자, 오늘은 X:AI Seminar 2024에서 진행한 S2S 논문 리뷰를 가져왔습니다.

해당 논문은 2014년에 발표되어 Attention, Transformer 등의 모델이 등장하기 이전의 논문이라는 배경 정도 짚고 가겠습니다.
논문 : Sequence to Sequence Learning with Neural Networks
저자 : Ilya Sutskever, Oriol Vinyals, Quoc V. Le ICLR 2014 출판
[1] DNN 기반 모델의 한계

전통적인 DNN 기반의 언어 모델에서는 번역이 다음과 같은 사진처럼 이루어집니다. 입력과 출력 차원의 크기가 같다고 가정하고 현재 예시에서는 그 차원이 T가 되겠죠. 원리를 좀 더 살펴보면 x1이라는 단어가 입력되고 h0의 첫 번째 hidden vector와 결합 후 시그모이드 함수를 거쳐 그 다음 hidden vector인 h1을 만듭니다. h1이 만들어지면 FC Layer를 거쳐 y1이라는 첫 번째 단어가 번역이 되는, 이러한 계산 원리로 동작합니다.
하지만 이렇게 된다면 시퀀스가 고정되어 있지 않은 문제에서는 사용하기가 힘들다는 단점이 있습니다. 예시로는 기계 번역, 음성 인식 등이 있겠구요. 자 그래서 입력과 출력의 차원이 다른 경우를 커버하기 위해서 한 가지 아이디어를 생각해냅니다.
[2] Context Vector

바로 인코더와 디코더 사이에 고정된 크기의 Context Vector를 생성하는 겁니다. 이렇게 한다면 입력과 출력의 차원이 같지 않아도 중간에 고정된 크기의 벡터를 생성하기 때문에 차원이 같아야만 하는 단점을 해결할 수 있었습니다. 당시에는 획기적인 아이디어였죠. 참고로, 인코더의 마지막 Hidden Vector가 Context Vector가 된다고 합니다.
하지만 문제는 끝나지 않았습니다. 여전히 인코더와 디코더에 RNN 기반의 모델을 사용했기 때문에 장기의존성 문제가 있습니다.
- 장기의존성 문제란?
- 입력 시퀀스가 길어지면 처음에 나온 단어는 수많은 Hidden State와 Sigmoid 함수를 거치면서 원래 그 단어만의 특징을 잃어버리게 됩니다. 즉, 의미가 흐릿해지는 현상이 발생합니다. 이를 장기의존성 문제라고 부릅니다. ><
[3] LSTM의 사용
이 장기의존성 문제를 해결하기 위해 본 논문에서는 LSTM을 층층이 쌓아서 S2S 모델을 구현했다고 합니다. LSTM이 어떻길래 장기의존성 문제를 해결할 수 있었는지 알아보겠습니다.

사진에서 알 수 있듯이 RNN은 시퀀스가 길어지면 수많은 Hidden State를 지나며 장기의존성 문제가 발생하는데, LSTM은 C cell을 이용해서 해결했다고 얘기할 수 있습니다. 간단히 얘기해서 입력 시퀀스의 오래된 기억은 즉, 시퀀스의 초반 단어들은 C state를 통해 정보가 보존되고 시퀀스의 후반 단어들은 H state를 통해 정보가 보존되어 시퀀스가 길어짐에 따라 정보가 손실되는 걸 막을 수 있는 것이었습니다. 정말 엄청나죠? 그리고 추가적으로 이 LSTM을 층층이 쌓았다고 위에서 언급했는데 본 논문에서는 4개의 LSTM을 쌓아서 사용했다고 합니다.
[4] 입력 시퀀스의 순서 변경
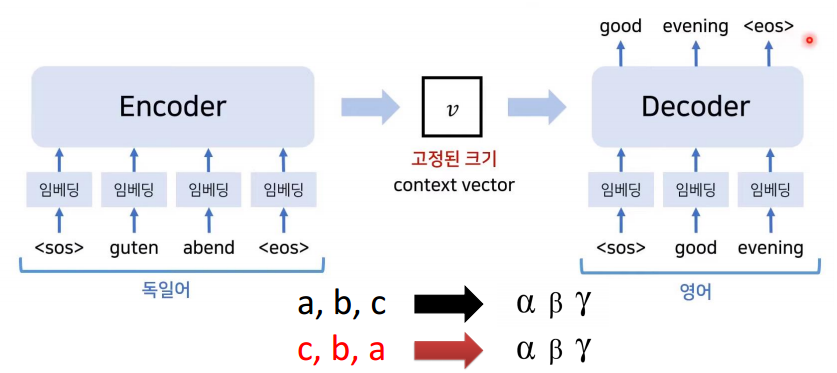
추가적으로 본 논문에서는 입력 시퀀스, 즉 단어들의 순서를 뒤바꿨는데 성능 향상을 기록했다고 합니다. 위 사진은 이해가 쉬울 수 있도록 a, b, c 를 알파, 베타, 감마로 번역하는 과정을 나타낸 예시입니다. 가장 처음 번역해야 하는 알파에 대해 가장 마지막에 제공하면서 모델로 하여금 Mapping 될 수 있도록 해서 학습 난이도를 낮춰주는 것이 성능 향상에 유의미했다는 얘기인데요. 사실 이 부분은 이렇게 했더니 성능이 올랐다 ! 하고 결과론적인 얘기라서 그냥 그렇구나 하고 이해해주시면 감사하겠습니다.

논문에서 이렇게 언급한 것처럼 입력 문장의 순서를 뒤바꿨더니 혼란함을 주는 지표(perplexity)는 5.8 -> 4.7로 줄었고 BLEU score는 25.9 -> 30.6 으로 올랐다는 얘기를 하고 있습니다. 그리고 당연히 입력 문장의 순서를 바꾼다면 원래 입력 시퀀스의 마지막 부분 (위 사진에서 c의 경우가 되겠죠)에 대해서는 모델이 예측하기가 힘들텐데 그럼에도 불구하고 입력 문장의 순서를 바꾼 전략이 유효했다고 본 논문에서 추가적으로 언급하고 있습니다.
[4-1] BLEU score
"BLEU score가 30.6으로 올랐다" 등 BLEU score에 대해서 언급하고 있는데 BLEU score는 기계 번역 분야에서 모델의 성능을 판단하기 위한 평가 지표 중 하나입니다.

기계 번역 분야에서 모델이 생성한 문장을 평가하는 방식에는 크게 2가지가 있습니다. ROUGE, BLEU score가 있는데요. 각각에 대한 공식은 위 사진을 참고하면 됩니다.
쉽게 설명하자면 아래 예시에서 모델이 생성한 문장(Gen)과 인간이 생성한 문장(Ref)가 있습니다. ROUGE score는 인간의 문장이 분모로 들어가 5개의 단어 중 3개의 단어를 맞췄으니 3/5가 되고, BLEU score는 반대로 모델의 문장이 분모로 들어가 6개의 단어 중 3개의 단어를 맞췄으니 3/6이 되는 원리인데, 이 부분도 그냥 그렇구나 하고 봐주시면 감사하겠습니다.
[5] Experiment
본 논문의 실험 과정에 대한 세부적인 내용입니다.

- LSTM 모델을 4번 중첩해서 학습을 진행, LSTM의 파라미터는 [-0.08, 0.08]의 균등 분포로 초기화
- SGD loss function을 사용, learning_rate는 0.7에서 시작해 5 epochs 마다 절반가량으로 줄여줌
- batch_size는 128을 사용
- 학습을 빠르게 하기 위해 source sentence 간 길이를 맞춰주어, 학습 속도를 2배 정도 빠르게 함
- 긴 문장과 짧은 문장이 함께 입력되면 mini batch를 만드는데 낭비가 되기 때문에, padding을 최소화 하기 위해 시행
[5-1] Score 변화

위의 표에서는 Beam Search 방식(다음에 나올 단어를 예측하는 원리 중 하나인데 누적확률분포를 활용한다는 특징이 있음, k = 12)을 채택하고 입력 문장의 순서를 뒤바꾼 LSTM 만을 이용한 5개의 모델을 앙상블했더니 34.81로 점수가 상당히 높았다는 얘기를 하고 있습니다.
아, 추가적으로 본 실험에서는 WMT 14 Data를 사용해 영어를 불어로 변환하는 task를 진행했다고 합니다. WMT 14 Data는 당시 NLP 분야에서 데이터 수도 크고 상당히 유명한 데이터셋이라고 합니다. 그래서 2014년 당시에 이 데이터셋을 가지고 번역 task를 실행한 가장 높았던 BLEU score가 37점이었는데 기존 통계학적 방식과 이 LSTM 방식을 함께 사용해 예측했더니 36.5점으로 성능이 매우 높았다는 점을 언급하고 있고, 이는 발전되어 LSTM 기반의 딥러닝 모델을 이용한 번역 task의 가능성을 시사했다고 할 수 있습니다.
[6] Conclusion
중구난방식으로 얘기한 것 같아서.. ㅎㅎ 마지막으로 논문 내용 정리를 하겠습니다.
- 기존의 DNN, RNN 방식을 활용한다면 입력, 출력 차원이 같아야만 한다는 단점이 있었는데 Context Vector를 생성하면서 이 문제를 해결했습니다
- 하지만 Context Vector를 생성하는 것만으로는 장기의존성 문제를 해결할 수 없었기 때문에 오래된 단어도 잘 기억하고 정보를 잘 보존할 수 있도록 LSTM 모델을 층층이 쌓아서 활용했다고 합니다
- LSTM 방식과 기존의 통계학적 방식을 함께 사용했더니 성능이 매우 향상되어 딥러닝 모델 기반의 Seq-to-Seq 가능성을 보였습니다
- 특히 학습 과정에서 입력 시퀀스의 단어 순서를 뒤바꾸는 전략이 유효했다고 합니다
본 포스팅은 동빈나님 유튜브를 많이 참고하였습니다. 감사합니다.
[논문리뷰] Transformer 논문 리뷰
오늘은 Transformer 논문 리뷰를 가져왔습니다. 해당 논문은 2017년에 발표된 논문입니다. Attention Is All You Need저자 : Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Il
dangingsu.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] ALBEF 논문 리뷰 (2) | 2024.07.17 |
|---|---|
| [논문리뷰] T5 논문 리뷰 (0) | 2024.07.15 |
| [논문리뷰] CLIP 논문 리뷰 (0) | 2024.07.10 |
| [논문리뷰] XL-Net 논문 리뷰 (0) | 2024.07.03 |
| [논문리뷰] Transformer 논문 리뷰 (0) | 2024.06.26 |
| [논문리뷰] MT-DNN 논문 리뷰 (0) | 2024.05.23 |
| [논문리뷰] BART 논문 리뷰 (2) | 2024.05.15 |
| [논문리뷰] BERT 논문 리뷰 (0) | 2024.04.30 |



