오늘은 Flamingo 논문 리뷰를 가져왔습니다.

해당 논문은 2022년에 NeurIPS 에서 발표된 논문입니다. 저자가 참 많네요..
Flamingo: a Visual Language Model for Few-Shot Learning
저자 : Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, Karen Simonyan
[1] Introduction

플라밍고(Flamingo)는 다양한 비전과 언어 작업에 대해 최첨단의 성과를 달성할 수 있는 시각 언어 모델(VLM)입니다. 이 모델은 특히 소량의 예시를 통한 학습(퓨샷 러닝)에 강점을 보이며, 복잡한 작업도 간단한 프롬프팅만으로 수행할 수 있습니다. 기존의 모델들이 대규모의 데이터와 함께 세밀한 하이퍼파라미터 튜닝을 필요로 하는 것과 대비되어, 플라밍고는 매우 적은 양의 작업 특화 데이터를 사용함에도 불구하고 뛰어난 성능을 보입니다. 예를 들어, 이미지를 분류하거나, 이미지에 대한 설명을 생성하거나, 시각적 질문에 대답하는 등의 작업을 수행할 수 있습니다. 이는 모델이 이미지와 텍스트를 함께 입력받아 텍스트 출력을 생성할 수 있기 때문입니다.
Flamingo의 아키텍처는 두 가지 주요 구성 요소로 이루어져 있습니다: 하나는 시각적 장면을 '인지'할 수 있는 비전 모델과 다른 하나는 기본적인 추론을 수행할 수 있는 큰 언어 모델(LM)입니다. 이 두 모델 사이에는 지식을 보존하면서 이들을 연결하는 새로운 구조적 요소들이 추가되어 있습니다. 이를 통해 Flamingo는 멀티모달 언어 및 이미지/비디오 이해 작업 16개 중 6개에서 최고의 성능을 나타내며, 기존의 최고 기술보다 우수한 성능을 보여줍니다. 이 모델은 특히 주어진 작업에 대해 극히 적은 수의 특정 훈련 데이터만을 사용함에도 불구하고 우수한 성과를 보여줍니다.
[2] Approach

Flamingo는 사전 학습된 언어 모델 레이어와 새로운 크로스 어텐션 레이어를 결합하여 시각적 데이터를 처리합니다. 이 레이어들은 이미지 또는 비디오로부터 추출된 시각적 특성(키와 값)과 텍스트 입력에서 파생된 쿼리를 사용하여 정보를 통합합니다.
- Perceiver Resampler: 시각 인코더에서 받은 다양한 크기의 특성 맵을 고정된 수의 시각적 토큰으로 변환합니다. 이렇게 함으로써, 모델은 크로스 어텐션을 통해 효율적으로 시각적 데이터를 언어 처리와 결합할 수 있습니다.
- Language Model (LM) Layers: 사전 훈련된 LM 레이어들은 텍스트 데이터의 처리를 담당하며, 이 레이어들 사이에 새로운 크로스 어텐션 레이어가 삽입됩니다.
Gated XATTN-DENSE 레이어
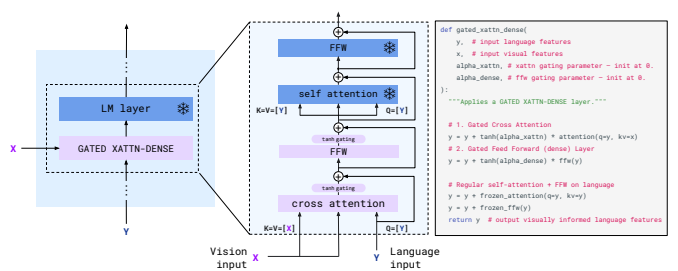
새롭게 도입된 'gated xattn-dense' 레이어는 시각적 입력에 기반해 언어 모델의 반응을 조정합니다. 이 레이어는 다음과 같은 구성 요소로 이루어져 있습니다:
- 크로스 어텐션: 시각적 특성을 키와 값으로 사용하고, 언어 입력에서 파생된 쿼리를 사용하여 언어와 시각 데이터 사이의 관계를 맺습니다.
- Dense Feed-Forward Network: 크로스 어텐션의 결과를 처리하여 더 복잡한 표현을 생성합니다.
- Gating Mechanism: tanh 함수를 통한 게이팅 메커니즘은 새로운 레이어의 출력을 조절하여, 모델 초기화 시 사전 훈련된 언어 모델의 출력과 일치하도록 합니다. 이는 훈련의 안정성을 보장하고 성능을 개선합니다.
1) Visual processing and the Perceiver Resampler
Vision Encoder는 사전 학습된 Normalizer-Free ResNet (NFNet)을 사용하여 이미지나 비디오의 픽셀 데이터를 고차원의 특성 데이터로 변환합니다. 예를 들어, 비디오의 경우 각 프레임을 독립적으로 처리하여 3차원의 시공간 그리드 특성을 생성하고, 이를 1차원 시퀀스로 평탄화합니다. 이러한 고차원 특성은 이미지와 텍스트 쌍에 대한 대조적 목표를 사용하여 학습됩니다.
Perceiver Resampler는 Vision Encoder에서 나온 다양한 크기의 특성 맵을 받아 고정된 수의 시각적 토큰(예: 64개)으로 변환합니다. 이 과정은 비전-텍스트 크로스 어텐션의 계산 복잡성을 줄이는 데 중요합니다. 이 모듈은 사전 정의된 수의 latent input queries를 Transformer에 전달하고, 이 Transformer는 시각적 특성에 대해 Cross Attention을 수행합니다. 이 구조는 일반 Transformer나 MLP보다 우수한 성능을 나타내는 것으로 나타났습니다.
예를 들어, 사용자가 "매우 귀여운 강아지"라는 텍스트와 강아지 이미지를 입력으로 제공하면, Vision Encoder는 이미지를 특성 데이터로 변환하고, Perceiver Resampler는 이 데이터를 시각적 토큰으로 압축합니다. 이 시각적 토큰은 언어 모델에 입력되어, 모델이 이미지 내용을 이해하고 관련된 텍스트를 생성할 수 있도록 합니다. 결과적으로 모델은 " 매우 귀여운 강아지 "라는 문장을 자연스럽게 이어나갈 수 있습니다.
2) Conditioning frozen language models on visual representations
Flamingo 모델은 멀티모달 모델의 성능을 높이기 위해, 사전 훈련된 언어 모델(LM)을 시각적 데이터에 기반하여 구조화하는 방식을 사용합니다. 이 구조의 주요 요소는 Transformer 디코더, Perceiver Resampler, 그리고 'gated xattn-dense' 레이어입니다.
Flamingo의 텍스트 생성 과정은 Transformer 디코더에 의해 수행되며, 이 디코더는 Perceiver Resampler로부터 생성된 시각적 표현에 따릅니다. Perceiver Resampler는 시각적 입력을 처리하여 고정된 수의 시각적 토큰을 생성하고, 이 토큰들이 언어 모델의 입력으로 활용됩니다. 'Gated xattn-dense' 레이어는 사전 훈련된 언어 모델 레이어 사이에 새롭게 삽입되며, 이 레이어들은 시각적 출력에 크로스 어텐션을 수행합니다. 이 레이어들은 사전 훈련된 LM 레이어와 결합되어, 시각적 데이터를 통합하는 새로운 방식을 제공합니다.

- tanh-gating 메커니즘: 이 메커니즘은 새로 추가된 레이어의 출력에 tanh(α)를 곱하여 입력 표현에 추가합니다. 여기서 α는 레이어별로 학습 가능한 스칼라 값으로, 초기에는 0으로 설정되어, 초기화 시 사전 훈련된 모델의 출력과 일치하게 합니다. 이는 모델의 훈련 안정성과 최종 성능을 향상시킵니다.
Flamingo 모델은 다양한 크기로 실험되며, 1.4B, 7B, 70B 파라미터를 가진 Chinchilla 모델을 기반으로 합니다. 각각 Flamingo-3B, Flamingo-9B, Flamingo-80B로 불리며, 논문에서는 이 중 가장 큰 모델을 일반적으로 Flamingo라고 합니다. 모든 모델에서 사전 훈련된 비전 인코더의 크기는 고정되어 있으며, 학습 가능한 Perceiver Resampler의 크기는 모델에 따라 조정됩니다.
3) Multi-visual input support: per-image/video attention masking
Flamingo는 각 텍스트 토큰에서 모델이 볼 수 있는 시각적 토큰을 제한하는 방식으로 텍스트-이미지 크로스 어텐션 매트릭스를 마스킹합니다. 이는 모델이 각 텍스트 토큰에서 직전에 나타난 이미지의 시각적 토큰에만 주목하도록 합니다. 이 방식은 모델이 훈련 중 사용된 이미지의 수와 관계없이 어떤 수의 시각적 입력에도 일반화할 수 있도록 합니다. 특히, 평가 중에는 최대 32쌍의 이미지/비디오와 해당 텍스트를 처리할 수 있음에도 불구하고 훈련에는 시퀀스당 최대 5개의 이미지만 사용됩니다.
예시: 사용자가 여러 이미지를 포함하는 글을 입력했다고 가정합시다. Flamingo는 각 텍스트 조각을 입력받을 때, 그 텍스트 직전에 제시된 이미지에만 주의를 기울이므로, 연속적인 이미지의 컨텍스트를 유지하면서도 각 이미지에 특화된 텍스트 응답을 생성할 수 있습니다.
4) Training on a mixture of vision and language datasets
- M3W (MultiModal MassiveWeb) 데이터셋: 이 데이터셋은 약 4천3백만 웹페이지의 HTML에서 텍스트와 이미지를 추출하여, 문서 객체 모델(DOM)에서 텍스트와 이미지 요소의 상대적 위치를 기반으로 구성됩니다. 각 문서에서는 최대 256개의 토큰과 최대 5개의 이미지를 샘플링합니다.
- ALIGN 및 LTIP 데이터셋: 18억 개의 이미지와 대체 텍스트 쌍을 포함하는 ALIGN 데이터셋과, 더 높은 품질과 더 긴 설명을 목표로 하는 3억 12백만 개의 이미지와 텍스트 쌍을 포함하는 LTIP 데이터셋을 사용합니다.
- VTP (Video & Text Pairs) 데이터셋: 평균 22초 길이의 2700만 개의 짧은 비디오와 문장 설명 쌍을 포함합니다.
멀티-목적 훈련 및 최적화 전략: 모델은 각 데이터셋의 기대 음의 로그 가능도의 가중합을 최소화하는 방식으로 훈련됩니다. 각 데이터셋의 가중치를 조절하는 것이 성능에 중요하며, 모든 데이터셋의 기울기를 누적하는 방식은 '라운드 로빈' 접근 방식보다 우수한 성능을 보입니다.
5) Task adaptation with few-shot in-context learning
이 방식은 GPT-3의 인컨텍스트 학습과 유사하게, 지원 예시 쌍을 사용하여 모델을 새로운 태스크에 빠르게 적응시킵니다.
모델의 성능 평가는 두 가지 방식으로 이루어집니다:
- Open-Ended 평가: 빔 서치(beam search) 디코딩 방식을 사용하여, 모델이 자유롭게 답변을 생성할 수 있도록 합니다.
- Close-Ended 평가: 모델이 제공하는 각 가능한 답변에 대한 로그-가능도(log-likelihood)를 이용해 평가합니다.
또한, 모델의 제로-샷 일반화 능력을 평가하기 위해, 해당 이미지 없이 텍스트만을 포함한 두 개의 예시를 프롬프트로 사용하여 태스크를 수행하도록 합니다. 이는 모델이 이미지 없이도 텍스트 정보만으로 새로운 상황에 어떻게 반응할 수 있는지를 테스트합니다.
[3] Experiments
1) Few-shot learning on vision-language tasks

Flamingo 모델은 다양한 멀티모달 이미지 및 비디오 언어 벤치마크를 통해 빠른 태스크 적응 능력을 검증합니다. 모델은 16개의 주요 멀티모달 벤치마크에서 최신 기술의 성능을 뛰어넘는 few-shot 학습 결과를 달성하며, 이는 모델의 실질적인 적응성과 효율성을 입증합니다.
- Few-Shot 학습: Flamingo는 최소 4개의 예제를 사용하여 새로운 태스크에 대해 빠르게 적응하며, 특히 32개의 예제만 사용해도 현재 최고의 메소드를 능가하는 성능을 보여줍니다.
- 태스크 스케일링: 모델의 크기가 클수록, 그리고 사용하는 예제의 수가 많을수록 few-shot 성능이 향상됩니다.
2) Fine-tuning Flamingo as a pretrained vision-language model
Flamingo는 사전 학습된 비전-언어 모델로서, 주로 few-shot 학습 방식으로 연구되었지만, 데이터가 풍부한 경우 모델 가중치를 파인튜닝하여 특정 태스크에 맞춰 최적화할 수도 있습니다.
- 단기 스케줄과 작은 학습률: 파인튜닝은 짧은 스케줄을 사용하며, 학습률을 작게 설정하여 진행합니다. 이는 모델이 새로운 태스크에 빠르게 적응하도록 돕기 위함입니다.
- 비전 백본 해제: 높은 입력 해상도를 수용하기 위해 비전 백본을 해제합니다. 이는 세부 이미지 특성을 더 잘 포착할 수 있게 하여, 결과적으로 모델의 예측 정확도를 높입니다.
- 새로운 최고 기록: 파인튜닝을 통해 Flamingo는 VQAv2, VATEX, VizWiz, MSRVTTQA, HatefulMemes 등의 태스크에서 기존의 최고 기록을 갱신합니다. 이들은 모델이 few-shot 학습만으로는 최고 성능을 달성하지 못한 태스크들입니다.
- 전체 9개 태스크 중 5개에서 최고 기록: Flamingo는 9개의 task 중 5개의 task에서 파인튜닝을 통해 최고 성능을 기록했습니다.
3) Ablation studies

Flamingo 모델의 ablation study는 다양한 설정 변경이 모델 성능에 미치는 영향을 조사합니다. 이 연구는 모델의 각 구성 요소가 전체적인 성능에 어떻게 기여하는지를 평가하여, 최적의 모델 설계를 도출하는 데 중요한 통찰을 제공합니다.
1. 학습 데이터의 중요성
- M3W 이미지-텍스트 인터리브 데이터셋을 제거하면 성능이 약 17% 감소합니다. 이는 인터리브된 데이터셋이 모델 성능에 중요함을 시사합니다.
- 전통적인 이미지-텍스트 쌍을 제거할 경우 성능이 9.8% 감소합니다.
- 비디오-텍스트 쌍을 제거하면 모든 비디오 태스크에서 성능이 저하됩니다.
2. 계산 및 메모리 대 성능 트레이드오프
- 새로운 gated xattn-dense 블록을 모든 레이어에 추가하는 것이 성능에는 좋으나, 훈련 가능한 매개변수의 수와 모델의 시간 복잡성을 크게 증가시킵니다.
- 블록을 4개 레이어마다 추가하는 것은 훈련 시간을 66% 단축시키며 성능 저하는 1.9%에 불과합니다.
3. 비전 인코더의 영향
- NFNet-F6 비전 인코더는 CLIP ViT-L/14 모델과 비교하여 5.8% 높은 성능을 보여줍니다. 이는 강력한 비전 백본의 중요성을 강조합니다.
4. 언어 모델 컴포넌트 동결의 중요성
- LM 컴포넌트를 동결하지 않고 처음부터 훈련할 경우 성능이 12.9% 감소합니다.
- 사전 훈련된 LM을 파인튜닝하면 성능이 8.0% 감소합니다. 이는 새로운 목표에 대한 훈련 중에 모델이 사전 학습을 잊어버리는 “catastrophic forgetting” 현상을 나타냅니다.
[4] Discussion
- 제한사항 및 성능 한계
- 사전 학습된 언어 모델의 한계 상속: Flamingo는 사전 학습된 언어 모델을 기반으로 하기 때문에, 기존 언어 모델의 약점을 그대로 물려받습니다. 예를 들어, 때때로 발생하는 허구적 추측이나 근거 없는 추론은 언어 모델의 기본적인 한계에서 비롯됩니다.
- 분류 성능의 지연: Flamingo는 텍스트-이미지 검색 최적화에 중점을 둔 최신 대조적 모델에 비해 분류 성능이 뒤처집니다. Flamingo는 다양한 태스크를 처리할 수 있으나, 특정 태스크의 최적화가 부족할 수 있습니다.
- 인컨텍스트 학습의 한계: 인컨텍스트 학습은 적은 데이터에서 유리하지만, 적용 특성에 따라 제한적일 수 있습니다. 또한, 사용 예시가 많아질수록 추론 비용이 증가하고 성능이 저하될 수 있습니다.
- 사회적 영향
- 긍정적 영향: Flamingo는 비전문가 사용자도 데이터가 부족한 환경에서 좋은 성능을 낼 수 있게 하여, 기술 접근성을 높일 수 있습니다.
- 부정적 영향: Flamingo는 기존 대규모 언어 모델과 마찬가지로 부적절한 언어 사용, 사회적 편견 및 스테레오타입 전파, 개인 정보 누출 등의 위험을 지니고 있습니다. 또한 시각적 입력을 다루면서 성별이나 인종에 대한 편견을 불러일으킬 수 있는 위험이 있습니다.
- Flamingo는 이미지 및 비디오 태스크에 최소한의 태스크 특화 학습 데이터로 적용 가능한 범용 모델로 제안됩니다. 모델의 상호작용 능력도 탐구되어, 전통적인 시각 벤치마크를 넘어서는 유연성을 보여줍니다.
- 이 연구는 DeepMind에 의해 자금 지원을 받았으며, 다수의 동료들의 유용한 토론과 피드백이 있었습니다.
[5] References
Chat GPT
https://arxiv.org/pdf/2204.14198
https://youtu.be/ihdHsoPin84?si=fqTrXz7t-KIt5SwR
[논문리뷰] CoCa 논문 리뷰
오늘은 CoCa 논문 리뷰를 가져왔습니다.해당 논문은 2022년에 CVPR에서 발표된 논문입니다.CoCa: Contrastive Captioners are Image-Text Foundation Models저자 : Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosse
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] MoblieNet 논문 리뷰 (2) | 2025.01.12 |
|---|---|
| [논문리뷰] SPPNet 논문 리뷰 (0) | 2025.01.08 |
| [논문리뷰] Inception v2, v3 논문 리뷰 (1) | 2025.01.04 |
| [논문리뷰] Whisper 논문 리뷰 (9) | 2024.08.27 |
| [논문리뷰] mPLUG 논문 리뷰 (0) | 2024.08.18 |
| [논문리뷰] CoCa 논문 리뷰 (0) | 2024.08.06 |
| [논문리뷰] SimVLM 논문 리뷰 (0) | 2024.08.01 |
| [논문리뷰] FILIP 논문 리뷰 (5) | 2024.07.23 |



