
자연어 및 자연어 처리
자연어(National Language)는 자연 언어라고도 부르며, 인공적으로 만들어진 프로그래밍 언어와 다르게 사람들이 쓰는 언어 활동을 위해 자연히 만들어진 언어를 의미합니다. 자연어 처리(Natural Language Processing, NLP)는 컴퓨터가 인간의 언어를 이해하고 해석 및 생성하기 위한 기술을 의미합니다.
자연어 처리는 인공지능의 하위 분야로 컴퓨터가 인간과 유사한 방식으로 인간의 언어를 이해하고 처리하는 것이 주요 목표 중 하나입니다. 인간 언어의 구조, 의미, 맥락을 분석하고 이해할 수 있는 알고리즘과 모델을 개발합니다. 이러한 모델을 개발하기 위해서는 다음과 같은 문제가 해결되어야 하는데
- 모호성(Ambiguity) : 인간의 언어는 단어와 구가 사용되는 맥락에 따라 여러 의미를 갖게 되어 모호한 경우가 많아 알고리즘은 이러한 다양한 의미를 이해하고 명확하게 구분할 수 있어야 합니다.
- 가변성(Variability) : 인간의 언어는 다양한 사투리(Dialects), 강세(Accent), 신조어(Coined word), 작문 스타일로 인해 매우 가변적이기에 알고리즘은 이러한 가변성을 처리할 수 있어야 하며 사용 중인 언어를 이해할 수 있어야 합니다.
- 구조(Structure) : 인간의 언어는 문장이나 구의 의미를 이해할 때 구문(Syntactic)을 파악해 의미(Semantic)를 해석합니다. 알고리즘은 문장의 구조와 문법적 요소를 이해해 의미를 추론하거나 분석할 수 있어야 합니다.
위와 같은 문제를 이해하고 구분할 수 있는 모델을 만들기 위해서는 말뭉치(Corpus)를 일정한 단위인 토큰(Token)으로 나누어야 합니다.
말뭉치는 뉴스 기사, 사용자 리뷰 등 목적에 따라 구축되는 텍스트 데이터를 의미합니다. 토큰은 개별 단어나 문장 부호와 같은 텍스트를 의미하며 말뭉치보다 더 작은 단위입니다. 텍스트 데이터를 토큰으로 나누는 과정을 토큰화(Tokenization)라고 합니다. 그리고 이러한 토큰화를 위해 토크나이저(Tokenizer)를 사용합니다. 토크나이저를 사용해 문장을 토큰화한다면 다음과 같이 표현할 수 있습니다.
- 입력 : '형태소 분석기를 이용해 간단하게 토큰화할 수 있다.'
- 출력 : ['형태소', '분석기', '를', '이용', '하', '어', '간단', '하', '게', '토큰', '화', '하', 'ㄹ', '수', '있', '다', '.']
단어 및 문장 토큰화
토큰화는 자연어 처리에서 매우 중요한 전처리 과정으로, 텍스트 데이터를 구조적으로 분해하여 개별 토큰으로 나누는 작업을 의미합니다. 토큰화 과정은 정확한 분석을 위해 필수이며, 단어나 문장의 빈도 수, 출현 패턴 등을 파악할 수 있습니다. 입력된 텍스트 데이터를 단어 / 글자 단위로 나누는 기법으로는 단어 토큰화와 글자 토큰화가 있고 이러한 기법을 통해 각각의 토큰은 의미를 갖는 최소 단위로 분해됩니다.
단어 토큰화
단어 토큰화(Word Tokenization)는 자연어 처리 분야에서 핵심적인 전처리 작업 중 하나로 텍스트 데이터를 의미 있는 단어로 분리하는 작업입니다. 우리는 이미 띄어쓰기나 문장 부호를 활용해서 문장을 이해하고 있습니다. 모든 언어가 띄어쓰기나 문장 부호를 활용하는 것은 아니지만 대부분의 언어는 띄어쓰기를 이용해 문장을 의미 있는 단어로 나눠 표현합니다. 아래 예시는 split 메소드를 이용해 띄어쓰기를 기준으로 쉽게 토큰화 한 예시입니다.
review = "현실과 구분 불가능한 cg. 시각적 즐거움은 최고! 더불어 ost는 더더욱 최고!!"
tokenized = review.split()
print(tokenized)
글자 토큰화
글자 토큰화(Character Tokenization)는 띄어쓰기뿐만 아니라 글자 단위로 문장을 나누는 방식으로 비교적 작은 단어 사전을 구축할 수 있다는 장점이 있습니다. 글자 토큰화는 언어 모델링과 같은 시퀀스 예측 작업에서 활용됩니다. 예를 들어 다음 문자를 예측하는 언어 모델링에서 글자 토큰화는 유용한 방식입니다. 아래 예시는 LIST 형태로 변환해 쉽게 글자 토큰화 한 예시입니다.
review = "현실과 구분 불가능한 cg. 시각적 즐거움은 최고! 더불어 ost는 더더욱 최고!!"
tokenized = list(review)
print(tokenized)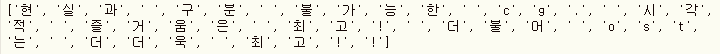
자모 / 자소 단위 변환
영어의 경우 글자 토큰화를 진행하면 각 알파벳으로 나뉩니다. 하지만 한글의 경우 하나의 글자는 여러 자음과 모음의 조합으로 이루어져 있기 때문에 자소 단위로 나눠서 자소 단위 토큰화를 수행합니다. '자모(jamo)' 라이브러리를 사용해서 한글 문자 및 자모 작업, 한글 음절 분해 작업을 수행할 수 있습니다.
from jamo import h2j, j2hcj
review = "현실과 구분 불가능한 cg. 시각적 즐거움은 최고! 더불어 ost는 더더욱 최고!!"
decomposed = j2hcj(h2j(review))
tokenized = list(decomposed)
point(tokenized)
형태소 토큰화
형태소 토큰화(Morpheme Tokenization)란 텍스트를 형태소 단위로 나누는 토큰화 방법으로 언어의 문법과 구조를 고려해 단어를 분리하고 이를 의미 있는 단위로 분류하는 작업입니다. 형태소 토큰화는 특히 한국어와 같이 교착어(Agglutinative Language)인 언어에서 중요하게 수행됩니다. 한국어는 대부분의 언어와 달리 각 단어가 띄어쓰기로 구분되지 않고 어근에 다양한 접사와 조사가 조합되어 하나의 낱말을 이루므로 각 형태소를 적절히 구분해 처리해야 합니다.
예를 들어 '그는 나에게 인사를 했다'라는 문장을 보면 '그는'은 '그'라는 단어와 '는'이라는 조사가 결합해 하나의 단어로 이루어져 있고, '나'라는 단어와 '에게'라는 조사가 결합해 하나의 단어로 이루어져 있습니다. 이처럼 실제로 의미를 가지고 있는 최소의 단위를 형태소(Morpheme)라고 하고 형태소는 크게 스스로 의미를 가지고 있는 자립 형태소(Free Morpheme)와 스스로 의미를 갖지 못하고 다른 형태소와 조합되어 사용되는 의존 형태소(Bound Morpheme)로 구분됩니다.
자립 형태소는 단어의 기본이 되는 형태소로서 명사, 동사, 형용사와 같은 단어를 이루는 기본 단위인 반면, 의존 형태소는 자립 형태소와 함께 조합되어 문장에서 특정한 역할을 수행하며 조사, 어미, 접두사, 접미사 등이 이에 해당합니다.
형태소 어휘 사전
형태소 어휘 사전(Morpheme Vocabulary)은 자연어 처리에서 사용되는 단어의 집합인 어휘 사전 중에서도 각 단어의 형태소 정보를 포함하는 사전을 말합니다. 단어가 어떤 형태소들의 조합으로 이루어져 있는지에 대한 정보를 담고 있어, 형태소 분석 작업에서 매우 중요한 역할을 합니다.
예를 들어
"그는 나에게 인사를 했다"
"나는 그에게 인사를 했다"
라는 문장이 있다고 가정하고 띄어쓰기로 토큰화를 수행한다면 어휘 사전은 ['그는', '나에게', '인사를', '했다', '나는', '그에게']로 구성됩니다.
만약 말뭉치에 "그녀는 그에게 인사를 했다"라는 문장이 추가되면 '그는', '나는', '그녀는'을 같은 의미 단위로 인식하지 못하고 학습을 진행하는데 형태소 단위로 어휘 사전을 구축한다면 '그', '나'와 같은 정보에서 '그녀'의 토큰 정보만 새로이 학습해 '그녀는'이나 '그녀에게'같은 어휘를 쉽게 학습할 수 있습니다.
텍스트 데이터를 형태소 분석하여 각 형태소에 해당하는 품사(Part Of Speech, POS)를 태깅하는 작업을 품사 태깅(POS Tagging)이라고 합니다. 이를 통해 자연어 처리 분야에서 문맥을 고려할 수 있어 더욱 정확한 분석이 가능해집니다. 이에 대한 실습을 KoNLPy, NLTK, SpaCy로 진행해보겠습니다.
KoNLPy
KoNLPy는 한국어 자연어 처리를 위해 개발된 라이브러리로 명사 추출, 형태소 분석, 품사 태깅 등의 기능을 제공합니다. 텍스트 데이터를 전처리하고 분석하기 위한 다양한 도구와 함수를 제공해 텍스트 마이닝, 감성분석, 토픽 모델링 등 다양한 NLP 작업에서 사용됩니다.
KoNLPy는 Okt(Open Korean Text), 꼬꼬마(Kkma), 코모란(Komoran), 한나눔(Hannanum), 메캅(Mecab) 등의 다양한 형태소 분석기를 지원합니다.
- KoNLPy 라이브러리 설치
pip install konlpy
- Okt 토큰화
- Okt 객체는 문장을 입력받아 명사, 구, 형태소, 품사 등의 정보를 추출하는 여러 가지 메소드를 제공
- 명사추출(nouns), 구문추출(phrases), 형태소추출(morphs), 품사태깅(pos)
from konlpy.tag import Okt
okt = Okt()
sentence = "무엇이든 상상할 수 있는 사람은 무엇이든 만들어 낼 수 있다."
nouns = okt.nouns(sentence)
phrases = okt.phrases(sentence)
morphs = okt.morphs(sentence)
pos = okt.pos(sentence)
print("명사 추출 :", nouns)
print("구 추출 :", phrases)
print("형태소 추출 :", morphs)
print("품사 태깅 :", pos)
- Kkma 토큰화
- Kkma 클래스를 통해 명사, 문장, 형태소, 품사를 추출가능
- 구문 추출 기능은 지원하지 않지만 명사추출(kkma.sentences) 기능을 제공
from konlpy.tag import Kkma
kkma = Kkma()
sentence = "무엇이든 상상할 수 있는 사람은 무엇이든 만들어 낼 수 있다."
nouns = kkma.nouns(sentence)
phrases = kkma.sentences(sentence)
morphs = kkma.morphs(sentence)
pos = kkma.pos(sentence)
print("명사 추출 :", nouns)
print("구 추출 :", phrases)
print("형태소 추출 :", morphs)
print("품사 태깅 :", pos)
NLTK
NLTK(Natural Language Toolkit)는 자연어 처리를 위해 개발된 라이브러리로, 토큰화, 형태소 분석, 구문 분석, 개체명 인식, 감성 분석 등과 같은 기능을 제공합니다. NLTK는 주로 영어 자연어 처리를 위해 개발되었지만 네덜란드어, 프랑스어, 독일어 등과 같은 다양한 언어의 자연어 처리를 위한 데이터와 모델을 제공합니다.
- NLTK 라이브러리 설치
pip install nltk
- NLTK 영문 토큰화 및 품사 태깅
- 영문 토큰화는 punkt 모델을 기반으로 단어나 문장을 토큰화
- 단어 토크나이저(word_tokenize)는 문장을 입력받아 공백 기준으로 단어 분리, 각 단어를 추출해서 리스트로 반환
- 문장 토크나이저(sent_tokenize)는 문장을 입력받아 구두점을 기준으로 문장을 분리해 리스트로 반환
- 품사 태깅(pos_tag) 메소드는 토큰화된 문장에서 품사 태깅 수행
import nltk
from nltk import tag
from nltk import tokenize
nltk.download('punkt') # punkt 모델 다운로드
nltk.download('averaged_perception_tagger') # averaged 모델 다운로드
nltk.download('averaged_perceptron_tagger') # averaged 모델 다운로드
sentence = "Those who can imagine anything, can create the impossible."
word_tokens = tokenize.word_tokenize(sentence) # 단어 토큰화 진행
sent_tokens = tokenize.sent_tokenize(sentence) # 문장 토큰화 진행
pos = tag.pos_tag(word_tokens) # 품사 태깅
print(word_tokens)
print(sent_tokens)
print(pos)
spaCy
spaCy는 씨이썬(Cython) 기반으로 개발된 오픈 소스 라이브러리로서, NLTK 라이브러리와 마찬가지로 자연어 처리를 위한 기능을 제공합니다. NLTK 라이브러리와의 주요한 차이점은 빠른 속도와 높은 정확도를 목표로 하는 머신러닝 기반의 자연어 처리 라이브러리라는 점입니다.
NLTK는 학습 목적으로 자연어 처리에 대한 다양한 알고리즘과 예제를 제공하는 반면, spaCy는 효율적인 처리 속도와 높은 정확도를 제공하는 것을 목표로 합니다.
- spaCy 품사 태깅
- spaCy는 사전 학습된 모델을 기반으로 처리하기 때문에 spaCy 모델 불러오기 함수(load)를 통해 모델 설정 가능
- spaCy는 객체 지향적(Object Oriented)으로 구현돼 처리한 결과를 doc 객체에 저장
- token 객체에는 기본 품사속성(pos_), 세분화 품사속성(tag_), 원본 텍스트 데이터(text), 토큰 사이의 공백을 포함하는 텍스트 데이터(text_with_ws), 벡터(vector), 벡터 노름(vector_norm) 등의 속성이 포함되어 있음
import spacy
nlp = spacy.load('en_core_web_sm')
sentence = "Those who can imagine anything, can create the impossible."
doc = nlp(sentence)
for token in doc:
print(f"[{token.pos_:5} - {token.tag_:3} : {token.text}]")
형태소 분석과 품사 태깅은 주요 키워드를 추출하거나 문장의 긍정 / 부정 여부를 판단하는 언어 모델의 성능을 높이는 데도 중요한 역할을 합니다. 이는 자연어 처리 분야에서 핵심적인 기술로 자리 잡고 있으며, 이를 활용해 다양한 자연어 처리 응용 프로그램을 개발할 수 있습니다.
본문 내용의 대부분은 <파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습> 교재에 기반한 내용입니다.
[NLP] 자연어처리 토큰화작업 2, 하위 단어 토큰화
하위 단어 토큰화자연어 처리에서 형태소 분석은 중요한 전처리 과정 중 하나입니다. 컴퓨터가 자연어를 인간이 이해하는 방식과 비슷하게 처리할 수 있도록 하기 위해서는 형태소 단위의 토큰
dangingsu.tistory.com
[NLP] Similarity, 문서 유사도 측정
검색 엔진, 추천시스템 등 굉장히 다양한 분야의 데이터에서 문서 유사도 개념은 중요하다.하지만 컴퓨터는 자연어, 즉 텍스트 데이터를 이해하지 못한다.때문에 벡터 표현으로 변형된 데이터
dangingsu.tistory.com
'NLP' 카테고리의 다른 글
| [NLP] Similarity, 문서 유사도 측정 (0) | 2024.07.06 |
|---|---|
| [NLP] Text Data Preprocessing (0) | 2024.07.02 |
| [NLP] 정규 표현식, Regular Expression (0) | 2024.07.01 |
| [NLP] API를 활용한 Web Crawling (0) | 2024.06.29 |
| [NLP] Web Crawling, Selenium (0) | 2024.06.28 |
| [NLP] Web Scraping, BeautifulSoup (0) | 2024.06.27 |
| [NLP] 자연어처리 토큰화작업 2, 하위 단어 토큰화 (0) | 2024.03.13 |
| [NLP] 파이토치(Pytorch)를 이용한 텍스트 데이터 증강 (0) | 2024.02.29 |



