인공지능 챗봇은 일정 관리부터 고객 지원 제공까지 모든 것을 지원하면서 오늘날 우리 삶에 없어서는 안 될 존재가 되었습니다. 그러나 이와 같이 고도화되면서 '환각', 할루시네이션이라는 우려되는 문제가 대두되었습니다. LLM에서 할루시네이션은 챗봇이 부정확하거나 오해의 소지가 있거나 완전히 조작된 정보를 생성하는 경우를 의미합니다.

가상 비서에게 날씨에 대해 물어보면 한 번도 일어나지 않은 폭풍에 대한 오래되었거나 완전히 잘못된 정보를 제공하기 시작한다고 상상해 봅시다. 이는 흥미로울 수 있지만 의료 또는 법률 자문과 같은 중요한 영역에서는 이러한 환각이 심각한 결과를 초래할 수 있습니다. 따라서 LLM에서 할루시네이션이 발생하는 이유를 이해하는 것은 AI 챗봇의 신뢰성과 안전성을 높이는 데 필수적입니다.
1. AI 챗봇의 기본
AI 챗봇은 인간의 언어를 이해하고 생성할 수 있는 알고리즘을 기반으로 하며, 규칙 기반 모델과 생성 모델이라는 두 가지 주요 유형이 있습니다.
1) 규칙 기반 챗봇
규칙 기반 챗봇은 미리 정의된 규칙이나 스크립트를 따릅니다. 레스토랑에서 테이블을 예약하거나 일반적인 고객 서비스 질문에 답변하는 등 간단한 작업을 처리할 수 있습니다. 이러한 챗봇은 제한된 범위 내에서 작동하며 특정 트리거나 키워드를 사용하여 정확한 응답을 제공합니다. 그러나 그 유연성으로 인해 더 복잡하거나 예상치 못한 쿼리를 처리하는 능력이 제한됩니다. 대충 러프하게 아래처럼 간단한 규칙 기반 챗봇을 만들 수 있겠죠.
## 파이썬으로 간단한 챗봇을 만들어보자
## 인사 기능 정의
def say_hello(name, year):
print(f"Chatbot: 안녕하세요, 저는 {name}입니다. 저는 {year}에 태어났습니다.")
print("챗봇: 오늘 무엇을 도와드릴까요?")
## 응답 함수
def chatbot_response(user_input):
if user_input == "안녕하세요":
return "안녕하세요! 오늘 무엇을 도와드릴까요?"
elif user_input == "안녕히 계세요":
return "안녕히 가세요! 좋은 하루 되세요."
elif user_input == "당신의 좋은 이름은 무엇입니까?":
return "제 이름은 챗봇입니다."
elif user_input == "당신의 출생 연도는 언제입니까?":
return "저는 2024년에 태어났습니다."
elif user_input == "당신은 무엇을 할 수 있나요?":
return "나는 당신의 질문에 대답하고, 당신과 대화하고, 기본적인 업무를 수행할 수 있습니다."
elif "날씨" in user_input:
return "현재 날씨를 확인할 수 없습니다. 죄송합니다."
else:
return "죄송합니다. 무슨 말을 하려는지 잘 모르겠습니다. 다시 말해 주시겠습니까?"
name = "챗봇"
year = 2024
say_hello(name, year)
if __name__ == '__main__':
user_input = input("You: ")
response = chatbot_response(user_input)
print(f"챗봇: {response}")
if user_input == "안녕히 계세요":
exit()
## Chatbot: 안녕하세요, 저는 챗봇입니다. 저는 2024년도에 태어났습니다.
## 챗봇: 오늘 무엇을 도와드릴까요? 안녕하세요
## 챗봇: 안녕하세요! 오늘 무엇을 도와드릴까요?
2) 생성 모델
반면, 생성 모델(LLM)은 언어 모델이 자연어를 학습하고 이를 활용한 답변을 생성합니다. 이러한 모델은 방대한 양의 텍스트 데이터, 학습 패턴, 알고리즘 등에 대해 훈련되었습니다. 예를 들어, OpenAI의 GPT 시리즈나 BERT, BART, Claude, Llama 등등의 모델들이 있겠죠. 이러한 모델은 보다 유연하고 상황에 맞는 응답을 생성할 수 있어 규칙 기반 챗봇보다 더 일반화 성능이 좋고 적응력이 뛰어납니다. 하지만 이러한 생성 모델들은 확률론에 의거하여 답변을 생성하기 때문에 할루시네이션에 더욱 취약하게 됩니다.
## Trainer 설정
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
callbacks=[early_stopping_callback]
)
## 모델 Fine Tuning 진행
trainer.train()2. 할루시네이션이란?
자, 그럼 위에서부터 계속 이야기하는 할루시네이션이란 무슨 개념인지 알아보겠습니다. 할루시네이션은 LLM이 실제로 일어나지 않은, 사실이 아닌 것을 사실인 것처럼 이야기하는 환각 현상을 의미합니다. 이는 역사적 사건의 날짜를 잘못 파악하는 것과 같은 간단한 오류일 수도 있고 전체적인 이야기나 의학적 권장 사항을 잘못 이야기하는 것처럼 복잡한 문제일 수도 있습니다. 인간의 할루시네이션은 외부 자극이 없는 감각적 경험이며 종종 심리적 또는 신경학적 요인으로 인해 발생하는 반면, LLM의 할루시네이션은 모델의 잘못된 해석이나 훈련 데이터의 과적에서 비롯됩니다. 예를 들어, LLM이 공룡에 관한 많은 텍스트를 읽었다면 존재한 적이 없는 새로운 가상의 공룡 종을 잘못 생성할 수 있습니다.

[NLP] LLM Prompt Engineering
오랜만에 돌아왔습니다. 컨퍼런스하랴, 인턴생활하랴, 공모전하랴, 일본어 공부하랴 너무 현생이 바빠서 한 달 동안 블로그를 쓰지 못하였네요. 그래서 오랜만에 돌아왔으니 재미난 이야기를
dangingsu.tistory.com
LLM의 할루시네이션은 딥러닝 이전, 머신러닝 초기부터 존재해 왔습니다. 상대적으로 단순한 초기 모델은 다음과 같이 제안하는 등 심각하게 의심스러운 실수를 저지르는 경우가 많았습니다. "파리는 이탈리아의 수도이다.." AI 기술이 발전함에 따라 할루시네이션은 더 미묘해졌지만 잠재적으로 더 위험해졌습니다. 처음에는 이러한 AI 오류가 단순한 변칙이나 호기심으로 간주되었지만, 중요한 의사결정 과정에서 AI의 역할이 커짐에 따라 이러한 문제를 해결하는 것이 점점 더 시급해졌습니다. 특히 의료, 법률 자문, 고객 서비스 등 민감한 분야에 LLM을 통합하면 할루시네이션과 관련된 위험이 높아집니다. 따라서 AI 시스템의 신뢰성과 안전성을 보장하려면 이러한 발생을 이해하고 완화하는 것이 필수적입니다.
3. LLM, 할루시네이션의 원인
LLM에서 할루시네이션이 발생하는 이유를 이해하기 위해서는 여러 상호 연결된 요소를 분석해야 합니다.
1) 데이터의 품질 문제

훈련 데이터의 품질은 매우 중요합니다. LLM은 제공된 데이터를 통해 학습하므로 훈련 데이터가 편향되거나 오래되었거나 부정확한 경우 LLM의 출력에 이러한 결함이 반영됩니다. 예를 들어, LLM이 시대에 뒤떨어진 관행이 포함된 의료 텍스트에 대해 교육을 받은 경우 쓸모없거나 유해한 치료법을 추천할 수 있습니다. 또한 데이터에 다양성이 부족하면 AI가 제한된 훈련 범위를 벗어나는 맥락을 이해하지 못해 잘못된 출력이 발생할 수 있습니다.
2) 모델 아키텍쳐와 학습
LLM의 모델 아키텍처와 훈련 프로세스도 중요한 역할을 합니다. 여기서 과적합, 과소적합 개념이 등장하는데, 과적합은 LLM이 노이즈를 포함한 훈련 데이터를 너무 잘, 과하게 학습하여 새로운 데이터의 일반화 성능이 저하될 때 발생합니다. 반대로, 과소적합은 모델이 훈련 데이터를 적절하게 학습하지 못하고 덜 학습되어 응답이 지나치게 단순화될 때 발생합니다. 따라서 이러한 과적합, 과소적합 사이의 균형을 유지하는 것은 어렵지만 할루시네이션을 줄이는 데 필수적입니다.

그래서 이를 위해 파인튜닝시킬 때 여러 파라미터들을 조작하는 거겠죠.
## 학습 인자 설정
training_args = TrainingArguments(
output_dir="./results", ## 모델이 저장될 경로
learning_rate=5e-5, ## 초기 학습률 설정
lr_scheduler_type="cosine", ## 스케줄러 적용
warmup_steps=5000, ## Warmup 스텝
overwrite_output_dir=True, ## 경로 덮어쓰기
num_train_epochs=5, ## 학습할 epoch 수
per_device_train_batch_size=8, ## 배치 크기
gradient_accumulation_steps=1, ## 8 배치를 누적 후 그래디언트 업데이트
save_steps=1000, ## 저장 주기
save_total_limit=1, ## 저장할 모델 체크포인트 수
logging_dir="./logs", ## 로그 저장 디렉토리
logging_steps=200, ## 로그 기록 주기
logging_first_step=False, ## 첫 스텝 로깅 비활성화
optim="paged_adamw_32bit", ## QLoRA에 맞춘 32비트 AdamW 옵티마이저
max_grad_norm=10, ## 그래디언트 노름을 10으로 제한
evaluation_strategy="steps", ## 검증 설정 (훈련 중 일정 주기로 검증)
eval_steps=1000, ## 검증 주기 (매 500 스텝마다)
load_best_model_at_end=True, ## 가장 좋은 모델 저장
)
3) 자연어 텍스트의 모호함
인간의 언어는 본질적으로 복잡한 뉘앙스로 가득 차 있습니다. 단어와 문구는 문맥에 따라 다양한 의미를 가질 수 있습니다. 예를 들어, '은행'이라는 단어는 금융기관의 의미로도 쓰이고, 열매의 의미로도 쓰이죠. LLM은 이러한 용어를 명확하게 하기 위해 더 많은 맥락이 필요한 경우가 많으며, 이로 인해 오해와 환각이 발생합니다.
4) 알고리즘 자체적인 문제
현재 LLM 알고리즘에는 특히 장기적인 종속성을 처리하고 응답의 일관성을 유지하는 데 한계가 있습니다. 아마 확률론에 의거하여 모델을 구성하고 설계했기 때문이겠죠. 이러한 문제로 인해 LLM은 동일한 대화 내에서도 상충되거나 믿기 어려운 진술을 생성할 수 있습니다. 예를 들어, LLM이 한 가지 의견을 주장하다가 나중에 스스로 환각 현상이 발생해 그것이 아니라고 얘기하는 모순적인 상황이나 LLM이 하는 말이 실제로 성립하지 않는 말이거나, 윤리적으로 문제가 있는 말을 뱉는다거나 등이 있습니다.
4. 할루시네이션을 줄이고자 하는 최근 개발 및 연구
그래서 최근에는 이러한 할루시네이션을 줄이고자 하는 개발 단계나 연구 프로세스가 활발히 이루어지고 있습니다.
1) 검색 증강 생성 (RAG)

RAG는 LLM이 질문에 대한 답변을 출력하기 전에 데이터베이스를 참조할 수 있도록 하는 프로세스를 의미합니다. 사용자의 질문(Query)을 받고 사용자의 질문과 관련도가 높은 데이터셋을 찾아 이를 가져오는 방식이죠.
간단하게만 살펴보면, 파이프라인과 구성요소는 아래과 같습니다.
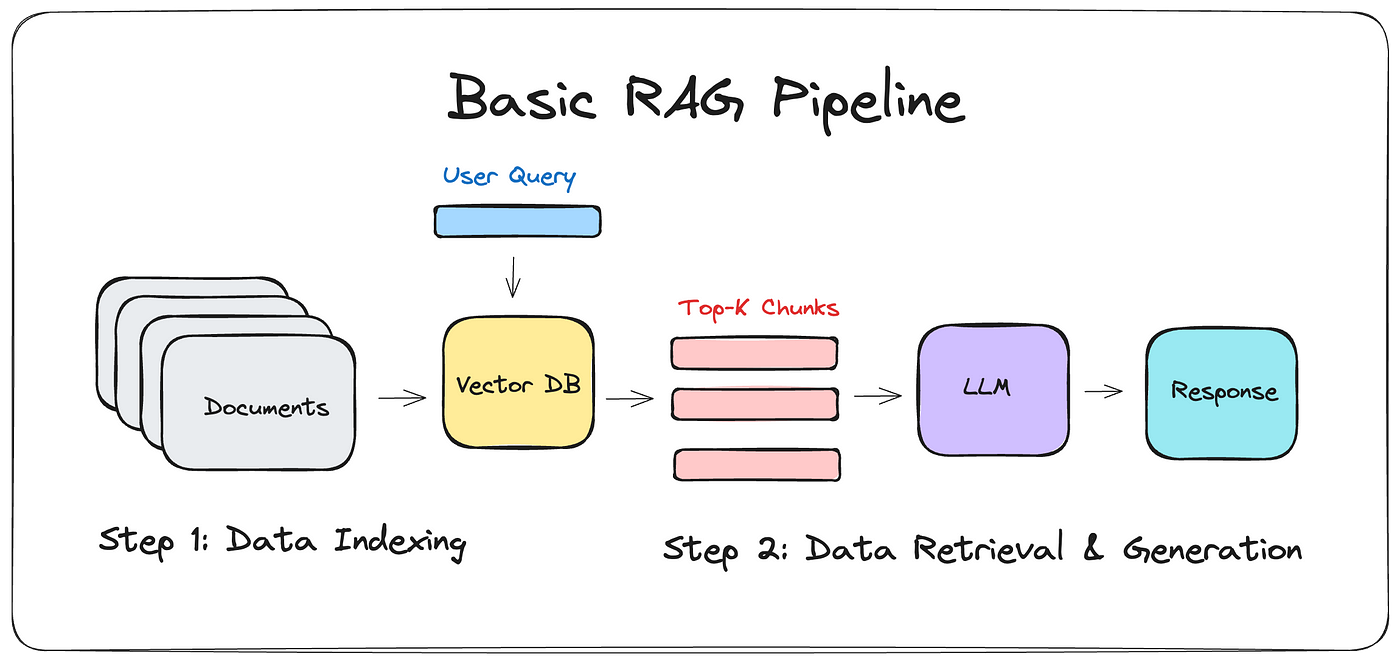
- Retriever (검색 모델) : 데이터베이스에서 정보를 검색하고 QA 쌍을 Reader Model에 전달
- Reader (읽기 모델) : Retriever가 전달한 정보, QA 등을 바탕으로 최종 답변 생성
2) 강화학습
강화학습이란, LLM이 생성한 내용을 인간이 검토하고 긍정/부정의 피드백을 주어 결과물을 더 좋게 만드는 과정입니다. 특히 의사결정에 관련된 할루시네이션을 줄이는데 매우 유용하다고 합니다. 저도 이번에 파인튜닝하면서 강화학습을 써보려고 했는데 구현이 좀 쉽지 않아서 애를 먹었던 기억이 있네요. 예시 코드는 아래와 같습니다.
## 사용자 피드백을 기반으로 강화학습
def get_user_feedback(response):
"""
사용자 피드백을 실시간으로 제공하는 함수.
이 함수에서 사용자는 응답을 보고 0~100 사이의 점수를 제공할 수 있음.
"""
print(f"모델의 답변: {response}")
while True:
try:
feedback = int(input("답변에 대한 점수를 0에서 100 사이의 정수로 입력하세요: "))
if 0 <= feedback <= 100:
return feedback
else:
print("0에서 100 사이의 정수를 입력하세요.")
except ValueError:
print("유효한 숫자를 입력하세요.")
## PPO 학습 및 사용자 피드백 적용 함수
def train_with_feedback(df, question_column):
for index, row in df.iterrows():
question = row[question_column]
## 모델이 답변 생성
response = generate_response(question)
## 사용자 피드백 받기
reward = get_user_feedback(response)
## 보상 기반으로 PPO 모델 업데이트
inputs = tokenizer(question, return_tensors="pt", padding=True).to(device)
query_tensors = inputs["input_ids"]
response_tensors = tokenizer(response, return_tensors="pt").to(device)["input_ids"]
rewards = torch.tensor([reward], dtype=torch.float).to(device)
## PPO 업데이트 - 리스트로 변환하여 전달
ppo_trainer.step([query_tensors], [response_tensors], [rewards])
## 업데이트된 응답을 DataFrame에 저장
df = generate_responses_for_dataframe(df, question_column)
return df
3) 구글의 SAFE & MIT의 LLM 저장 위치 연구
이외에도, 구글이 개발한 'SAFE' 시스템은 LLM이 생성한 답변의 정확성과 신뢰성을 평가하기 위해 사용됩니다. SAFE는 생성된 답변이 출처를 가지고 있는지, 그 출처가 실제로 해당 정보를 확인할 수 있는지를 검증하는데 집중합니다. 이는 답변의 '안정성'을 보장하는데 도움이 됩니다. SAFE는 생성된 답변이 주장하는 내용에 대해서 출처를 확인하고 그 출처 정보의 정확성과 출처의 신뢰성 등을 평가해 사용자가 잘못된 정보에 의존하지 않도록 사전에 방지하는 것을 목적으로 합니다.
MIT의 LLM 저장 위치 연구는 LLM이 어떻게 데이터를 저장하고 처리하는지 이해하기 위해 메모리와 연산 과정을 중심으로 분석합니다. 접근 방식은 LLM이 정보를 어떻게 저장하는지 파악해 모델이 정보를 어디에 저장하고 있는지를 찾아내는 것입니다. 이를 통해 할루시네이션이 왜 발생하는지를 이해하고 이를 바로잡을 수 있는 지표를 제공합니다.
2024.10.13 - [NLP] - [NLP] Korean LLM Leaderboard
[NLP] Korean LLM Leaderboard
오늘은 프로젝트 얘기는 아니고 인턴생활하면서 여러 Korean LLM을 다뤄봤는데 제가 Prompt를 잘 입력하지 못해서 그런걸까요.. 성능이 그다지 좋지 않은 걸 너무 많이 봐서 어떤 한국어 LLM이 좋은
dangingsu.tistory.com
이번 포스팅에서는 LLM의 할루시네이션이 발생하는 원인과 이를 해결하기 위한 노력들에 대해서 알아보았습니다. LLM을 연구하고 공부하고 있는 전공 개발자로서 아마 확률론적 LLM이 이어진다면 할루시네이션을 완전히 해결하기는 어려울 것으로 보이고, 확률에 의거하지 않는 새로운 개발 방법론이 등장한다면 그 때는 또 모르겠네요. 아무튼, 지금 현 상황에서는 할루시네이션을 최소화하는 게 가장 효율적이고 똑똑한 방법이라는 생각이 듭니다.
'NLP' 카테고리의 다른 글
| [NLP] Transformer의 함수 model.generate() 파라미터 (3) | 2024.11.25 |
|---|---|
| [NLP] LLM Prompt Engineering (5) | 2024.11.19 |
| [NLP] Korean LLM Leaderboard (3) | 2024.10.16 |
| [NLP] Survey of Chatbot, Persona (7) | 2024.09.04 |
| [NLP] NLP Task Review, 감정분석 (0) | 2024.07.11 |
| [NLP] Similarity, 문서 유사도 측정 (0) | 2024.07.06 |
| [NLP] Text Data Preprocessing (0) | 2024.07.02 |
| [NLP] 정규 표현식, Regular Expression (0) | 2024.07.01 |



