728x90
검색 엔진, 추천시스템 등 굉장히 다양한 분야의 데이터에서 문서 유사도 개념은 중요하다.
하지만 컴퓨터는 자연어, 즉 텍스트 데이터를 이해하지 못한다.
때문에 벡터 표현으로 변형된 데이터를 컴퓨터가 인식하게 되는데 이 때 우리는 이 벡터 표현을 가지고 유사도를 측정할 수 있다.
어떤 방법으로 어떻게 측정할 수 있는지 이제 한 번 알아보자.
Document Term Matrix (DTM)
다음 예시와 같이 문서 4개가 있을 때 각 단어가 몇 개 들어 있는지에 대한 행렬을 나타낼 수 있다.이를 DTM이라고 부른다.

| 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 | |
| 문서1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 문서2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 문서3 | 0 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
| 문서4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
그리고 이러한 행렬이 있을 때 우리는 유사도를 구할 수 있는데 이번 포스팅에서는 코사인 유사도, 자카드 유사도를 비롯한 여러 유사도 기법을 알아보도록 하겠다.
Cosine Similarity
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다.
식을 보면 두 벡터의 내적 / 곱으로 계산할 수 있다.
위의 DTM에 기반해 코사인 유사도를 구해보면 아래와 같다.
Jaccard Similarity
자카드 유사도는 두 집합의 합집합에서 교집합의 비율을 의미한다.
식을 보면 합집합 / 교집합으로 계산할 수 있다.
위의 DTM에 기반해 자카드 유사도를 구해보면 아래와 같다.
그 외 유사도 분석 방법
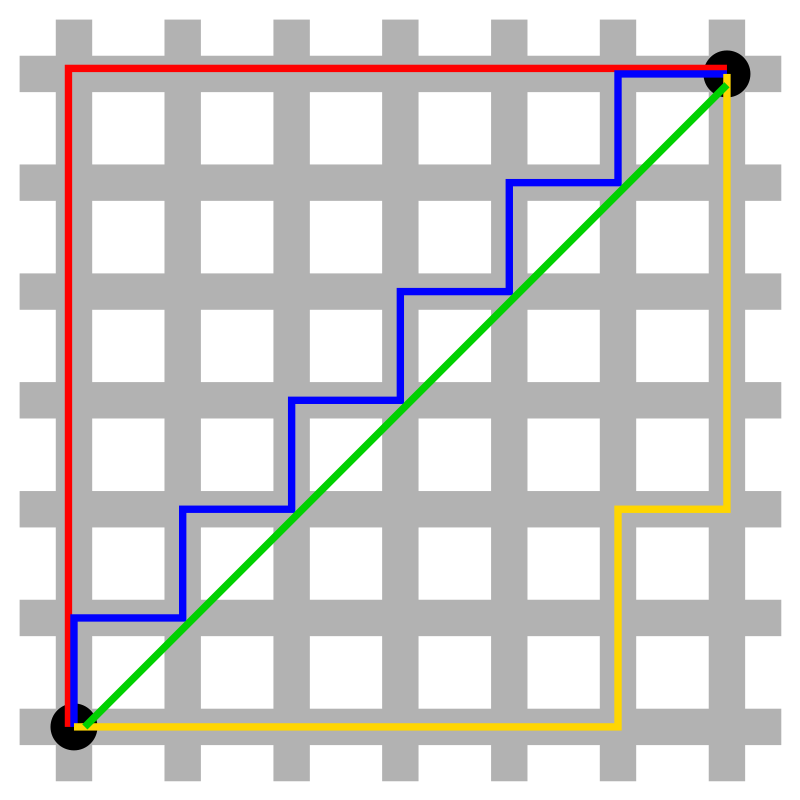
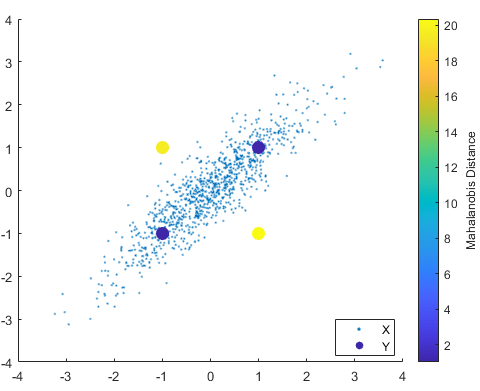
- 유클리디안 거리
- 피타고라스와 동일
- 맨하탄 거리
- 거리의 절댓값을 구하는 개념
- 마할라노비스 거리
- 가우시안 분포에 따른 거리 개념
[프로젝트] 국내 주요 게임사 텍스트 데이터 분석 프로젝트 리뷰 (1)
2024년 1학기 텍스트 데이터 분석 과목을 수강하면서 진행했던 프로젝트에 대해 리뷰해보려고 한다.해당 프로젝트는 데이터 분석 프로젝트이고 분야는 NLP, 데이터 분석이 되겠다.이번 포스팅에
dangingsu.tistory.com
728x90
반응형
'NLP' 카테고리의 다른 글
| [NLP] LLM Prompt Engineering (5) | 2024.11.19 |
|---|---|
| [NLP] Korean LLM Leaderboard (3) | 2024.10.16 |
| [NLP] Survey of Chatbot, Persona (7) | 2024.09.04 |
| [NLP] NLP Task Review, 감정분석 (0) | 2024.07.11 |
| [NLP] Text Data Preprocessing (0) | 2024.07.02 |
| [NLP] 정규 표현식, Regular Expression (0) | 2024.07.01 |
| [NLP] API를 활용한 Web Crawling (0) | 2024.06.29 |
| [NLP] Web Crawling, Selenium (0) | 2024.06.28 |



