RAG 논문 리뷰입니다.

논문 : Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
저자 : Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela
[1] Introduction
GPT와 같은 대형 언어모델, 즉 LLM은 사전학습된 내용을 통해 여러 NLP Downstream Task에서 좋은 성능을 보이고 있습니다.
하지만 정말 정확한 지식이 필요한 분야(법률, 의료 등)에서는 아직 정확하게 답변하는 능력은 제한적이고, 모델의 판단 근거를 투명하게 제공하거나 새로운 정보를 업데이트하는 것은 어려운 일입니다. 또한, 때때로 할루시네이션 문제가 발생하기도 하구요.
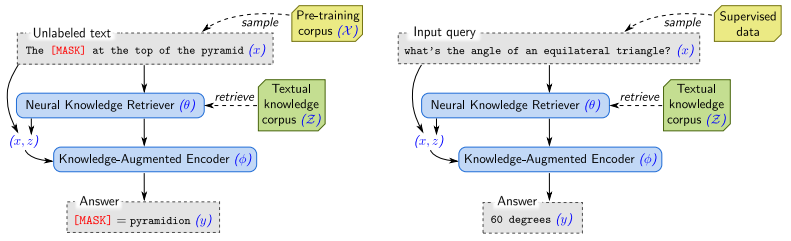
이전까지는 위키피디아와 같은 외부 메모리에서 직접 정보를 뽑는 것은 '정답 추출'과 같은 Task에서만 써왔습니다.
예를 들어, REALM과 QAQA의 경우가 이렇습니다.
그러나, 본 논문에서는 사전학습된 언어모델 + 외부 지식 데이터베이스 + 정보를 검색하는 Retrieval 을 결합하여 새로운 모델 구조인 RAG를 제안하고 기존에는 QA에서만 썼던 검색 방식을 Seq2Seq 구조로 확장하여 적용하였습니다.
이러한 방식은 답 하나를 생성할 때 전체 문장을 같은 문서 출력을 참고하여 만들 수도 있고, 매 번 다른 문서를 참조하여 만들 수도 있어서 유연하다는 장점이 있고, T5나 BART처럼 어떤 Seq2Seq 작업에도 파인튜닝이 가능합니다.
[2] Methods

RAG는 기본적으로 다음 두 구성 요소를 결합하여 동작합니다.
- Retreiver (검색기)
- 주어진 입력 문장 $x$에 대해 관련된 문서 $z$를 검색
- 이 검색기는 확률 분포 형태로 상위 K개의 문서를 반환하며 이 과정은 $p_ η(z|x)$로 표현됨
- Generator (생성기)
- 검색된 문서 $z$, 입력 $x$, 그리고 이전까지 생성된 토큰 시퀀스 $y_{1:i-1}$을 바탕으로 다음 토큰 $y_i$를 생성
- 이 확률 분포는 $p_ θ(y_i | x, z, y_{1:i-1})$로 정의됨
이 두 구성 요소는 함께 동작하여, 단순히 모델 내부 파라미터만을 사용하는 것이 아니라 외부 문서를 참조하며 답변을 생성할 수 있도록 합니다. 이를 통해 모델은 더욱 구체적이고 사실 기반의 응답을 생성할 수 있게 됩니다.
잠재 문서($z$)를 활용한 확률 계산 방식
RAG는 검색된 문서 $z$를 잠재 변수 (latent variable)로 간주하고, 이들에 대해 주변화 (marginalization) 하는 방식으로 학습과 예측을 수행합니다. 여기에는 두 가지 접근 방식이 존재합니다.
1) RAG-Sequence Model
- RAG-Sequence는 전체 생성 시퀀스가 하나의 검색 문서에 기반하여 생성된다고 가정
- 즉, 생성하는 모든 단어는 같은 문서 $z$를 참조
- 계산 효율이 좋고, 특정 문서를 중심으로 응답을 구성하는데 적합
- 단계별 과정:
- 입력 $x$에 대해 상위 K개의 문서를 검색
- 각 문서 $z$에 대해 전체 시퀀스 $y$의 생성 확률을 계산
- 각 문서에 대한 결과를 확률적으로 가중 평균해 최종 확률 도출

2) RAG-Token Model
- RAG-Token은 각 토큰을 생성할 때마다 서로 다른 문서를 참조할 수 있도록 허용
- 즉, 하나의 답변 안에서 여러 문서를 혼합하여 사용가능
- RAG-Sequence에 비해 더 유연하며, 복잡하거나 다양한 정보 출처가 필요한 응답을 생성하는데 유리
- 단계별 과정:
- 입력 $x$에 대해 상위 K개의 문서를 검색
- 각 토큰 $y_i$를 생성할 때, 문서들에 대해 개별적으로 생성 확률을 계산하고, 이를 합산하여 토큰의 최종 확률 도출
- 이 과정을 시퀀스 전체에 반복

Retriever : DPR 기반 검색기
RAG의 문서 검색기는 DPR (Dense Passage Retrieval) 구조를 기반으로 합니다.
DPR은 bi-encoder 구조를 따르며, 쿼리와 문서를 각각 별도의 BERT 모델로 인코딩합니다.
- 문서 인코더 : BERT로 문서 $z$를 임베딩하여 벡터 $d(z)$를 생성 (<sub> d </sub>)
- 쿼리 인코더 : BERT로 입력 $x$를 벡터 $q(x)$로 인코딩 (<sub> q </sub>)
- 문서 선택 : 문서와 쿼리 간 내적 $d(z)^T * q(x)$을 최대화하는 K개의 문서를 검색 (MIPS)
RAG는 미리 학습된 DPR bi-encoder를 사용하여 Retriever를 초기화하고, 이를 기반으로 전체 문서 인덱스를 구성합니다.
이 때 이 인덱스는 모델이 참조하는 비파라메트릭 메모리에 해당합니다.
## 이 DPR 리트리버는 TriviaQA, Natural Questions 데이터셋의 정답 문서를 잘 찾아낼 수 있도록 학습되어 있습니다. ##
Generator : BART 기반 생성기
RAG의 생성기는 BART-Large 모델을 기반으로 하며, 총 약 4억 개의 파라미터를 가지고 있습니다.
BART는 encoder-decoder 구조의 transformer 모델로, 사전학습 과정에서 다양한 noising 기법과 denoising objective를 사용하여 강인한 언어 표현력을 갖춘 모델입니다.
- 입력 방식 : 검색된 문서 $z$와 원래 입력 $x$를 단순히 연결하여 BART의 입력으로 사용
- 생성 방식 : 이전까지 생성된 토큰 시퀀스 $y_{1:i-1}$, 입력 $x$, 검색된 문서 $z$를 바탕으로 다음 토큰 $y_i$를 생성
BART에 대해 더 자세히 알고싶으신 분은 아래 글을 참고해주세요 !!
[논문리뷰] BART 논문 리뷰
자, 오늘은 X:AI Seminar 2024에서 진행한 BART 논문 리뷰를 가져왔습니다.해당 논문은 2019년에 발표된 논문입니다. NLP 모델계의 중추 역할을 담당하고 있는 BERT와 GPT-1 의 두 모델의 각각 문제점을 짚
dangingsu.tistory.com
학습 방식
RAG는 Retriever와 Generator를 함께 학습할 수 있도록 설계되어 있습니다.
다만, 어떤 문서를 검색해야 하는지에 대한 정답 라벨은 제공되지 않기 때문에, 잠재 변수 (latent variable)로 간주된 문서에 대해 margin을 줄이는 방식의 likelihood 최적화를 활용합니다.
- 목표 함수 : 학습 데이터셋의 (입력, 정답) 쌍 $x_j, y_j$에 대해

을 최소화합니다. 이 때 $p(y_j | x_j)$는 여러 문서에 대해 가중평균 계산된 확률입니다.
RAG에서 학습 대상은 문서 인코더, 쿼리 인코더, BART와 같이 3개 존재하는데 여기서 문서 인코더는 고정한 채로 나머지 2개만 학습시킵니다.
그 이유는 문서 인코더까지 업데이트할 경우 문서 인덱스를 매번 다시 구축해야 하므로 비용이 많이 드는데, 이를 생략해도 충분한 성능이 나온다고 저자들이 판단하여 인코더는 고정한 상태로 학습을 진행했다고 합니다.
디코딩 방식
추론 시점에서는 RAG-Token과 RAG-Sequence에 따라 디코딩 방식이 달라집니다.
1) RAG-Token Decoding
- 여러 문서 $z_i, ..., z_k$에 대해 다음 토큰 y_i의 확률을 개별적으로 계산하고 이를 가중합하여 최종 확률 도출

2) RAG-Sequence Decoding
- 문서 $z$마다 별도로 beam search를 수행하여 후보 문장 집합 $Y$를 구성
- 각 문장 $y$에 대해 등장하지 않은 문서 z에 대해서는 별도로 forward pass를 수행하여 확률을 계산하고, $p_ η(z|x)$와 곱한 뒤 모든 문서에 대해 합산
- 디코딩 방식 구분:
- Thorough Decoding : 모든 문서에 대해 완전한 forward pass 수행, 정확하지만 계산 비용이 큼
- Fast Decoding : beam search에서 생성되지 않은 후보는 확률이 0이라 가정해 계산량을 줄임
[3] Experiments & Results
본 논문의 모든 실험은 Wikipedia를 비파라메트릭(non-parametric) 데이터베이스 소스로 활용하여 진행되었습니다.
사용된 위키피디아 데이터는 2018년 12월 버전이고, 각 문서는 100 단어씩 분할하여 약 2,1000만 개의 문서 조각으로 구성됩니다.
각 문서 조각은 BERT 기반 문서 인코더를 통해 FAISS 라이브러리를 활용해 MIPS (Maximum Inner Product Search) 인덱스를 생성했다고 합니다.
이 때, 검색 속도를 개선하기 위해 HNSW (Hierarchical Navigable Small World) 구조를 활용했다고 합니다
학습 중에는 쿼리당 top-k 문서를 검색하며, k값은 5 or 10으로 설정하였고, 테스트 시에는 개발 세트를 기준으로 적절한 k를 선택했다고 합니다.
1) Open-domain Question Answering
오픈도메인 QA는 지식 기반 자연어처리의 대표적 응용 분야로, RAG는 이 Task에서 특히 두각을 나타냅니다.

- 문제 구성 : 질문과 정답을 입력-출력 쌍 (x, y)으로 보고, RAG는 정답을 직접 생성하도록 학습
- 비교 대상
- 추출기반 QA 모델 : 문서에서 정답을 "그대로 추출"하는 방식 (DPR, REALM)
- 폐쇄형 생성 모델 : 검색 없이 사전학습된 파라미터만으로 정답을 생성하는 방식 (T5)
- 사용된 데이터셋
- Natural Questions (NQ), TriviaQA (TQA), WebQuestions (WQ) 등등
- 평가 지표
- 정답 문자열이 정확히 일치하는 비율을 측정하는 Exact Match (EM) Score 사용
- 결과 요약
- RAG-Token과 RAG-Sequence 모델은 NQ, TQA, WQ 등 모든 데이터셋에서 기존 모델들 (REALM, DPR, T5-11B) 대비 가장 높은 정확도를 기록하며 새로운 SOTA 달성
- RAG는 사전학습된 DPR retriever 만으로도 re-ranker나 extractive reader 없이 강력한 성능을 보이며, 특히 TQA-Wiki에서는 RAG-Seq가 68의 정확도로 최고 성능을 달성
- RAG는 정답이 문서에 명시적으로 존재하지 않아도 단서를 활용해 응답을 생성할 수 있어, NQ에서 해당 경우에도 11.8%의 정확도를 보이며 추출 기반 모델의 한계 극복
2) Jeopardy Question Generation
RAG는 질의응답 (QA) 뿐만 아니라, 지식을 바탕으로 새로운 질문을 생성하는 작업에도 적용가능합니다.
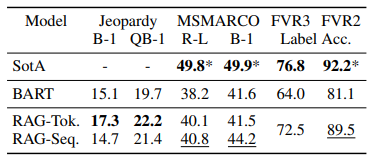

- 문제 구성 : 정답(Entity)을 주고 해당 정답에 맞는 질문을 생성하는 방식
- 비교 대상
- 폐쇄형 생성 모델 : 검색 없이 사전학습된 파라미터만으로 정답을 생성하는 방식 (BART)
- RAG 모델 : 외부 문서를 참조하며 질문을 생성하는 방식 (RAG-Token, RAG-Sequence)
- 사용된 데이터셋
- SearchQA Jeopardy dataset
- 평가 지표
- 정답 엔티티와의 일치에 더 높은 가중치를 부여하는 질문 생성 평가 지표 Q-BLEU-1 사용
- 사실성, 특수성 기준으로 Human Evaluation 병행
- 결과 요약
- RAG-Token은 Jeopardy 질문 생성에서 BART와 RAG-Sequence보다 더 높은 Q-BLEU-1 점수를 기록하며 가장 우수한 성능을 보임
- Human Evaluation 기준으로도 RAG-Token이 BART보다 더 사실적인 질문을 생성한 비율은 42.7%로 BART의 7.1%보다 압도적으로 높았음
- 여러 문서에서 정보를 결합해 질문을 생성하는 RAG-Token의 구조는 단서가 흩어진 복잡한 질문 형식에서도 강점을 가지며 구체적이고 신뢰도 높은 생성이 가능함을 입증
3) Fact Verification
뉴스, 검색, 사회적 논쟁 등 다양한 분야에서 특정 주장의 진위를 자동으로 판단할 수 있는 모델이 요구되고 있어 사실 검증 (Fact Verification) 은 점점 더 중요한 과제로 떠오르고 있습니다.
본 논문에서는 RAG로 분류 문제에 적용해도 충분히 효과적으로 적용할 수 있음을 보여주었습니다.

- 문제 구성 : 위키피디아 기반의 사실 검증 데이터셋 FEVER를 활용해 주어진 주장이 사실이다 / 사실이 아니다 / 불충분한 정보이다를 분류하는 작업을 수행
- 비교 대상
- 파이프라인 분류 모델 : 정답 증거 문장을 바탕으로 분류 (FEVER2, FEVER3)
- RAG 모델 : 외부 문서를 참조하며 질문을 생성하는 방식 (RAG-Token, RAG-Sequence)
- 폐쇄형 분류 모델 : 검색 없이 사전학습된 파라미터만으로 정답을 생성하는 방식 ( Thorne & Vlachos )
- 사용된 데이터셋
- FEVER (Fact Extraction and VERification)
- 평가 지표
- Label Accuracy : 정확도
- 검색 문서만 활용하며 정답 증거 문장 (gold evidence) 은 사용 X
- 결과 요약
- RAG는 retrieval supervision 없이도 SOTA에 근접한 정확도를 기록하며, 복잡한 아키텍쳐 없이도 충분히 효과적인 분류 모델로 활용가능함을 입증
- 특히 RAG-Token은 토큰 단위로 각기 다른 문서 정보를 활용할 수 있어 정보 조합의 유연성이 높고, 추론이 요구되는 사실 판단에 강점을 보임
- FEVER2, FEVER3에서 최고 성능을 보인 기존 모델들은 정답 문서가 제공되었기 때문에, RAG는 더 어려운 조건에서 실용적인 성능을 달성한 의의가 있음
[4] Conclusions
- RAG는 파라메트릭과 비파라메트릭 메모리를 결합하여 사실 기반 언어 생성을 실현한 하이브리드 생성 모델
- 다양한 지식 기반 NLP 태스크에서 기존 SOTA를 능가하는 성능을 입증했으며, 모델 재학습 없이도 지식 업데이트가 가능함
- 정확성과 유연성을 동시에 확보한 RAG는 교육, 의료, 검색 등 실용적인 분야로 확장될 가능성이 높지만, 동시에 책임 있는 활용이 요구됨
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] Alpaca 논문 리뷰 (8) | 2025.07.26 |
|---|---|
| [논문리뷰] CoT 논문 리뷰 (11) | 2025.07.22 |
| [논문리뷰] ChinChilla 논문 리뷰 (6) | 2025.07.15 |
| [논문리뷰] LoRA 논문 리뷰 (4) | 2025.07.08 |
| [논문리뷰] GAN 논문 리뷰 (0) | 2025.05.24 |
| [논문리뷰] VAE 논문 리뷰 (0) | 2025.02.17 |
| [논문리뷰] Mask R-CNN 논문 리뷰 (1) | 2025.02.17 |
| [논문리뷰] EfficientNet 논문리뷰 (3) | 2025.02.05 |



