728x90
오늘은 XL-Net 논문 리뷰를 가져왔습니다.

해당 논문은 2019년에 발표된 논문입니다.
XLNet: Generalized Autoregressive Pretraining for Language Understanding
저자 : Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
[1] Introduction
- 기존 언어 모델 Pre - training은 크게 AR과 AE로 나눌 수 있음
- Auto Regressive(AR)
- 이전 Token을 참고해 다음에 나올 Token이 무엇일지 예측
- 대표적으로 ELMO, GPT-1이 이에 해당함
- 주로 단 방향으로만 정보를 학습하기 때문에 양방향 문맥을 학습하지 못한다는 점에서 단점을 가짐
- Auto Encoding(AE)
- 주어진 input에 Masking 방식을 통해 noising하고 이 noising된 부분이 무엇인지 예측하는 방향으로 학습
- 주로 BERT가 이에 해당함
- 양방향 문맥을 학습할 수 있지만 Token들 사이의 의존성은 학습할 수 없으며 pre-training과 fine-tuning과의 불일치가 발생함
[논문리뷰] BART 논문 리뷰
자, 오늘은 X:AI Seminar 2024에서 진행한 BART 논문 리뷰를 가져왔습니다. 해당 논문은 2019년에 발표된 논문입니다. NLP 모델계의 중추 역할을 담당하고 있는 BERT와 GPT-1 의 두 모델의 각각 문제점을
dangingsu.tistory.com
[2] Proposed Method, XL-Net
- 1번에서 언급했던 AR, AE의 장점은 가져가고 단점을 극복하기 위해 등장한 모델이 XL-net, but 어떻게 극복했을까?
2-1) Permutation Language Modeling Objective
- 입력 Sequence의 순서의 모든 permutation(순열)을 고려한 AR 방식 사용
- [x1, x2, x3, x4]를 예측할 때, Zt = [[1,2,3,4], [1,2,4,3], [1,3,2,4], …]
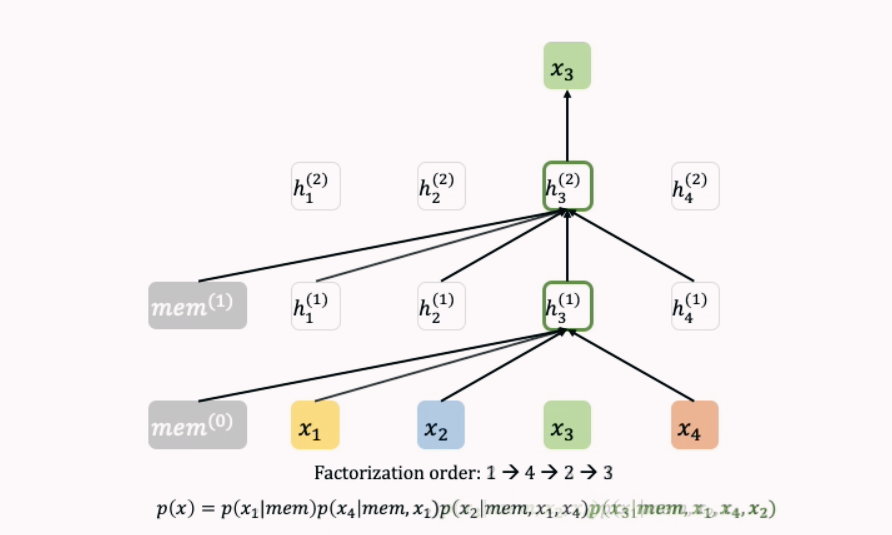
- 각 Token들은 원래 순서에 따라 Positional Encoding이 부여되기 때문에 모델은 x1 다음에 x2가 오는 것을, x2 다음에 x3가 오는 것을 학습 가능
- 순열을 모두 학습하기 때문에 양방향 context를 고려한 AR 방식으로 학습
- AR, AE의 단점은 극복, 장점은 가져가
- 하지만 이 방식에도 문제점이 존재하는데
- [2,3,1,4]의 경우 p(x1 | x2, x3)을 계산하기 위해 h(x2, x3)을 이용
- [2,3,4,1]의 경우 p(x1 | x2, x3)을 계산하기 위해 h(x2, x3)을 이용
- 결국 같은 representation을 이용해서 x1과 x4를 예측해야 되는 문제 발생
2-2) Two - Stream Self-Attention for Target Aware Representation

- 위의 문제를 해결하기 위해 새로운 방식의 Transformer 제안
- t 시점을 기준으로 두 Stream으로 분리

- 1) 위치 정보도 함께 학습
- 3 - 2 - 4 - 1 을 학습한다고 가정
- 3은 3 위치 정보 + mem1
- 2는 먼저 나온 3의 hidden vector + mem1 + 2의 위치 정보 ,,,

- 2) 기존 Transformer처럼 토큰 정보만 활용해서 학습
[3] Ideas from Transformer - XL
- XLNet은 긴 문장에 대한 처리를 위해 Transformer-XL (Dai et al., 2019)에서 사용된 2가지 테크닉을 차용 (Relative Positional Encoding, Segment Recurrence Mechanism)
- Relative Positional Encoding
- 두 개의 Sequence가 입력됐을 때 각각의 Token 순서를 [0,1,2,3], [4,5,6,7]이라고 가정, 두 Sequence가 나란히 입력되었으면 모델은 [0,1,2,3,4,5,6,7]이라고 학습해야 하지만 [0,1,2,3,0,1,2,3]으로 순서에 대한 학습을 할 수 있다는 문제 발생

-
- 따라서 위 사진과 같이 변환
- (a) : Content 기반 처리
- (b) : Content에 의존한 Positional bias
- (c) : Global Content bias
- (d) : Global Positional bias
- 따라서 위 사진과 같이 변환
- Segment Recurrence Mechanism
- 두 Segment로 분리해서 과거 Segment의 순서를 고려하지 못하도록 독립적으로 계산
[4] Modeling
- Pre - training
- BERT와 유사하게 A, SEP, B, SEP, CLS로 입력
- Seg A, B를 랜덤으로 샘플링하고 하나로 concat해 permutation 수행
- XL-net-Large는 NSP의 효과가 없어서 사용 X
- Permutation 집합에서 하나의 Token을 예측할 때 마지막 K개의 예측만 사용함 (base 모델에서는 K = 6)
[5] Results
1) RACE Dataset
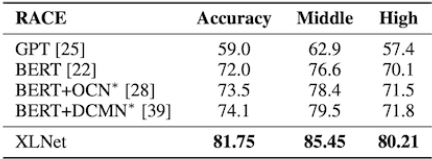
- Resoning에 대한 질문을 포함하는 가장 어려운 QA dataset 중 하나
- Sequence length를 640으로 fine-tuning 시켜 수행
2) SQuAD Dataset
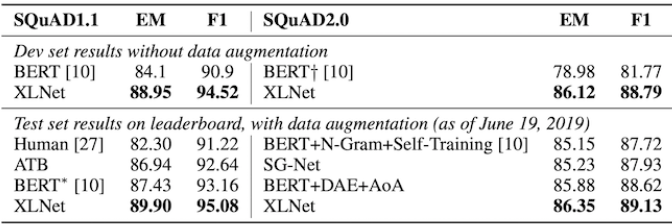
- SQuAD dataset에서도 꽤 큰 격차로 SOTA 달성
- 문장의 길이가 비교적 긴 Task라서 더욱 그렇지 않았나 싶음
3) GLUE Dataset
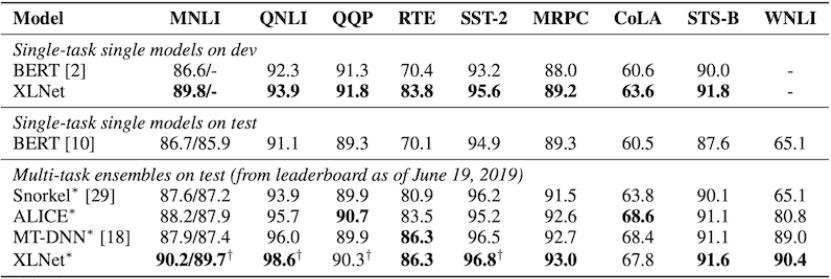
- 전체 9개의 Task 중 7개에서 SOTA 달성
[6] Conclusion
- XL-net은 AE + AR 의 단점을 보완하고 장점은 보존한 언어 모델
- Pre-training 단계에서 permutation을 활용해 학습
- 이로 인해 생기는 문제를 새로운 방식의 Transformer를 제시해 해결
- Transformer-XL에서 아이디어를 얻음 (같은 저자)
[7] Reference
https://arxiv.org/abs/1906.08237
https://youtu.be/v7diENO2mEA?si=zEH5MFi0IeobD6Du
https://jeonsworld.github.io/NLP/xlnet/
[논문리뷰] BERT 논문 리뷰
자, 오늘은 X:AI Seminar 2024에서 진행한 BERT 논문 리뷰를 가져왔습니다.해당 논문은 2019년에 발표되어 ELMO, GPT-1의 모델과 비교를 하면서 얘기를 시사하고 있습니다. 논문 : BERT, Pre-training of Deep Bidire
dangingsu.tistory.com
728x90
반응형
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] FILIP 논문 리뷰 (5) | 2024.07.23 |
|---|---|
| [논문리뷰] ALBEF 논문 리뷰 (2) | 2024.07.17 |
| [논문리뷰] T5 논문 리뷰 (0) | 2024.07.15 |
| [논문리뷰] CLIP 논문 리뷰 (0) | 2024.07.10 |
| [논문리뷰] Transformer 논문 리뷰 (0) | 2024.06.26 |
| [논문리뷰] MT-DNN 논문 리뷰 (0) | 2024.05.23 |
| [논문리뷰] BART 논문 리뷰 (2) | 2024.05.15 |
| [논문리뷰] BERT 논문 리뷰 (0) | 2024.04.30 |



