loss, MLM Loss를 적용하였습니다. 각각 ITM, MLM Loss가 궁금하신 분들은 UNITER 논문 리뷰를 참고해주시면 감사할 것 같습니다. 그리고 Noise가 있는 데이터에 대해 학습 과정을 개선하기 위해 학습에 Momentum Model을 사용해 Pseudo-target을 생성하여 활용해주었다고 합니다.
그래서 결국 아래 이미지와 같이 Unimodal Encoder의 Image-Text Contrastive Learning(ITC), Multimodal Encoder의 Masked Language Modeling(MLM), Image-Text Matching(ITM), 총 세 가지 Loss Function을 가지고 ALBEF를 학습시켰습니다.

그리고 여기서 In-batch Hard Negative Mining으로 ITM을 개선했다는 내용이 나오는데, In-batch Hard Negative란 한 배치 내의 데이터 샘플들 간의 관계를 사용하여 모델을 학습시키는 개념을 의미합니다. Hard Negative는 일반적으로 학습 데이터셋에서 서로 연관이 없는 것처럼 보이지만 실제로는 미묘한 관련성을 갖는 이미지와 텍스트 쌍을 의미하고 모델은 같은 배치 안의 다른 샘플들 사이의 관계를 고려하여 학습한다고 합니다. 자, 그렇다면 이제 각각의 Loss Objectives는 어떻게 구체적으로 유사도를 계산하고 예측하는지 알아보겠습니다.
2) Image-Text Contrastive Learning(ITC)
iTC는 Image-Text의 융합 전에 더 나은 Unimodal Representation을 학습하는 것이 목표입니다. Parallel Image-Text 쌍이 더 높은 유사도 점수를 가지도록 유사도 함수를 학습시킵니다. 이미지와 텍스트에서 나온 CLS 토큰의 임베딩 벡터의 차원을 768에서 256으로 정규화하는 과정이 포함되어 있습니다. 그리고 MoCo에서 영감을 받아 Momentum Unimodal Encoder에서 가장 최근 M개의 Image-Text Representation을 저장하기 위해 두 개의 Queue를 유지하는 방식을 사용했다고 합니다.
What is MoCo?
Moco : Momentum Contrast for Unsupervised Visual Representation Learning
- Query Encoder와 Query Encoder의 가중치를 Momentum 방식으로 업데이트한 Key Encoder를 사용
- Key Encoder의 출력으로 Queue 구조를 사용해 Negative Sample을 저장
- Queue를 사용함으로써 MoCo는 매우 큰 데이터셋에서도 일관된 Negative Sample을 유지할 수 있으며 이는 Contrastive Loss를 계산할 때 안정성을 가져다 줌

각 Image와 Text에 대해 Softmax-Normalized Image to Text, Text to Image 유사도를 위 사진과 같이 계산합니다. 여기서 r은 학습가능한 Temperature Parameter를 의미합니다.
Negative Pair는 0의 확률을 가지며 Positive Pair는 1의 확률을 가지는 y값을 지정합니다. 이는 One-hot Encoding에서도 나오는 개념으로 각 데이터 포인트가 어떤 클래스에 속하는지 정확하게 나타내는 특징을 가지고 Cross Entropy Loss를 줄여나가는 방식으로 학습합니다.
3) Masked Language Modeling (MLM)

MLM은 Image와 Contextual Text를 모두 활용해 마스킹된 단어를 예측하는 것이 목표입니다. 15%의 확률로 입력 토큰을 무작위로 Masking하고 특수 토큰인 [MASK]로 대체하며 Cross-Entropy Loss로 학습시킵니다.
4) Image-Text Matching (ITM)

한 쌍의 Image와 Text가 Positive(Matched)인지 Negative(Not Matched)인지 예측하는 것이 목표입니다. Multimodal Encoder의 출력에 포함된 [CLS] 토큰을 Image-Text Pair의 Joint Representation으로 사용하고 FC Layer를 추가한 다음 Softmax를 취하여 2 Class Probabillity를 예측합니다.
Computational Overhead가 전혀 없는 ITM 작업을 위해 Hard Negative Sampling 전략을 제안합니다. Image와 Text의 쌍이 비슷한 의미를 공유하지만 Fine-grained Detail이 다른 경우 Image Text 쌍은 Hard 하다고 얘기하는 식입니다. ITC의 Contrastive Similarity를 사용해 일괄적으로 Hard Negative를 찾고 미니 배치의 각 이미지에 대해 이미지와 더 유사한 텍스트가 샘플링될 확률이 높은 유사도에 따라 동일한 배치에서 하나의 Negative Text를 샘플링합니다. 반대로 각 텍스트에 대해서도 Hard Negative 이미지를 샘플링합니다.
5) Momentum Distillation
사전학습에 사용되는 이미지와 텍스트 쌍은 대부분 Web에서 수집되기 때문에 Noisy합니다. 텍스트는 이미지와 관련 없는 단어가 포함될 수 있고 이미지에는 텍스트에서 설명되지 않은 객체가 포함될 수 있으며 Positive Pair는 일반적으로 Weakly-correlated하다고 얘기할 수 있겠습니다. 반대로 Negative Pair도 관련된 이미지, 텍스트 쌍이 매핑되어 있을 수 있구요. 따라서 이를 개선하기 위해 Momentum Model에서 생성된 Pseudo-target을 활용해 학습할 것을 제안합니다.

학습 시에는 Base Model을 Momentum Model의 Prediction과 일치시켜 학습시킵니다. ITC는 Momentum Unimodal Encoder에서 Image-Text 유사도를 계산합니다. 즉 One-hot Label을 예측했던 Base Encoder에서 Distribution을 계산하는 Momentum Encoder로 변경되고 Prediction과 Ground Truth 사이의 Distribution을 일치시키기 위해 KL Divergence를 활용합니다. 여기서 KL Divergence란 두 확률분포의 차이를 계산하는 데에 사용되는 함수로 특정 분포에 대해 그 분포를 근사하는 다른 분포를 사용해 샘플링할 때 발생할 수 있는 정보의 Entropy 차이를 계산하는 개념이라고 이해하시면 될 것 같습니다. 결과적으로 이미지와 텍스트에 대한 각각의 KL Divergence를 더한 후 Base 손실함수와 Momentum 손실함수의 가중치를 조정하게 됩니다.

이 이미지는 특정 이미지와 관련된 Word / Text를 효과적으로 Capture하는 Pseudo-target의 상위 5개 Candidate를 보여줍니다. Pseudo-target은 정성적으로 Image에 Relevant한 Word / Text가 잡히고 각 Task의 최종 Loss는 Original Task Loss와 KL Divergence Loss를 활용해 가중치를 조정하는 방식으로 학습합니다.
6) Pre-training Datasets & Implementation Details
- Pre-training Datasets
- Web Dataset (Conceptual Captions, SBU Captions)
- In-domain Dataset (COCO, Visual Genome)
- Total Image : 4M / Image-Text pair : 5.1M
- 대규모의 웹 데이터로 확장 가능하다는 것을 보여주기 위해 Noise가 많은 Conceptual Image를 12M 추가해 14.1M으로 구성
- Implementation Details
- BERT base (123.7M), ViT-B/16 (85.8M)
- A100 GPU x 8EA / Batch 512 / Epoch 30 / Weight Decay 0.02 / Optimizer AdamW
- Image는 Pre-training에서 256 x 256 Random Crop, RandAugment를 적용
- Fine-tuning에서 384 x 384로 높이고 Image Patch의 Positional Encoding을 보간
- Momentum Parameter 0.995 / Queue 65,536
- Distillation Weight 0-0.4
[3] Mutual Information Maximization

본 논문의 저자들은 이미지와 텍스트 쌍을 서로 다른 시각에서 봤을 때 상호의존적인 정보의 Lower Bound를 최대화하는 방법을 제시했습니다. ITC, MLM, MoD는 서로 다른 시각을 생성하는 방법으로 해석될 수가 있고 즉, View의 변화에도 불변하는 표현을 학습하는 것이 목표라고 할 수 있겠습니다.
InfoNCE 최소화 & Mutual Information 최대화의 관계
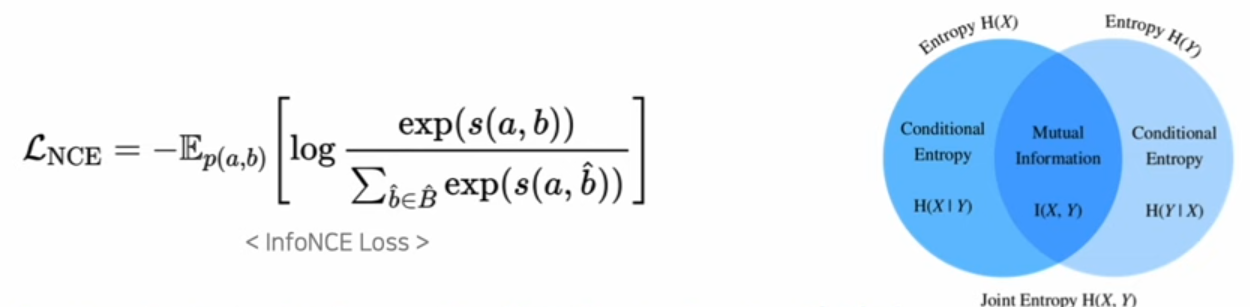
MI는 두확률변수 간의 정보적 관련성을 측정하는 방법으로 위 이미지와 같이 두 변수가 얼마나 많은 정보를 공유하고 있는지에 대해서 나타냅니다. InfoNCE Loss는 Contrastive Learning에서 사용되는 손실함수로, 비슷한 샘플 쌍은 낮은 손실값을 갖게 하고 서로 다른 샘플 쌍은 높은 손실값을 갖게 하여 모델이 두 데이터 쌍의 특성을 더 잘 이해하도록 합니다. 이러면 InfoNCE Loss를 최소화하는 과정에서 비슷한 샘플 쌍끼리 자연스럽게 모이겠죠. 그래서 결국 MI를 최대화하는 것은 InfoNCE Loss를 최소화하는 것과 같다고 얘기할 수 있습니다.
수식적으로 봤을 때 B에 대한 정답값을 제외한 나머지 샘플들은 모두 Negative Sample이 되고 ITC Loss를 최소화하는 것은 InfoNCE와 유사합니다. 이미지와 텍스트 쌍에 대한 예측 토큰의 Lookup Table로부터 Representation이 도출되고 두 Representation 사이의 유사도를 Dot product로 근사할 수 있습니다. 따라서 MLM Loss를 최소화하는 것은 Masked Token과 Context 사이의 MI를 최대화하는 과정이라고 할 수 있습니다.
그래서 결국
- ITC : Image와 Text 사이의 관계성을 학습
- MLM : Text-Image + Text에 대한 2가지 View에 대한 학습
- MoD : Pseudo Target을 만들기에 원래 이미지, 텍스트 쌍에 없는 새로운 View를 생성해 학습
- 이는 원본 이미지, 텍스트 쌍에 없는 다양한 View를 추가로 생성하고, Base 모델이 View의 변화에도 불변하는 표현을 학습하도록 장려함
[4] DownStream V + L Tasks
- Image-Text Retrieval
- Image-to-Text Retrieval(TR)과 Text-to-Image Retrival(IR)이라는 두 가지 Subtask가 포함
- Flick30K 및 COCO 벤치마크에서 ALBEF를 평가하고 각 데이터셋의 Training Sample을 사용해 사전학습된 모델을 Fine-tuning
- Fine-tuning시에는 ITC Loss와 ITM Loss를 함께 최적화
- ITC는 유니모달 피쳐 유사성을 기반으로 이미지와 텍스트 점수를 학습하는데 ITM은 이미지와 텍스트 간 Fine-grained Interaction을 모델링해 일치하는 점수를 예측
- Visual Entailment
- 이미지와 텍스트의 관계가 Entailment / Neutral / Contradictory인지 예측하는 Fine-grained Visual Reasoning Task
- UNITER를 따라 Visual Entailment를 3중분류 문제로 간주하고, Multimodal Encoder의 [CLS] Token 표현에 대해 MLP로 클래스 확률을 예측
- Visual Question Answering (VQA)
- 이미지와 질문이 주어지면 모델이 답을 예측하는 Task
- VQA를 Multi-Answer Classification 문제로 공식화하는 기존 방법과 달리, Answer Generation 문제로 간주
- Auto-Regressive Answer Decoder는 Cross-Attention을 통해 Multimodal Embedding을 수신
- Answer Decoder는 Multimodal Encoder에서 미리 학습된 가중치를 사용해 초기화되고 Conditional Language-Modeling Loss로 Fine-tuning시켜서 예측
- Natural Language for Visual Reasoning
- 텍스트가 한 쌍의 이미지를 설명하는지 여부를 예측하는 모델을 필요로 함
- 두 개의 이미지에 대한 추론이 가능하도록 Multimodal Encoder를 확장함
- Multimodal Encoder의 각 레이어는 두 개의 연속적인 Transformer 블록으로 복제되며, 각 블록에는 Self-Attention Layer, Cross Attention Layer, Feed-Forward Layer가 포함되어 있음
- Visual Grounding
- 이미지에서 특정 Textual Description에 해당하는 영역의 위치를 파악하는 것을 목표로 함
- Bounding Box 주석을 사용할 수 없는 Weakly-supervised Setting을 연구
[5] Experiments
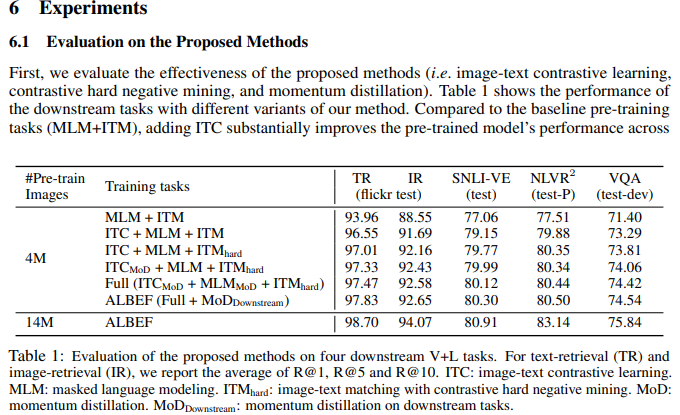
첫 번째 실험은 ITC, MLM, ITM 등 제안된 방법론에 대한 효과를 평가하는 실험입니다. ITC를 추가하면 모든 작업에서 사전 훈련된 모델 성능이 크게 향상된 것을 알 수 있고 제안된 Hard Negative Mining은 Information Training Sample을 찾아냄으로써 ITM을 개선하였습니다. Momentum Distillation을 추가하면 ITC, MLM 등 모든 Downstream 작업에서 성능이 향상하였습니다.

두 번째 실험은 Fine-tuning 시의 Zero-shot Retrieval의 성능입니다. 훨씬 큰 데이터셋에서 훈련된 CLIP, ALIGN을 능가하는 SOTA 성능을 달성하였고 Traning Image 수가 4M에서 14M으로 늘어날 때 (Noisy한 웹 이미지 데이터를 추가했을 때) 성능이 크게 향상하였습니다. 더 큰 규모의 웹 이미지, 텍스트 쌍을 훈련시킴으로써 더 성능이 향상할 수 있는 잠재력을 가지고 있다고 얘기할 수 있겠네요.
[6] Conclusion
- 본 논문에서는 Vision Language Representation Learning을 위한 새로운 모델 ALBEF 제안
- ALBEF는 Unimodal Image Representation과 Text Representation을 맞춰준 후 Multimodal Encoder와 혼합
- 제안된 Image-Text Contrastive Learning과 Momentum Distillation의 효과를 실험적으로 검증함
- 기존 방법론과 비교해 ALBEF는 여러 DownStream Task에서 더 나은 SOTA 성능과 빠른 속도를 제공
- VLP 분야에서 유망한 결과를 보여주지만 웹 데이터를 수집하여 학습하였기 때문에 개인정보 혹은 유해한 내용이 담길 수 있고 성능만 최적화하는 것은 원치 않는 사회적 영향을 줄 수 있기에 데이터와 모델에 대한 추가 검증이 필요함
[7] Reference
https://www.youtube.com/watch?v=rCgJn9u4eXY&t=559s
https://arxiv.org/abs/2107.07651
[논문리뷰] Flamingo 논문 리뷰
오늘은 Flamingo 논문 리뷰를 가져왔습니다.해당 논문은 2022년에 NeurIPS 에서 발표된 논문입니다. 저자가 참 많네요..Flamingo: a Visual Language Model for Few-Shot Learning저자 : Jean-Baptiste Alayrac, Jeff Donahue, Pau
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] mPLUG 논문 리뷰 (0) | 2024.08.18 |
|---|---|
| [논문리뷰] CoCa 논문 리뷰 (0) | 2024.08.06 |
| [논문리뷰] SimVLM 논문 리뷰 (0) | 2024.08.01 |
| [논문리뷰] FILIP 논문 리뷰 (5) | 2024.07.23 |
| [논문리뷰] T5 논문 리뷰 (0) | 2024.07.15 |
| [논문리뷰] CLIP 논문 리뷰 (0) | 2024.07.10 |
| [논문리뷰] XL-Net 논문 리뷰 (0) | 2024.07.03 |
| [논문리뷰] Transformer 논문 리뷰 (0) | 2024.06.26 |



