728x90
API를 활용한 Web Crawling
- Application Programming Interface (API)
- 프로그램 간 데이터를 주고 받기 위한 방법
- 레스토랑에서 점원과 같은 역할을 수행
- 점원 : 손님에게 메뉴를 '요청'받고 이를 요리사에게 '요청' -> 요리사의 결과물을 전달
- API : 프로그램에게 데이터를 '요청'받고 이를 타 프로그램에 '요청' -> 데이터를 전달
- API가 가져야 할 내용
- 요청방식
- GET, POST 등
- 요청할 자료
- endpoint 등
- 자료요청에 필요한 추가 정보
- 검색 조건, api key 등
- 요청방식
Open API

- 개발자라면 누구나 무료로 사용 가능하도록 공개된 API
- Open API를 배포해 자사 서비스를 활용한 영역 확대
- 자사의 영향력을 높일 수 있음
(예시) API를 활용한 데이터 수집 - 공공데이터포털
- 로그인 -> 필요한 데이터 검색 -> 활용신청
## 부동산 거래 현황 통계 조회 서비스 데이터 크롤링
## 외국인 거래 건수 조회 테이블 활용
endpoint = 'https://api.odcloud.kr/api/RealEstateTradingSvc/v1/getRealEstateTradingCountForeigner'
service_key = 'lpZ9ekyXFMars3uiw8FnCe2qiPWq%2FJL7GRqAEGHn9pCbyDle%2FNt2tYQpOUCWhOcC3fIiH%2BBETkY2vu%2FpsC0oZw%3D%3D'
page = 1
perpage = 12
start_month = '202101'
end_month = '202112'
region = '11000'
trading_type='01'
cond1 = f'cond%5BRESEARCH_DATE%3A%3ALTE%5D={end_month}'
cond2 = f'cond%5BRESEARCH_DATE%3A%3AGTE%5D={start_month}&'
cond3 = f'cond%5BREGION_CD%3A%3AEQ%5D={region}'
cond4 = f'cond%5BDEAL_OBJ%3A%3AEQ%5D={trading_type}'
url = f'{endpoint}?page={page}&perPage={perpage}&{cond1}&{cond2}&{cond3}&{cond4}&serviceKey={service_key}'
html = urlopen(url)
bs_obj = BeautifulSoup(html, 'html.parser')
result = eval(bs_obj.text) # list 면 list 형태로 뽑아주고 dic 형태면 dic 형태로 뽑아주는 유용한 시키
result2 = result['data']
## 외국인 조회 건수 탐색
for item in result2:
print(item['RESEARCH_DATE'], ":", item['FOREIGNER_CNT'])
## pandas 패키지를 이용해 데이터프레임화
import pandas as pd
df = pd.DataFrame({
'research_date' : research_date,
'foreigner_cnt' : foreigner_cnt
})
df = df.sort_values('research_date').reset_index(drop = True)
df
네이버 API를 활용한 크롤링
- 네이버 로그인 -> 서비스 API 검색 -> API 신청
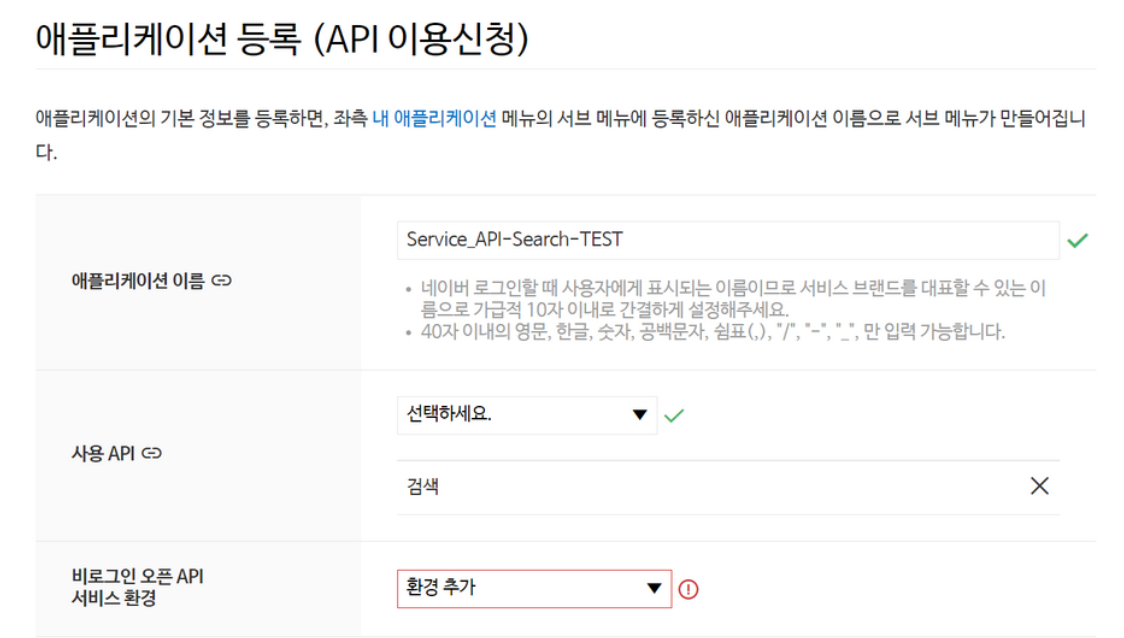
- 네이버 블로그를 예시로 검색해볼 예정

- 아래 코드는 게임사 5곳에 대해 검색어를 다양하게 해 크롤링 한 코드
import urllib.request
import urllib.parse
## API 인증 정보
client_id = ""
client_secret = ""
## 검색 기준 설정
n_display = 100 ## API 최대 요청 가능 수
news_list = [] ## 결과를 저장할 리스트
base_url = 'https://openapi.naver.com/v1/search/blog.json' ## 네이버 블로그 base url
queries_krafton = ['크래프톤', '크래프톤 게임', '크래프톤 주가', '크래프톤 채용', '크래프톤 복지']
queries_nexon = ['넥슨', '넥슨 게임즈', '넥슨 주가', '넥슨 채용', '넥슨 복지']
queries_netmable = ['넷마블', '넷마블 게임', '넷마블 주가', '넷마블 채용', '넷마블 복지']
queries_ncsoft = ['엔씨소프트', '엔씨소프트 게임', '엔씨소프트 주가', '엔씨소프트 채용', '엔씨소프트 복지']
queries_riot = ['라이엇게임즈', '라이엇코리아', '라이엇게임즈 주가', '라이엇게임즈 채용', '라이엇게임즈 복지']
## 각 검색어에 대해 처리
for query in queries_ncsoft:
start_index = 1
while start_index <= 1000: ## 최대 1000개 글 수집
encQuery = urllib.parse.quote(query)
url = f"{base_url}?query={encQuery}&display={n_display}&start={start_index}&sort=sim"
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
with urllib.request.urlopen(request) as response:
rescode = response.getcode()
if rescode == 200:
response_body = response.read()
search_results = eval(response_body.decode('utf-8'))
items = search_results['items']
## 네이버 뉴스만 추출 --> 'naver.com'를 포함하는 경우만
for item in items:
if 'naver.com' in item['link']:
news_list.append(item)
else:
print(f"Error Code: {rescode}")
start_index += n_display ## 다음 페이지 인덱스 증가
## 수집된 기사 수 출력
print(f"Collected {len(news_list)} articles that include 'naver.com' in the link.")
[프로젝트] 티스토리 블로그 Web Crawling
오늘은 NLP Task 프로젝트에서 도움될만한 글을 적어보겠습니다. 네이버 블로그, 지식iN, 뉴스 등은 API로 크롤링할 수 있습니다.자세한 내용은 아래 링크 활용해주시면 감사하겠습니다. 블로그 - S
dangingsu.tistory.com
728x90
반응형
'NLP' 카테고리의 다른 글
| [NLP] NLP Task Review, 감정분석 (0) | 2024.07.11 |
|---|---|
| [NLP] Similarity, 문서 유사도 측정 (0) | 2024.07.06 |
| [NLP] Text Data Preprocessing (0) | 2024.07.02 |
| [NLP] 정규 표현식, Regular Expression (0) | 2024.07.01 |
| [NLP] Web Crawling, Selenium (0) | 2024.06.28 |
| [NLP] Web Scraping, BeautifulSoup (0) | 2024.06.27 |
| [NLP] 자연어처리 토큰화작업 2, 하위 단어 토큰화 (0) | 2024.03.13 |
| [NLP] 자연어처리 토큰화작업(KoNLPy, NLTK, SpaCy) (2) | 2024.03.07 |



